







对于二维数据集,可以在xy平面上画出所有可能的测试点的预测结果,根据平面中的每个点所属的类别对平面进行角色,可以查看决策边界,也就是算法对类别0和类别1的分界线。
对1、3、9个邻居三种情况的决策边界可视化:
import mglearn.datasets
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
X,y=mglearn.datasets.make_forge()
fig,axes=plt.subplots(1,3,figsize=(10,3))
for n_neighbors,ax in zip([1,3,9],axes):
clf=KNeighborsClassifier(n_neighbors=n_neighbors).fit(X,y)
mglearn.plots.plot_2d_classification(clf,X,fill=True,eps=0.5,ax=ax,alpha=.4)
mglearn.discrete_scatter(X[:,0],X[:,1],y,ax=ax)
ax.set_title('{} neighbor(s)'.format(n_neighbors))
ax.set_xlabel('feature 0')
ax.set_ylabel('feature 1')
axes[0].legend(loc=3)
plt.show()
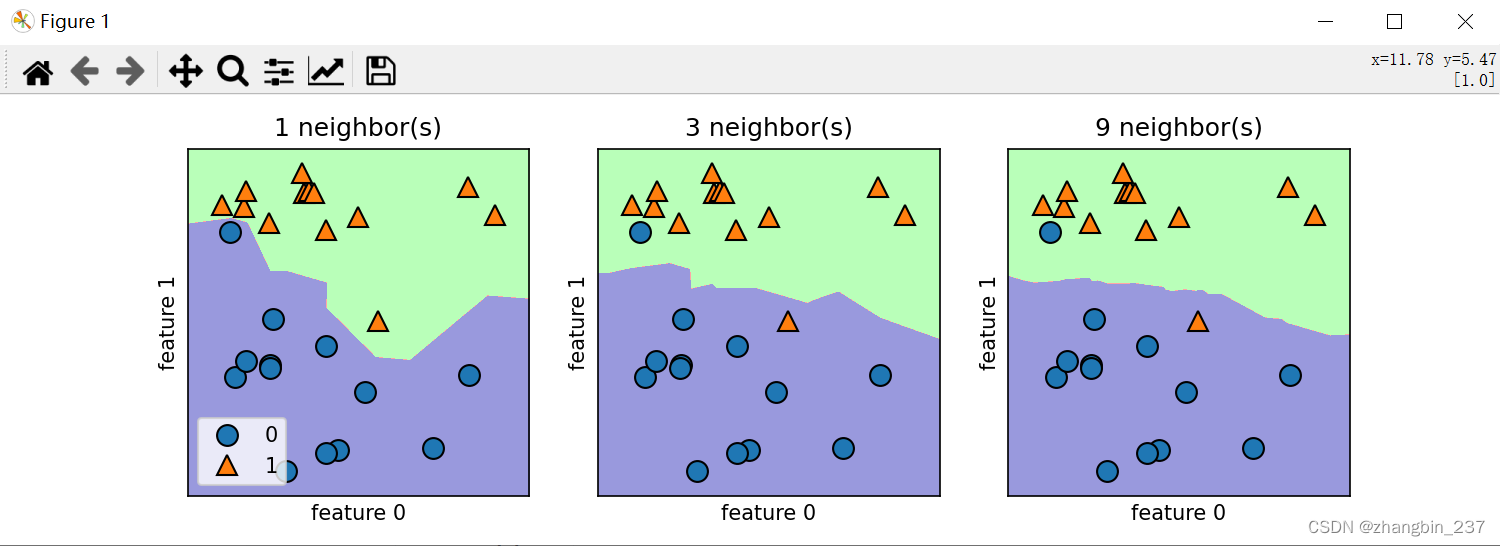
可以看到,使用单一邻居绘制的决策边界紧跟训练数据,邻居个数越多决策边界越平滑。














 88
88











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









