







本文是BERT相关系列模型第四篇内容,之前内容见下链接。
篇一:BERT之后,NLP主要预训练模型演变梳理
篇二:带你走进 ERNIE
篇三:RoBERTa:一种稳健优化BERT的预训练方法
1.基本介绍
DeBERTa(Decoding-enhanced BERT with disentangled attention)模型是微软在2021年提出的,到现在其实已经迭代了三个版本,第一版发布的时候在SuperGLUE[1]DeBERTa(Decoding-enhanced BERT with disentangled attention)模型是微软在2021年提出的,到现在其实已经迭代了三个版本,第一版发布的时候在SuperGLUE[1]排行榜上就已经获得了超越人类的水平。目前,一些比较有挑战的NLP任务,甚至是NLG任务都会用DeBERTa模型当成预训练模型,进一步微调。排行榜上就已经获得了超越人类的水平。目前,一些比较有挑战的NLP任务,甚至是NLG任务都会用DeBERTa模型当成预训练模型,进一步微调。
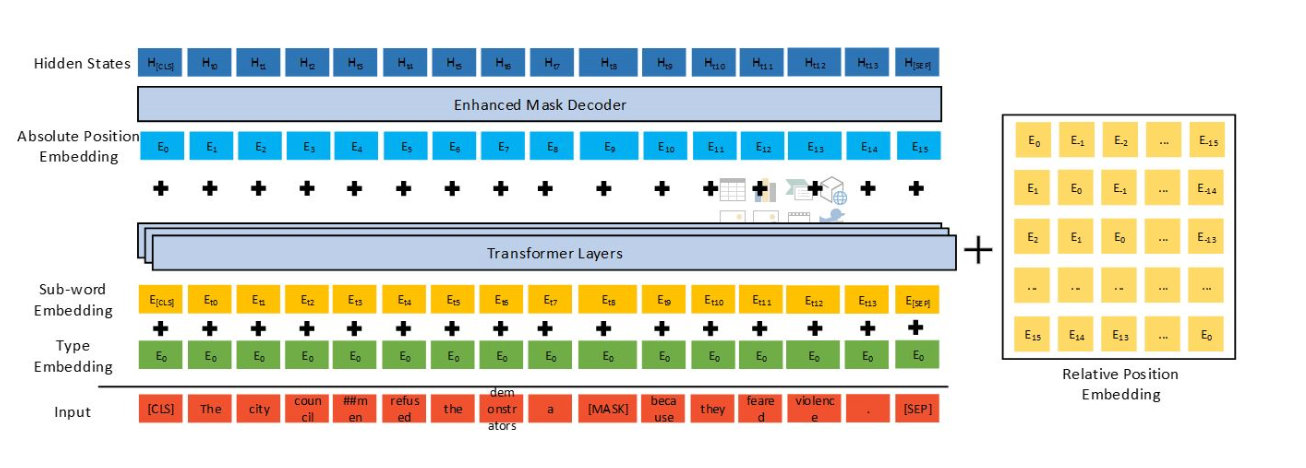
图1:DeBERTA V1 模型结构
来源:https://www.microsoft.com/en-us/research/blog/microsoft-deberta-surpasses-human-performance-on-the-superglue-benchmark/?lang=fr_ca
DeBERTa 模型使用了两种新技术改进了 BERT 和 RoBERTa 模型,同时还引入了一种新的微调方法以提高模型的泛化能力。
两种新技术的改进:
- 注意力解耦机制:图1右侧黄色部分
- 增强的掩码解码器 :图1左侧Enhanced Mask Decoder部分(V3版本中,用其他方法替换)
新的微调方法:虚拟对抗训练方法。
结果表明,这些技术显著提高了模型预训练的效率以及自然语言理解(NLU)和自然语言生成(NLG)下游任务的性能。
与 Large-RoBERTa 相比,基于一半训练数据训练的 DeBERTa 模型在很多 NLP 任务中始终表现得更好,MNLI 提高了+0.9%(90.2%–>91.1%),SQuAD v2.0提高了+2.3%(88.4%–>90.7%),RACE提高了+3.6%(83.2%–>86.8%)。
同时,通过训练由48个Transformer层和15亿参数组成的Large-DeBERTa模型。其性能得到显著提升,单个 DeBERTa 模型在平均得分方面首次超过了 SuperGLUE 基准测试上的表现,同时集成的 DeBERTa 模型目前位居榜首。 截至 2021 年 1 月 6 日,SuperGLUE 排行榜已经超过了人类基线(90.3 VS 89.8)。
2.DeBERTa架构
2.1 DeBERTa V1
2.1.1 结构图
图1:DeBERTa V1模型结构
2.1.1 优化点解释
a) 注意力解耦(Disentangled attention)
- 在BERT 中,输入层的每个单词都使用一个向量来表示,该向量是其单词(内容)嵌入和位置嵌入的总和。
