







行人重识别之属性信息
In-depth exploration of attribute information for person re-identification
这次分享一篇自己的文章,这篇文章针对了行人的属性信息。
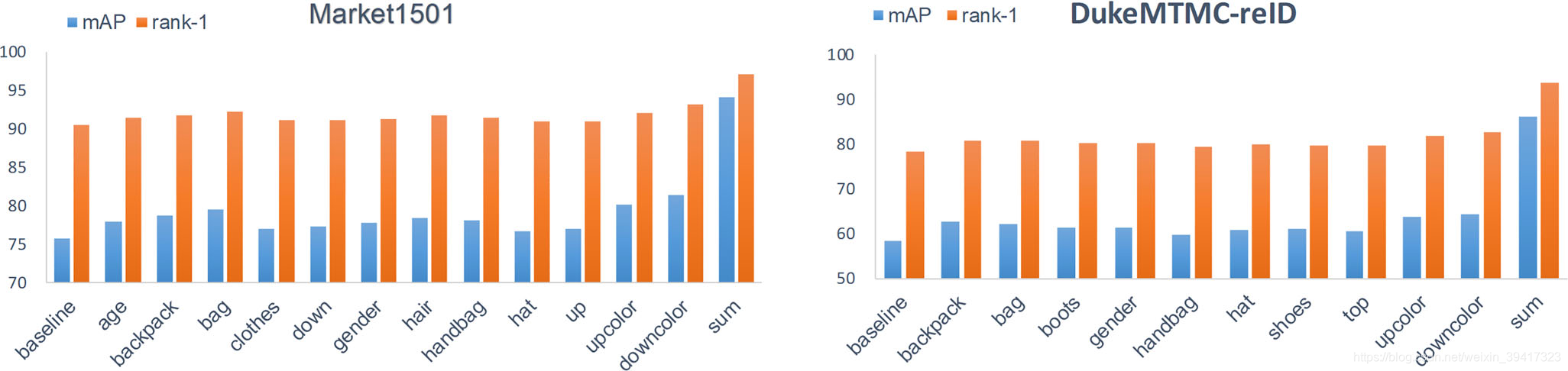
首先,我定量分析了属性信息的重要性。
假设,我们已知某一类的属性标签,用该标签直接辅助baseline进行识别。
如下图,性能都会有不小的提高。
进一步,我使用所有类别的属性(图中的sum)对baseline进行辅助。
可以看出,模型的精度大幅提升。
这证明了属性信息有很大的价值。
所以,正如标题所言,本文的主要内容是研究如何充分利用属性信息。
先介绍一下主体框架:
如下图,蓝色部分IRN负责识别行人身份,可以理解为baseline
红色部分ARN负责识别行人属性,作为辅助
ARN中有多个网络,每一个网络负责一类属性的识别
假如有N个属性,那么算上IRN,总共就有N+1个识别网络
最后,根据每个网络得到的特征的欧氏距离Mat,进行加权相加,得到最终的结果
框架非常简单,下文主要介绍一些细节,对于大家或许有帮助。

hard pair loss
如下图,两个身份不同,但是属性全部一致的两个人非常相似
我们视其为hard pair
