







虽然PCA通常是用于变换数据的首选方法,使你能够用散点图将其可视化,但这一方法的性质限制了其有效性。
有一类用于可视化的算法叫做流形学习算法,它允许进行更复杂的映射,通常也可以给出更好的可视化。其中特别有用的一个就是t-SNE算法。
流形学习算法主要用于可视化,因此很少用来生成两个以上的新特征。其中一些算法计算训练数据的一种新表示,但不允许变换新数据。这意味着这些算法不能用于测试集:更确切的说,他们只能变换用于训练的数据。流形学习对探索性数据分析是很有用的,但如果最终目标是监督学习的话,则很少使用。t-SNE背后的思想是找到数据的一个二维表示,尽可能地保持数据点之间的距离。t-SNE首先给出每个数据点的随机二维表示,然后尝试让在原始特征空间中距离较近的点更加靠近,原始特征空间中相距较远的点更加远离。t-SNE重点关注距离较近的点,而不是保持距离较远的点之间的距离,换句话说,它试图保存那些表示哪些点比较靠近的信息。
对scikit-learn包含的一个手写数字数据集应用t-SNE流形学习算法。
在这个数据集中,每个数据点都是0到9之间手写数字的一张8*8灰度图像。
from sklearn.datasets import load_digits
import matplotlib.pyplot as plt
digits=load_digits()
fig,axes=plt.subplots(2,5,figsize=(10,5),subplot_kw={'xticks':(),'yticks':()})
for ax,img in zip(axes.ravel(),digits.images):
ax.imshow(img)
plt.show()
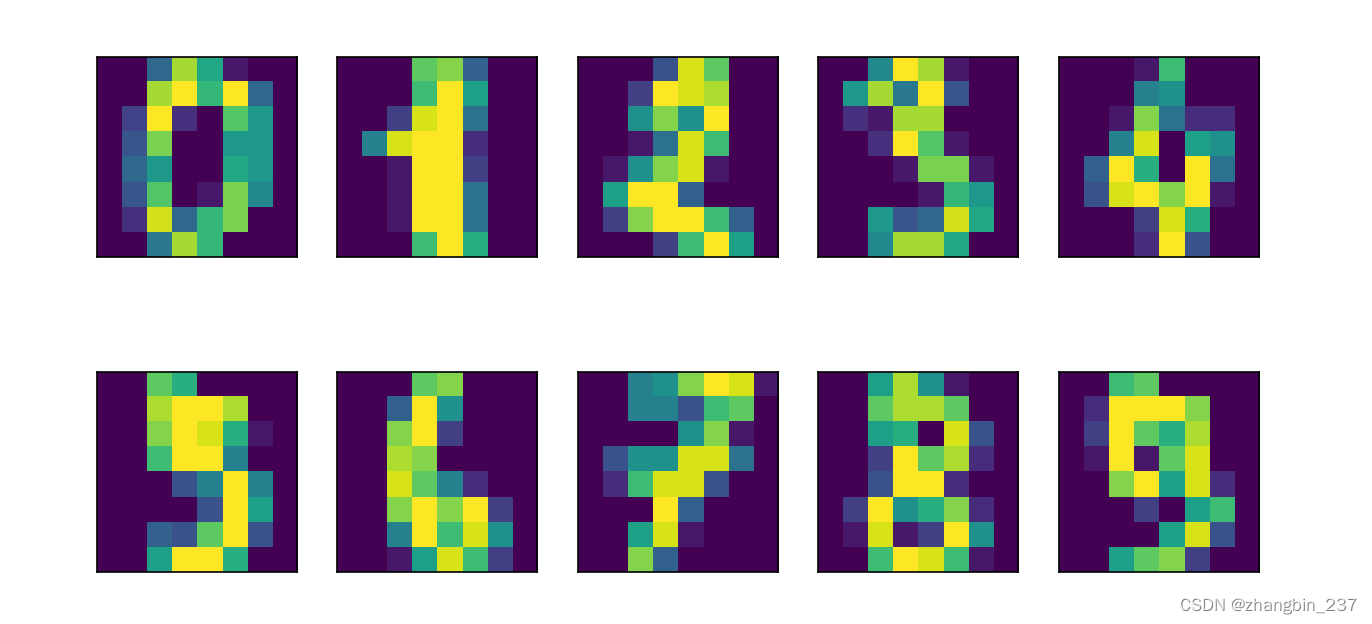
用PCA将降到二维的数据可视化,我们对前两个主成分作图,并按类别对数据点着色:
from sklearn.datasets import load_digits
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import NMF,PCA
