







t-SNE
t-SNE(t-Distributed Stochastic Neighbor Embedding,t 分布随机邻域嵌入)是一种将高维的复杂数据降维为二维(或三维)的算法,用于低维空间的可视化。
在降维时,t-SNE 会将类似结构的数据聚集在一起,这有助于我们理解数据的结构。
概述
t-SNE 是一种流形学习算法,用于实现复杂数据的可视化。我们可以通过将高维数据降维为二维或三维来实现可视化。图 3-29 所示为利用 t-SNE 将数据从三维空间降维到二维空间的示例。原始数据是三维空间上的两个瑞士卷数据(图 3-29a),二者的区别可以从经过降维后显示在二维空间中的图形看出(图 3-29b)。
▲图 3-29 使用 t-SNE 降维
如上所示,t-SNE 具有在低维空间巧妙表现多个结构的机制。
t-SNE 的特点是在降维时使用了自由度为 1 的 t 分布。通过 t 分布,可以使在高维空间中原本很近的结构在低维空间中变得更近,原本较远的结构变得更远。下面的“算法说明”及其后的内容将对此进行详细介绍。
算法说明
t-SNE 算法的步骤如下。
- 对于所有的组 i、j,使用高斯分布来表示 xi 和 xj 的相似度。
- 在低维空间中随机配置与 xi 相同数量的点 yi,对于所有的组 i、j,使用 t 分布表示 yi 和 yj 的相似度。
- 更新数据点 yj,使得步骤 1 和步骤 2 中定义的相似度分布尽可能相似。
- 重复步骤 3,直到达到收敛条件。
下面介绍步骤 1 和步骤 2 中出现的相似度。相似度是衡量数据点之间的相似程度的概念。它不是简单地使用数据之间的距离,而是使用如图 3-30 所示的概率分布来衡量的。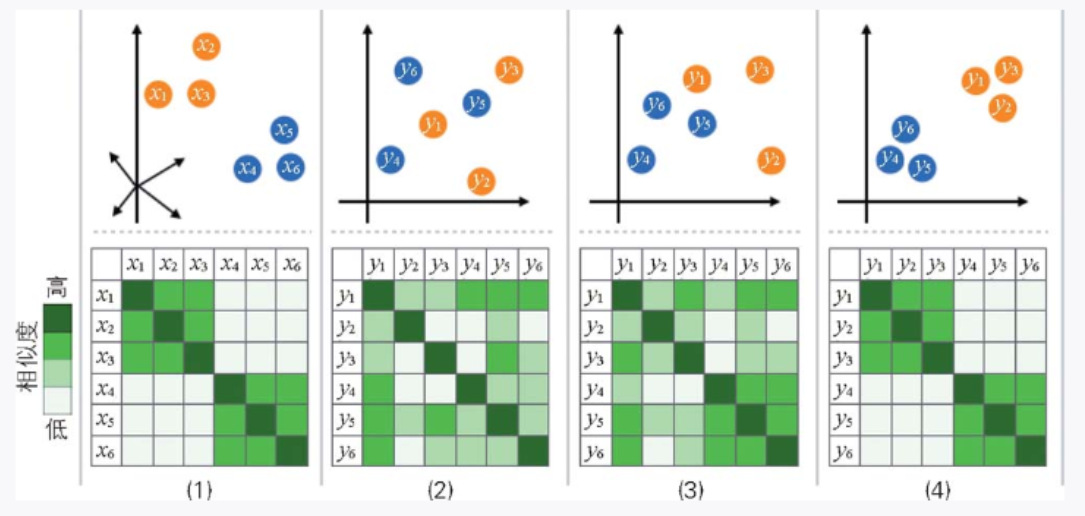
▲图 3-30 t-SNE 算法示意图
在图 3-31 中,横轴是距离,纵轴是相似度。从图中可以看出,数据之间的距离越近,相似度越高;距离越远,相似度越低。我们首先在原来的高维空间中用高斯分布计算相似度,以 pij 这个分布表示。这个 pij 表示数据点 xi 和 xj 之间的相似度。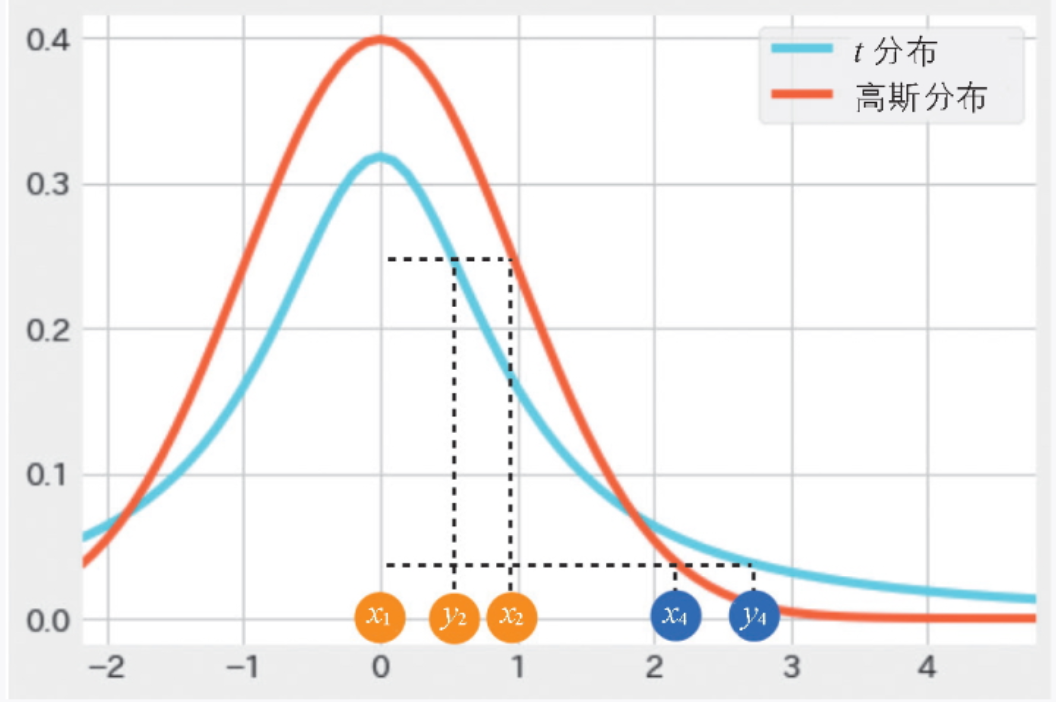