在网络中对hard pair的相似度进行惩罚,迫使网络能够提取更高级的语义特征
从而通过这一个点提高模型的鲁棒性

loss公式如下,其实和triplet loss是一样的,只不过样本不同。
其中xa、xb是一个hard pair,x和xa是同一个身份。
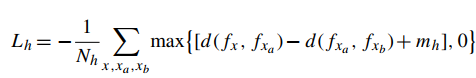
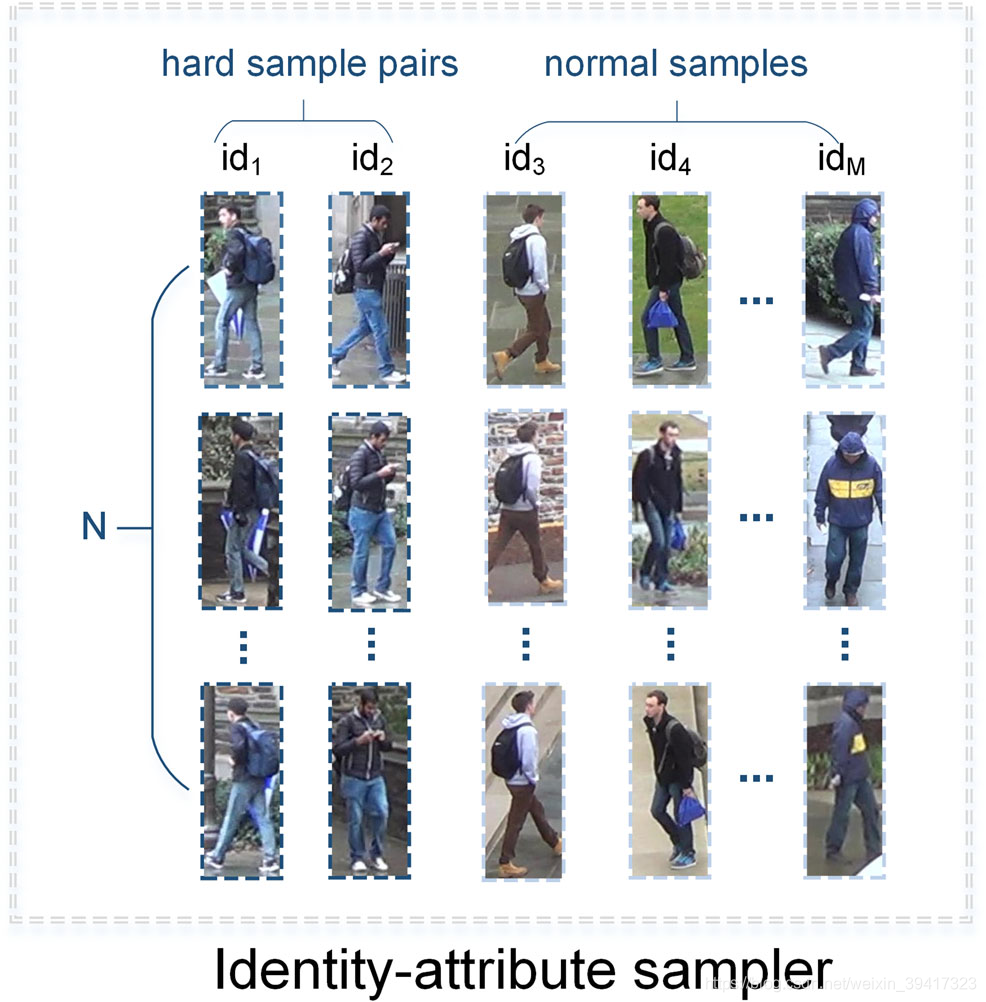
采样器
可以想到,hard pair是比较少的
如果随机采样,很难每个batch size都有hard pair
于是提出了如下采样器:
batchsize=M*N
采集M个身份,每个身份N个样本,保证其中2个身份是hard pair
那么根据排列组合,一个batchsize中会有N^2个hard pair
这样增强了hard pair loss的作用
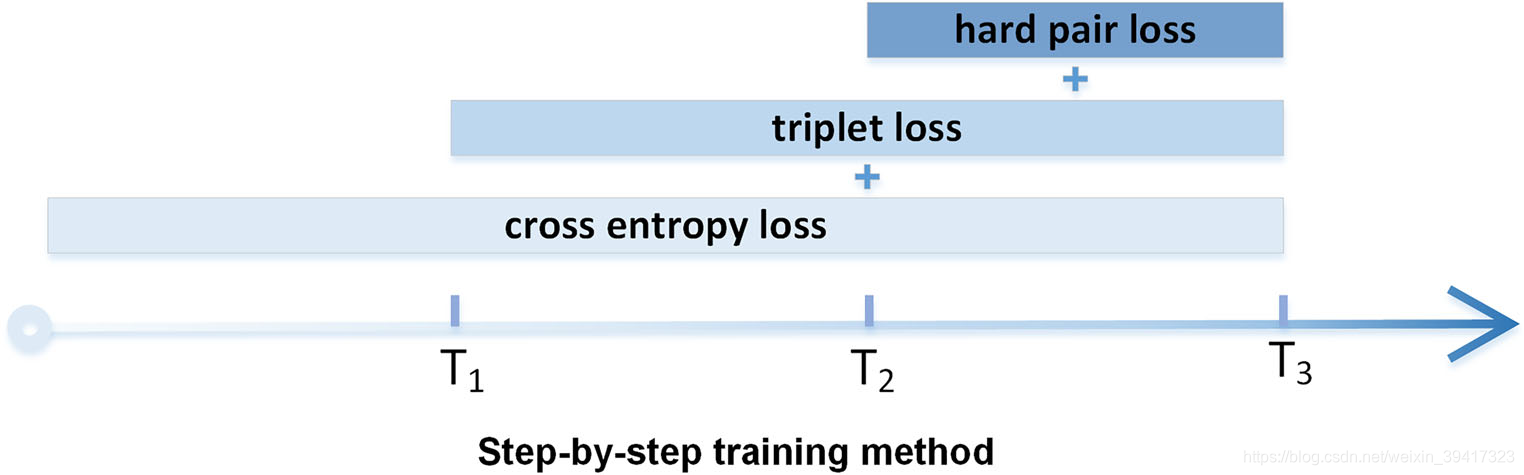
训练方法
baseline一般都是先在imagenet上进行预训练
所以我们做行人重识别从某种角度上也是将模型从一个域(imagenet)迁移到另一个域(行人数据库)
对于预训练模型,直接对它进行triplet loss 和 hard pair loss进行训练,是否拔苗助长呢?