digits=load_digits()
pca=PCA(n_components=2)
pca.fit(digits.data)
digits_pca=pca.transform(digits.data)
colors=['#476A2A','#7851B8','#BD3430','#4A2D4E','#875525',
'#A83683','#4E655E','#853541','#3A3120','#535D8E']
plt.figure(figsize=(10,10))
plt.xlim(digits_pca[:,0].min(),digits_pca[:,0].max())
plt.ylim(digits_pca[:,1].min(),digits_pca[:,1].max())
for i in range(len(digits_pca)):
plt.text(digits_pca[i,0],digits_pca[i,1],str(digits.target[i]),
color=colors[digits.target[i]],
fontdict={'weight':'bold','size':9})
plt.xlabel('first')
plt.ylabel('second')
plt.show()
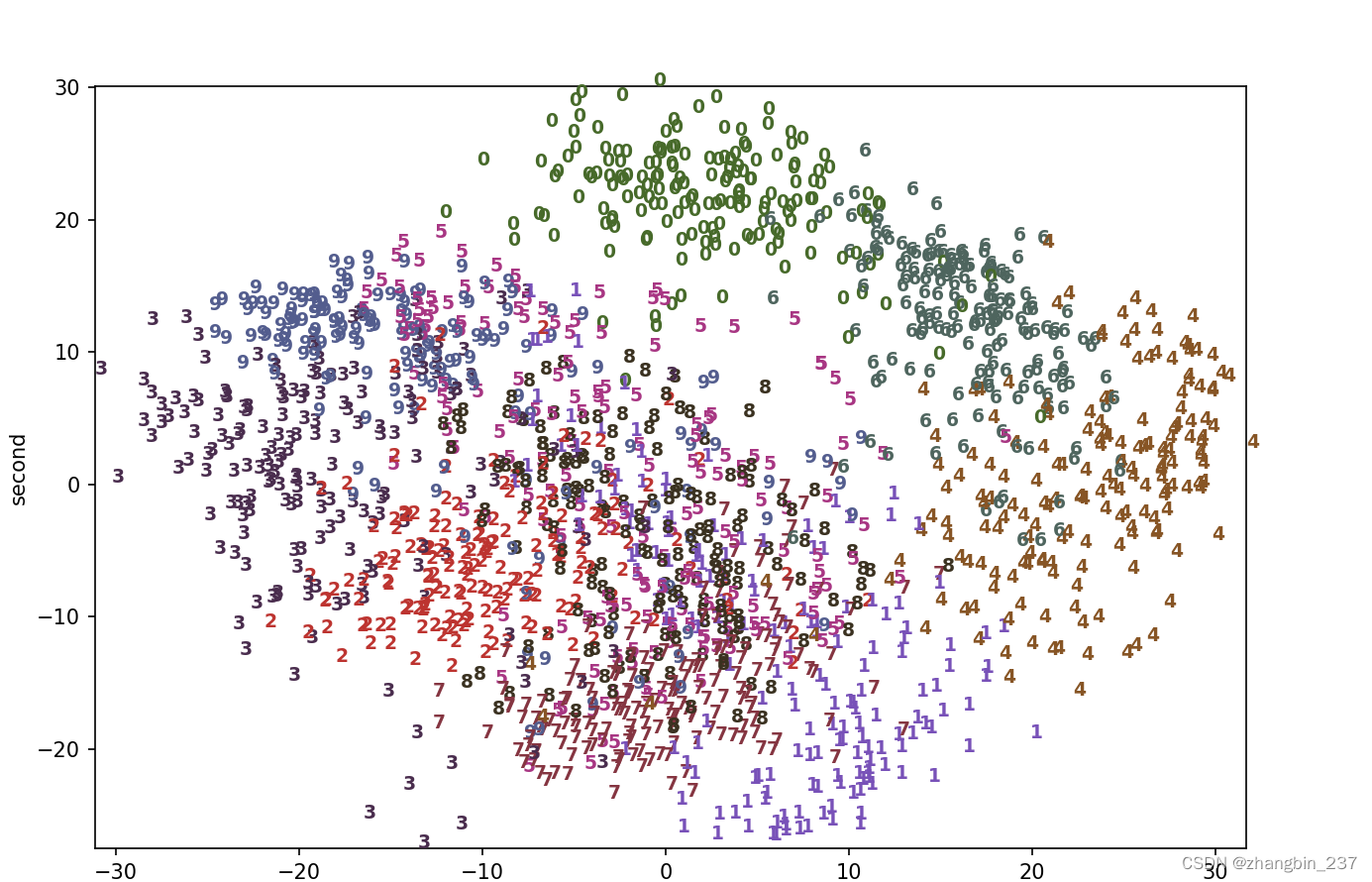
实际上,这里我们用每个类别对应的数字作为符号来显示每个类别的位置。利用前两个主成分可以将数字0、4、6相对较好的分开,尽管仍有重叠。但部分其他数字都大量重叠在一起。
将t-SNE应用于同一个数据集,并对结果进行比较。由于s-SNE不支持变换新数据,所以tsne类没有transform方法,我们可以调用fit_transform方法来代替,它会构建模型并立刻返回变换后的数据:
from sklearn.datasets import load_digits
import numpy as np
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