▲图 3-31 t 分布和高斯分布
接下来,在低维空间中随机配置与 xi 对应的数据点 yi。我们也对这个数据点计算表示相似度的 qij,不过这时使用的是 t 分布。
在计算出 pij 和 qij 之后,我们来更新数据点 yi,使 qij 具有与 pij 相同的分布,这样就能够以低维空间的 yj 再现高维空间中各 xi 的相似度的关系。由于这时在低维空间使用的是 t 分布,所以可以看到,当再现大的相似度时,数据点在低维空间中配置的距离更近;反之,当再现小的相似度时,数据点在低维空间中配置的距离更远。
在将 t-SNE 应用于前面提到的瑞士卷数据时,数据点 yj 的更新情况如图 3-32 所示。从图中可以看出,随着更新次数的增加,数据点的差异逐渐展现了出来。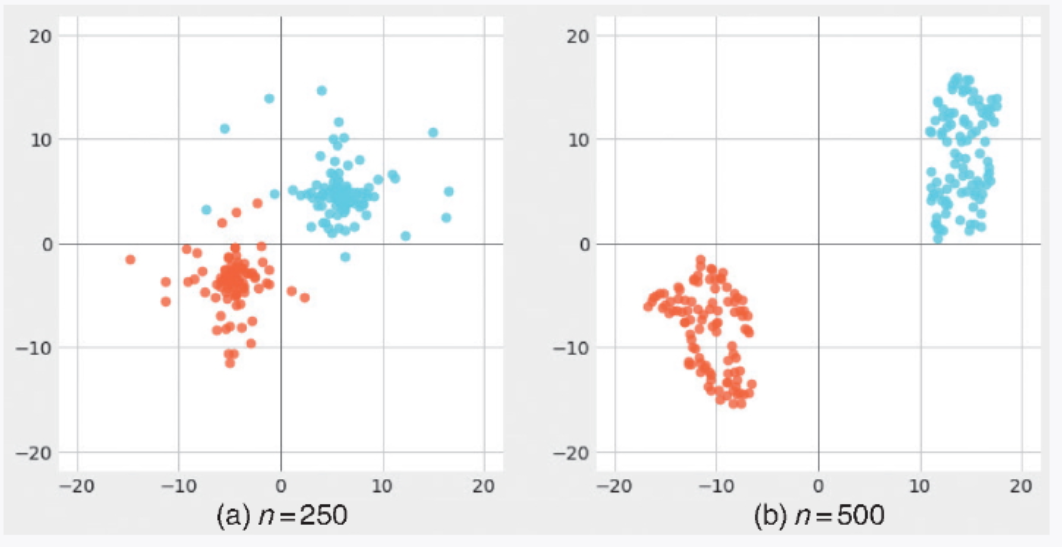
▲图 3-32 数据点的更新情况((a) 中的更新次数为 250 次,(b) 中为 500 次)
“概述”部分提到 t-SNE 基本上被用于将数据降维到三维或二维的场景。由于t 分布是重尾分布,所以在高维空间中,远离中心的区域占主导地位,局部信息将无法保留。因此,有时无法降维到四维或更高维度的空间。
示例代码
下面是将 t-SNE 应用于手写数字数据集的代码,其中设置的降维后的维度是 2。
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.manifold import TSNE
# 加载手写数字数据集
data = load_digits()
# 设置t-SNE模型参数
n_components = 2 # 降维到2个组件
perplexity = 30 # t-SNE中的困惑度参数
n_iter = 1000 # 迭代次数
random_state = 42 # 随机种子保证结果可复现
