






用了selenium,才深刻的体会到它的好处,更加的方便更加的快捷,更容易的获取网页的信息。
这里用selenium爬取某鱼直播下面的前五页的直播间信息,例如直播房间名,主播名,直播热度,以及直播的类别。即图片红色下横线的东西。首先进入斗鱼的页面,选择直播,接着复制url备用,然后就按F12去分析

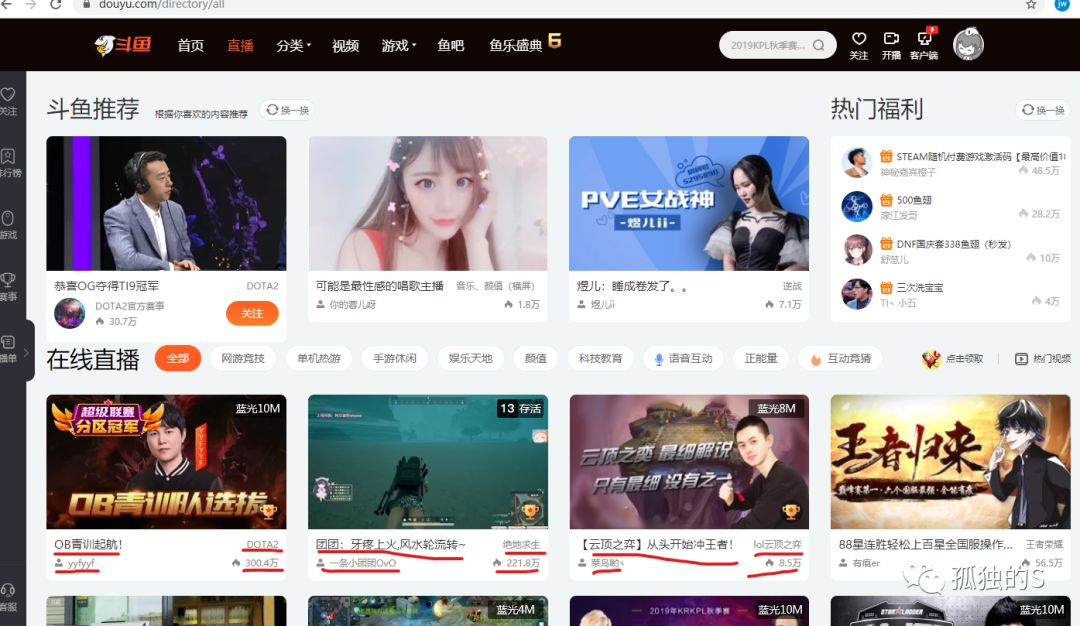
做爬虫的步骤还是那样,先去原网页的地址找到数据的位置,接着提取出需要的数据,在整理起来,保存起来。
这里我获取的只有前5页的直播间信息。当然可以获取更多的内容。做爬虫只是为了方便统计以及数据的可视化,便于学习和观察,并不能做什么非法操作。主要目的都是为了学习。
用selenium爬取网页的坑就只有一两个:
第一:获取url后,需要等待个几秒,让网页充分缓冲之后才去提取网页的数据,这样才能提取到数据,否则就是一个框架,并不能得到有用的消息。
第二,如果要实现换页功能的话,需要将解析网页的语句也放入循环,不然也会报错
第三,就是用selenium的时候一定要匹配好单引号和双引号,在python的习惯下,字符串就一般使用单引号去用,而网页的数据是双引号的话也提取不到数据。
第四,换页操作的时候,选择正确的class名字至关重要

如果用浏览器的f12的选择的功能,他会定位到这里黑色下划线的地方,但是要实现换行要选择红色下划线的class名,才能实现。
关于用selenium去爬取的东西也没其他的了,详细的操作可以去这里看
下面贴一下代码,代码仅供参考,如若有错,欢迎指出:
from selenium import webdriver
import time
path = '这里是你的selenium的驱动的地址'
url = 'https://www.douyu.com/directory/all'
browser = webdriver.Chrome(executable_path=path)
browser.maximize_window()
browser.get(url)
time.sleep(10)
allzhibo = []
nnum = 0
page = 0
while page<1:
li_list = browser.find_elements_by_xpath('//ul[@class="layout-Cover-list"]/li')
num = 0
for i in li_list:
zhibo = {}
if num >=10:
zhibo['数目'] = nnum
num+=1
nnum+=1
zhibo['直播房间名'] = i.find_element_by_class_name("DyListCover-intro").text
zhibo['主播'] = i.find_element_by_class_name("DyListCover-user").text
zhibo['直播热度'] = i.find_element_by_class_name("DyListCover-hot").text
zhibo['分类'] = i.find_element_by_class_name("DyListCover-zone").text
allzhibo.append(zhibo)
else:
num+=1
nextpage = browser.find_element_by_class_name("dy-Pagination-next")
nextpage.click()
page+=1
time.sleep(10)
#这里实现的是将数据保存到文本里去
with open('某鱼直播.txt','w',encoding='utf-8') as f:
for i in allzhibo:
for j in i.keys():
print(j+':'+str(i[j])+' ')
f.write(j+':'+str(i[j])+' ')
f.write('\n')
browser.close()
最后得到结果就是这样的:

然后可以对这些数据进行分类排序,就可以得到一些热度最高的直播间,或者是什么分类的直播间有那些的操作。
最后祝大家中秋快乐!!!


















 1387
1387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