digits=load_digits()
tsne=TSNE(random_state=42)
digits_tsne=tsne.fit_transform(digits.data)
colors=['#476A2A','#7851B8','#BD3430','#4A2D4E','#875525',
'#A83683','#4E655E','#853541','#3A3120','#535D8E']
plt.figure(figsize=(10,10))
plt.xlim(digits_tsne[:,0].min(),digits_tsne[:,0].max()+1)
plt.ylim(digits_tsne[:,1].min(),digits_tsne[:,1].max()+1)
for i in range(len(digits_tsne)):
plt.text(digits_tsne[i,0],digits_tsne[i,1],str(digits.target[i]),
color=colors[digits.target[i]],
fontdict={'weight':'bold','size':9})
plt.xlabel('t-SNE feature 0')
plt.ylabel('t-SNE feature 1')
plt.show()
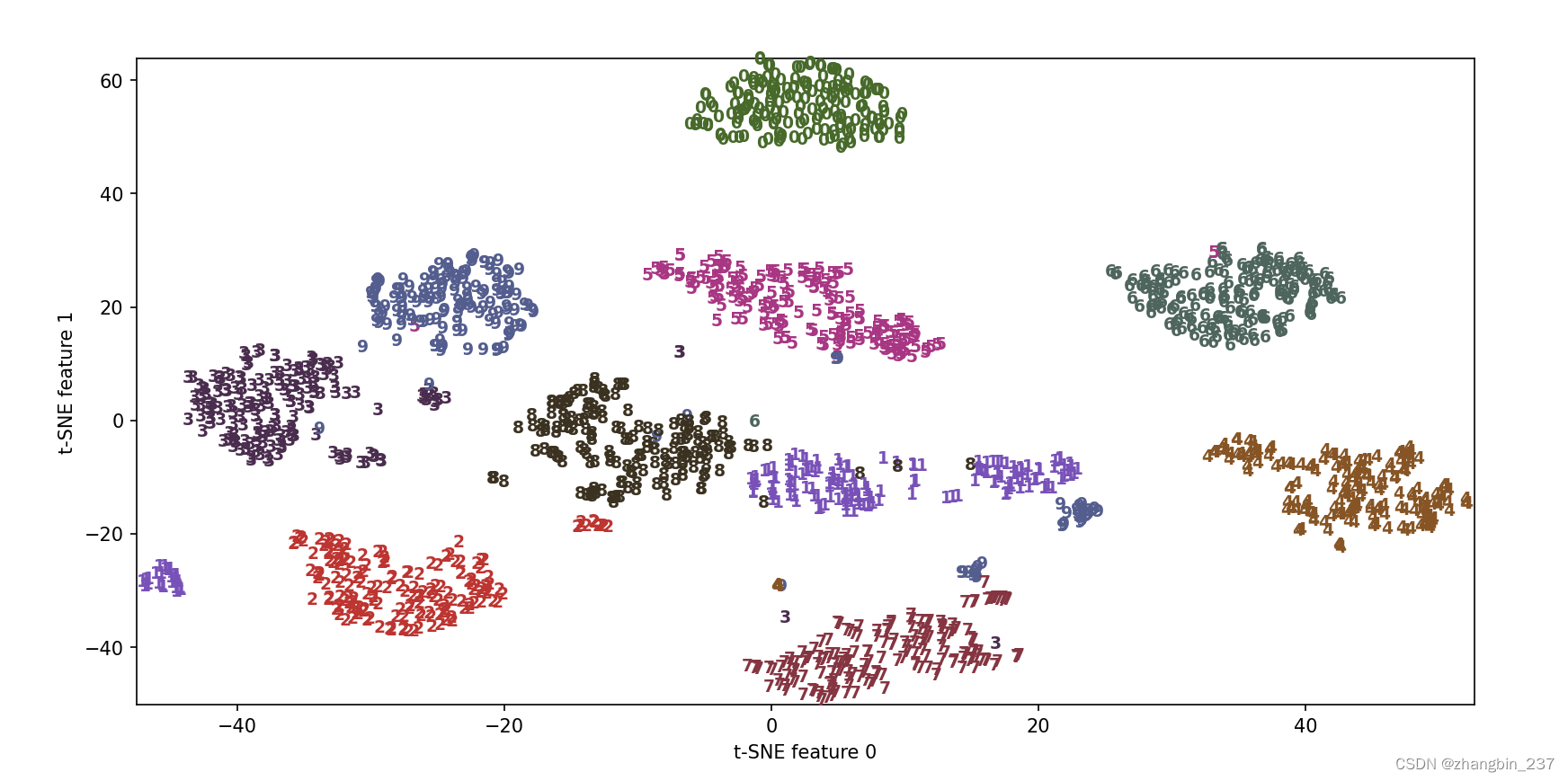
可以看到,t-SNE的结果非常棒,所有类别都被明确分开,数字1、9被分成几块,但大多数类别都形成一个密集的组。要知道,这种方法并不知道类别标签,它完全是无监督的。但它能够找到数据的一种二维表示,仅根据原始空间中数据点之间的靠近程度就能够将各个类别明确分开。
t-SNE算法有一些调节参数,虽然默认参数的效果通常就非常好。















 719
719











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









