







行人重识别之泛化能力
Distilled Person Re-identification: Towards a More Scalable System
原文链接:http://openaccess.thecvf.com/content_CVPR_2019/papers/Wu_Distilled_Person_Re-Identification_Towards_a_More_Scalable_System_CVPR_2019_paper.pdf
如题所示,本文主要为了提升行人重识别的泛化能力,也可以说是应用性。具体从3个方面入手,作者总结的很到位:
- 降低标签成本(减少标签的需求量)
- 降低跨数据库成本(利用一些先验知识)
- 降低测试成本(使用轻量级网络)
这篇文章的数学公式较多,喜欢数学的朋友可以参考原文。这里重点介绍其思想。
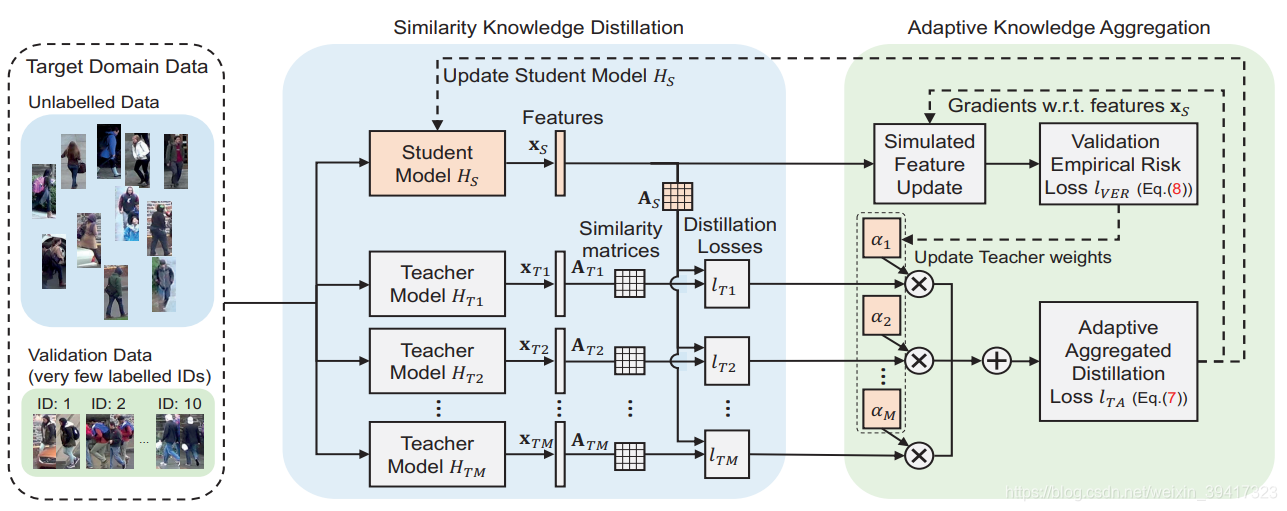
整体框架如图所示,主要是蒸馏学习的思想。训练时只需要target数据库中的10个标签信息,解决了标签问题;使用了多个老师模型,利用了先验知识,解决了跨数据库问题;学生模型使用了轻量级网络,解决了计算量问题。
按照实现流程来进行分块介绍:
- 使用不同的数据库(source)训练多个老师模型,训练结束后,再也不需要source数据库。
- ImageNet初始化学生模型。
- 将目标数据库(target)随机分为有标签部分(10个身份足矣)和无标签部分。
- 分别利用以上模型提取target中每一张图像的特征向量x。
- 根据x计算出相似度矩阵A,A中第i行第j列代表图像i和图像j的匹配概率。
- 使用Lver更新每一个老师模型的权重a(可以理解为,权重越大,该老师模型对应的source和target越相似)。
- 计算出每一个老师模型和学生模型得到的相似矩阵的差异,并使用上述的权重加权,从而得到Lta。
- 使用Lta对学生模型进行更新。
- 循环训练。
看到这,对整体框架有了一定的把握。但是会有一个问题:
如何更新各个老师模型的权重?
最开始,每一个权重被平均分配,比如4个老师模型,那么权重就都是0.25。然后,利用计算出的Lta对学生模型计算的特征向量x进行更新。然后,根据更新后的x计算Lver。最后对Lver进行求导,从而更新权重。
重点来了,如何计算Lver?
作者使用了很巧妙的方法:
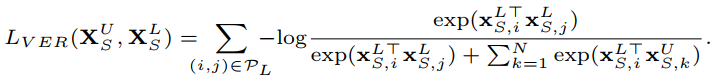
x是特征向量,s代表这是针对student模型,N代表batchsize,p代表一对正样本,即i和j构成正样本对,k和i、j都构成负样本对。正样本对利用了上述的10组使用标签的数据,由于使用标签的和不使用标签的不重合,所以从不使用标签的随机选一个样本就可以和使用标签的样本构成负样本对。我们希望正样本对乘积大,负样本对乘积小,最后就构成了该损失函数。
虽然只使用了10组有标签的样本(实验证明使用1组就有很大改善),但是因为只利用该损失更新老师模型所占权重,不更新其它参数,所以不会发生过拟合问题。换句话说,这10组使用标签的数据就是在告诉模型,target和哪一个source更相似。
直观感受一下,附上训练中权重的变化图:对应的target是market1501
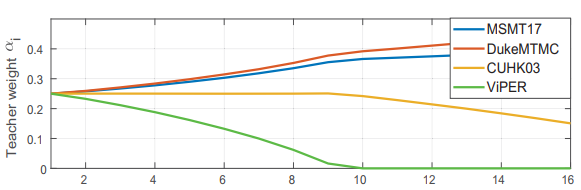
总结:难得一见得好文章,三个问题很实际,想法很新颖,实验很充分。具体的数学细节推荐大家参考原文,不难看懂。同时,提醒我们,无监督的re-ID的时代已经到来。
完
欢迎讨论 欢迎吐槽














 382
382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