# 创建t-SNE模型
model = TSNE(n_components=n_components, perplexity=perplexity, n_iter=n_iter, random_state=random_state)
# 拟合并转换数据
transformed_data = model.fit_transform(data.data)
# 打印原始数据和降维后的数据
print(data)
print("*******************3d to 2d*******************")
print(transformed_data)
# 创建子图
fig, ax = plt.subplots(1, 2, figsize=(20, 8))
# 可视化原始的高维数据(这里使用前两个主成分进行可视化,虽然实际维度是64)
scatter1 = ax[0].scatter(data.data[:, 0], data.data[:, 1], c=data.target, cmap='viridis', s=50)
ax[0].set_title('Original High-Dimensional Data (First Two Dimensions)')
ax[0].set_xlabel('Original Component 1')
ax[0].set_ylabel('Original Component 2')
fig.colorbar(scatter1, ax=ax[0])
# 可视化降维后的数据
scatter2 = ax[1].scatter(transformed_data[:, 0], transformed_data[:, 1], c=data.target, cmap='viridis', s=50)
ax[1].set_title('t-SNE visualization of Digits dataset')
ax[1].set_xlabel('Component 1')
ax[1].set_ylabel('Component 2')
fig.colorbar(scatter2, ax=ax[1])
# 显示图像
plt.show()结果:

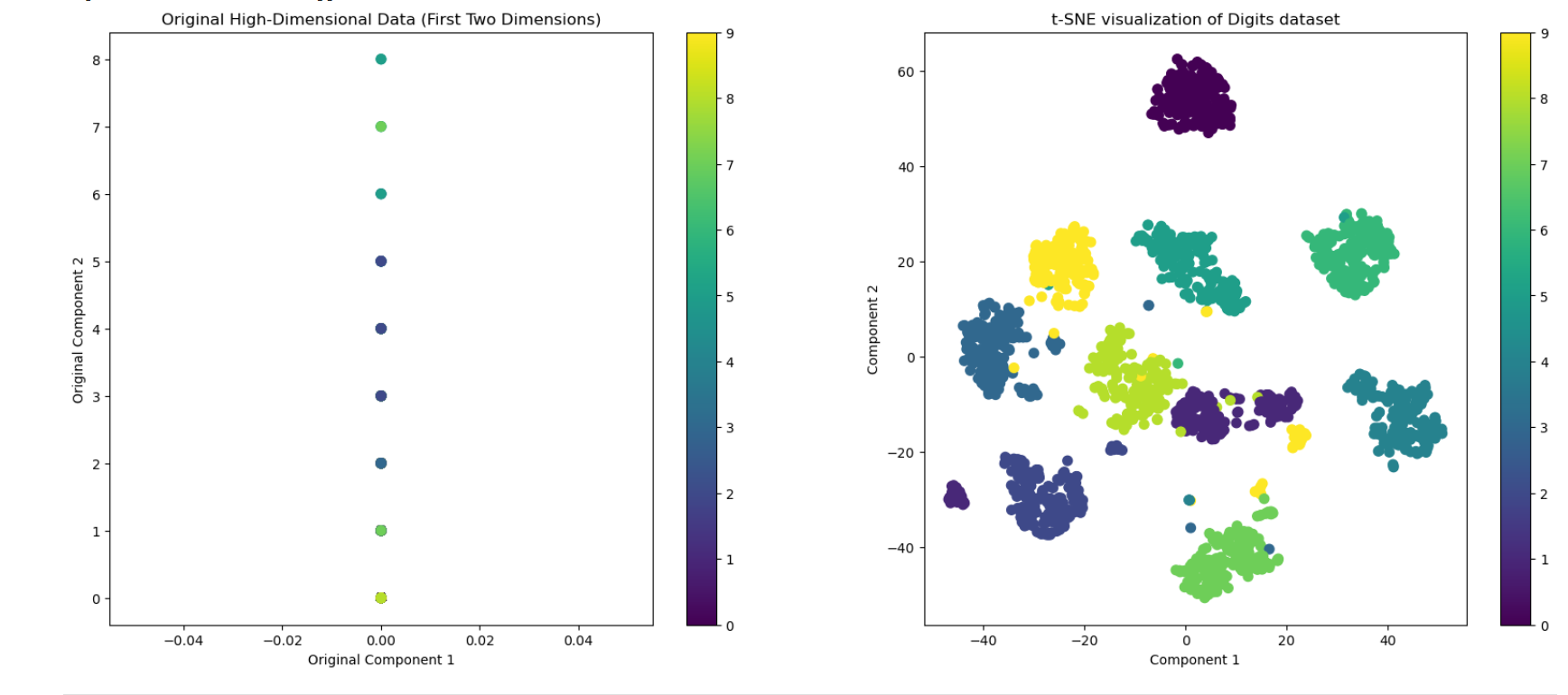
详细说明
与其他降维算法的比较
下面将 t-SNE 与其他降维算法进行比较,来研究它的特点。我们使用的数据是如图 3-33 所示的手写数字。
▲图 3-33 手写数字
手写数字是 8 像素× 8 像素的图像数据,每个图像中的数字是 0, 1, 2,…, 9 其中之一。换言之,我们可以认为它是一个包含了 10 种不同结构的 8 × 8(= 64)维空间。
下面使用 PCA、LLE 和 t-SNE 这 3 种算法对手写数字数据进行降维(图 3-34)。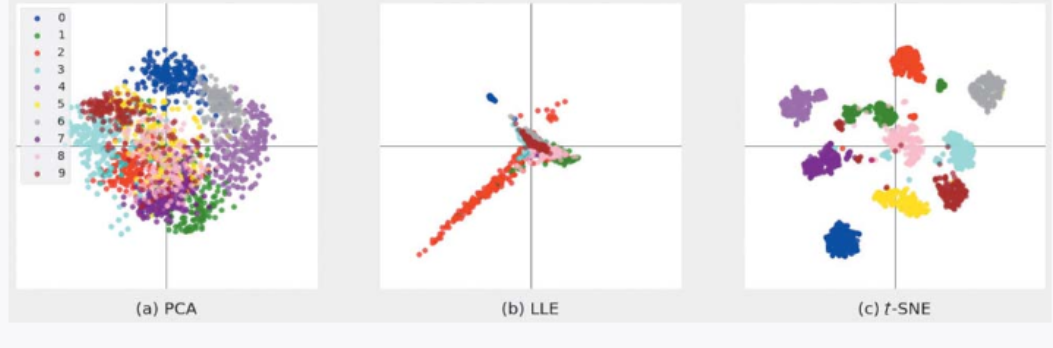 ▲图 3-34 PCA、LLE 和 t-SNE 的比较
▲图 3-34 PCA、LLE 和 t-SNE 的比较
从图中可以看出,图 3-34a 中的 PCA 虽然在一定程度上按数值进行了归类,但每部分依然混杂着不同的数值;图 3-34b 中的 LLE 虽然适用于非线性数据,但如果数据集不像瑞士卷数据集那样数据点聚在一起,我们就不能很好地把握其结构;而图 3-34c 中的 t-SNE 在二维空间中将数据按值归类,很好地对结构完成了分类。
———————————————————————————————————————————
文章来源:书籍《图解机器学习算法》
作者:秋庭伸也 杉山阿圣 寺田学
出版社:人民邮电出版社
ISBN:9787115563569
本篇文章仅用于学习和研究目的,不会用于任何商业用途。引用书籍《图解机器学习算法》的内容旨在分享知识和启发思考,尊重原著作者秋庭伸也 杉山阿圣 寺田学的知识产权。如有侵权或者版权纠纷,请及时联系作者。
—————————————————————————————————————————

















 1448
1448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