所以,我选择慢慢来,具体如下图:
在训练过程中,先用简单的损失函数,再一点点加难的损失函数,有利于模型的训练。
关于ARN
为何不直接使用模型识别出的属性标签而使用提取的特征呢?
如下,因为属性识别的精度不高
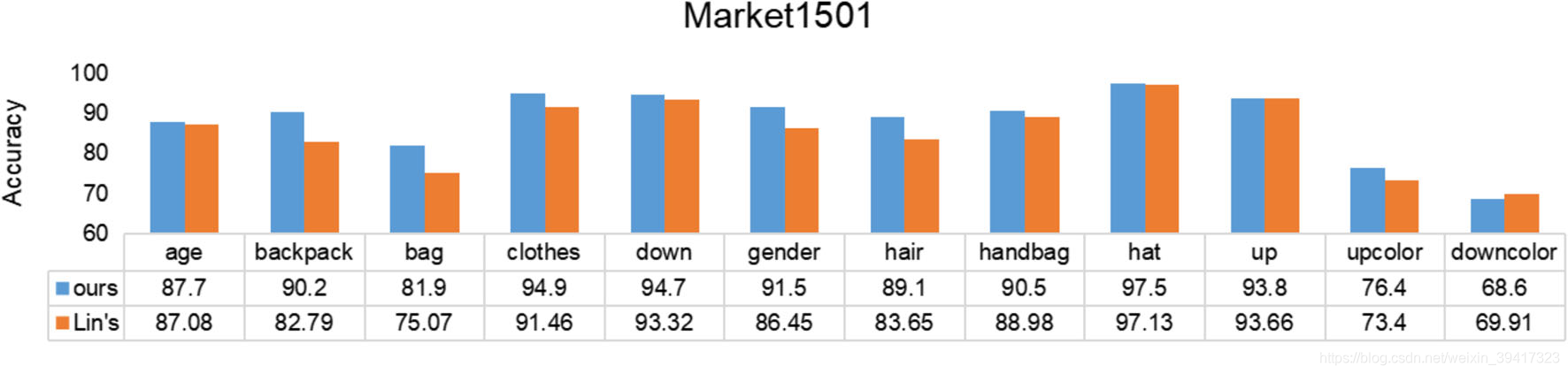
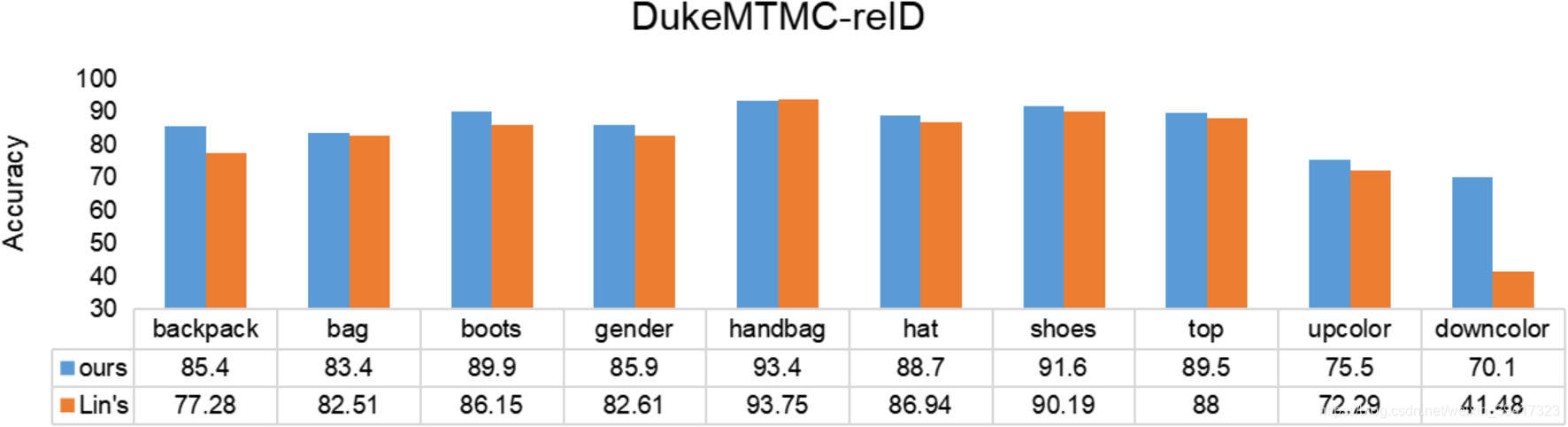
识别精度不高有如下原因:
属性标签本身标的就不是很准
相同属性之间也会差异很大,后文会提到
同一类属性,数据量差异巨大,如下图
有些属性直接被遮挡了,很难识别
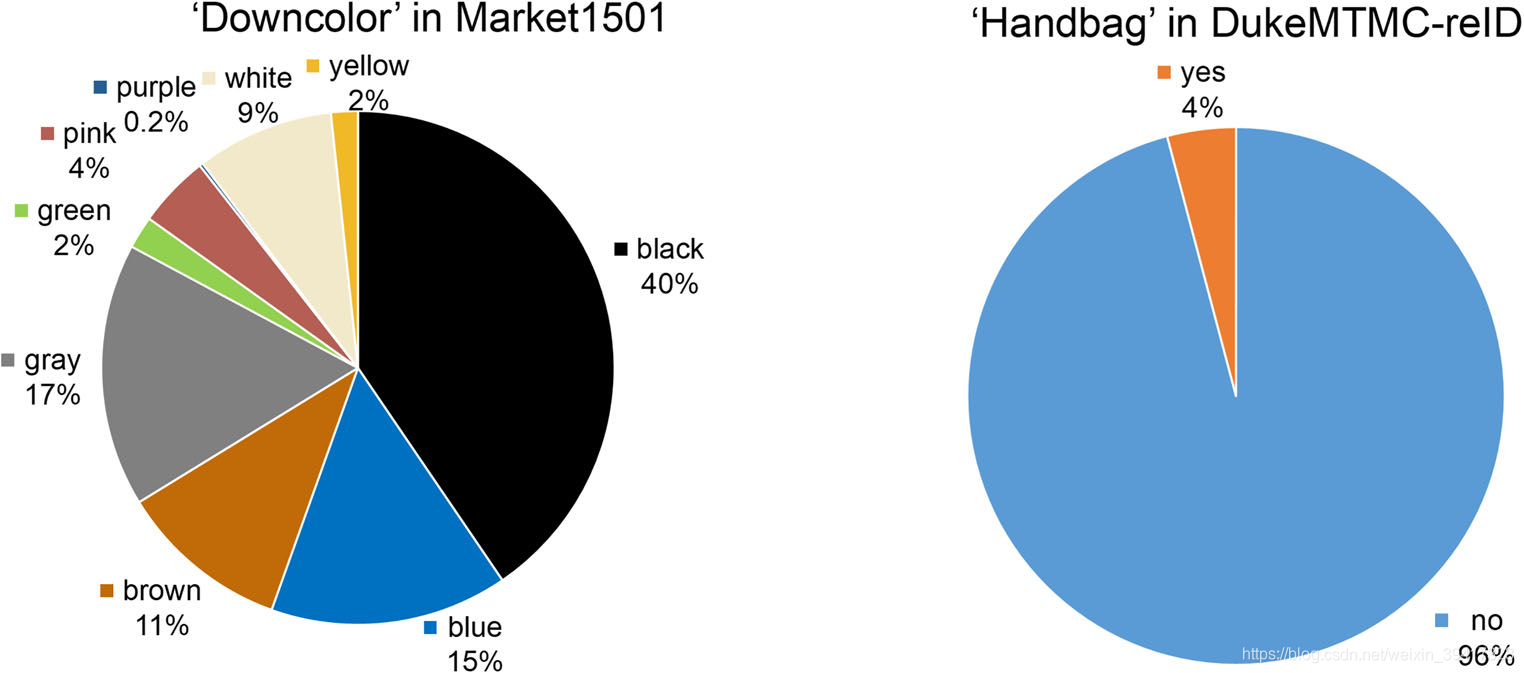
所以,使用了各类属性的特征向量
再与IRN中的特征向量加权相加
ARN中的triplet loss
如下图,同一类属性的差别其实非常大的
这也是属性识别准确率不高的原因
强行将如下所示的属性识别为一类,很难,也没必要
所以在ARN的triplet loss中,positive pair必须满足如下条件:
属性相同且是同一个人
这样,positive pair的属性才会具有很高的相似性,网络才能真正学到东西

最后,上两张效果图


总结:希望文中的tricks能够帮助到大家。
完
欢迎讨论 欢迎吐槽














 5337
5337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