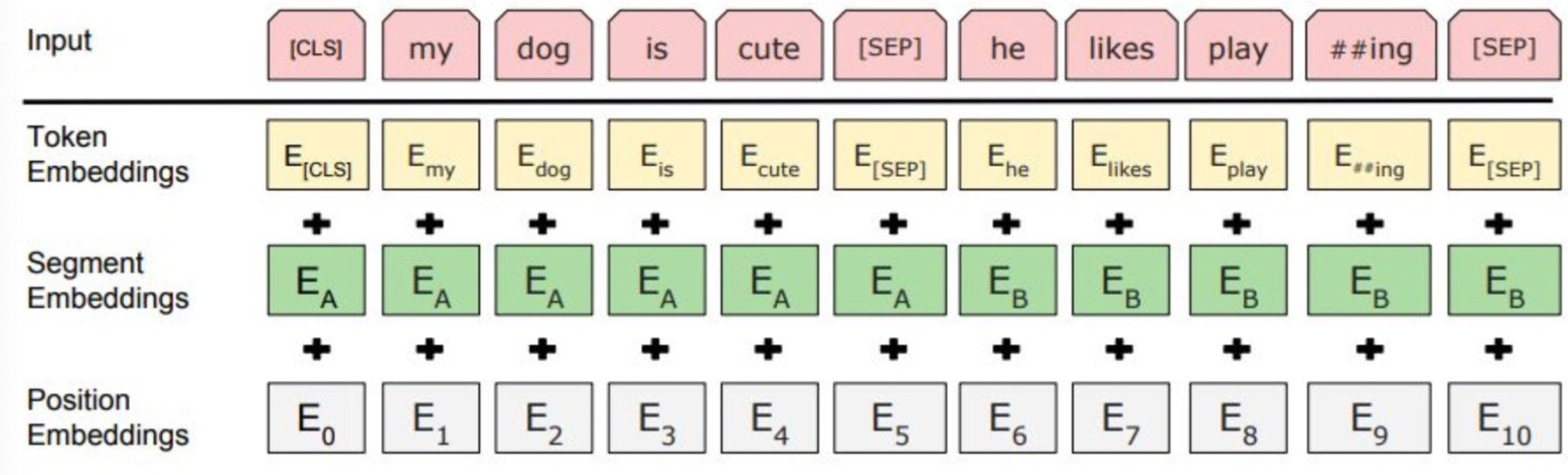
图2:BERT输入表示. 输入嵌入是token embeddings, segmentation embeddings 和position embeddings 之和。
- 而 DeBERTa 中的每个单词使用两个对其内容和位置分别进行编码的向量来表示,并且注意力单词之间的权重分别使用基于它们的内容和相对位置的解码矩阵来计算。
- 这么做的原因是,经观察发现,单词对的注意力权重不仅取决于它们的内容,还取决于它们的相对位置。 例如,“deep”和“learning”这两个词相邻出现时,它们之间的依赖性比它们出现在不同句子中时要强得多。
- 对于序列中位置 i 处的 token,微软使用了两个向量, {Hi} 和{ Pi|j }表示它,它们分别表示其内容和与位置 j 处的token的相对位置。 token i 和 j 之间的交叉注意力得分的计算可以分解为四个部分:
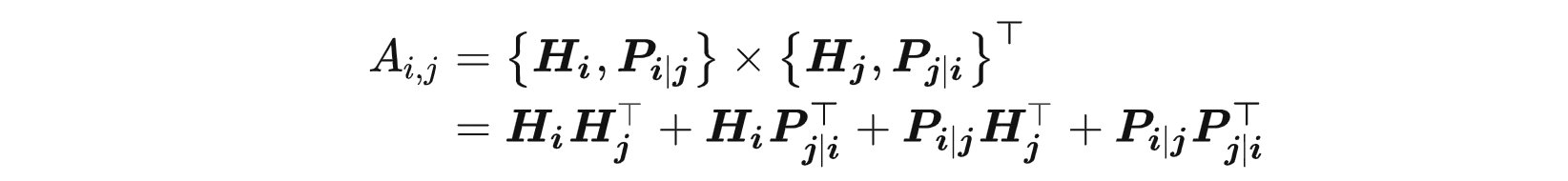
- 也就是说,一个单词对的注意力权重可以使用其内容和位置的解耦矩阵计算为四个注意力(内容到内容,内容到位置,位置到内容和位置到位置)的得分总和。
- 现有的相对位置编码方法在计算注意力权重时使用单独的嵌入矩阵来计算相对位置偏差。 这等效于仅使用上等式中的“内容到内容”和“内容到位置”来计算注意力权重。微软认为位置到内容也很重要,因为单词对的注意力权重不仅取决于它们的内容,还会和相对位置有关。根据它们的相对位置,只能使用内容到位置和位置到内容进行完全建模。 由于微软使用相对位置嵌入,因此位置到位置项不会提供太多附加信息,因此在实现中将其从上等式中删除。

b) 增强的掩码解码器
DeBERTa和BERT模型一样,也是使用MLM进行预训练的,在该模型中,模型被训练为使用 mask token 周围的单词来预测mask词应该是什么。 DeBERTa将上下文的内容和位置信息用于MLM。 解耦注意力机制已经考虑了上下文词的内容和相对位置,但没有考虑这些词的绝对位置,这在很多情况下对于预测至关重要。
如:给定一个句子“a new store opened beside the new mall”,并用“store”和“mall”两个词 mask 以进行预测。 仅使用局部上下文(即相对位置和周围的单词)不足以使模型在此句子中区分store和mall,因为两者都以相同的相对位置在new单词之后。 为了解决这个限制,模型需要考虑绝对位置,作为相对位置的补充信息。 例如,句子的主题是“store”而不是“mall”。 这些语法上的细微差别在很大程度上取决于单词在句子中的绝对位置。
有两种合并绝对位置的方法。 BERT模型在输入层中合并了绝对位置。 在DeBERTa中,微软在所有Transformer层之后将它们合并,然后在softmax层之前进行 mask token 预测,如图3 所示。这样,DeBERTa捕获了所有Transformer层中的相对位置,同时解码被mask的单词时将绝对位置用作补充信息 。 此即为 DeBERTa 增强型掩码解码器(EMD)。
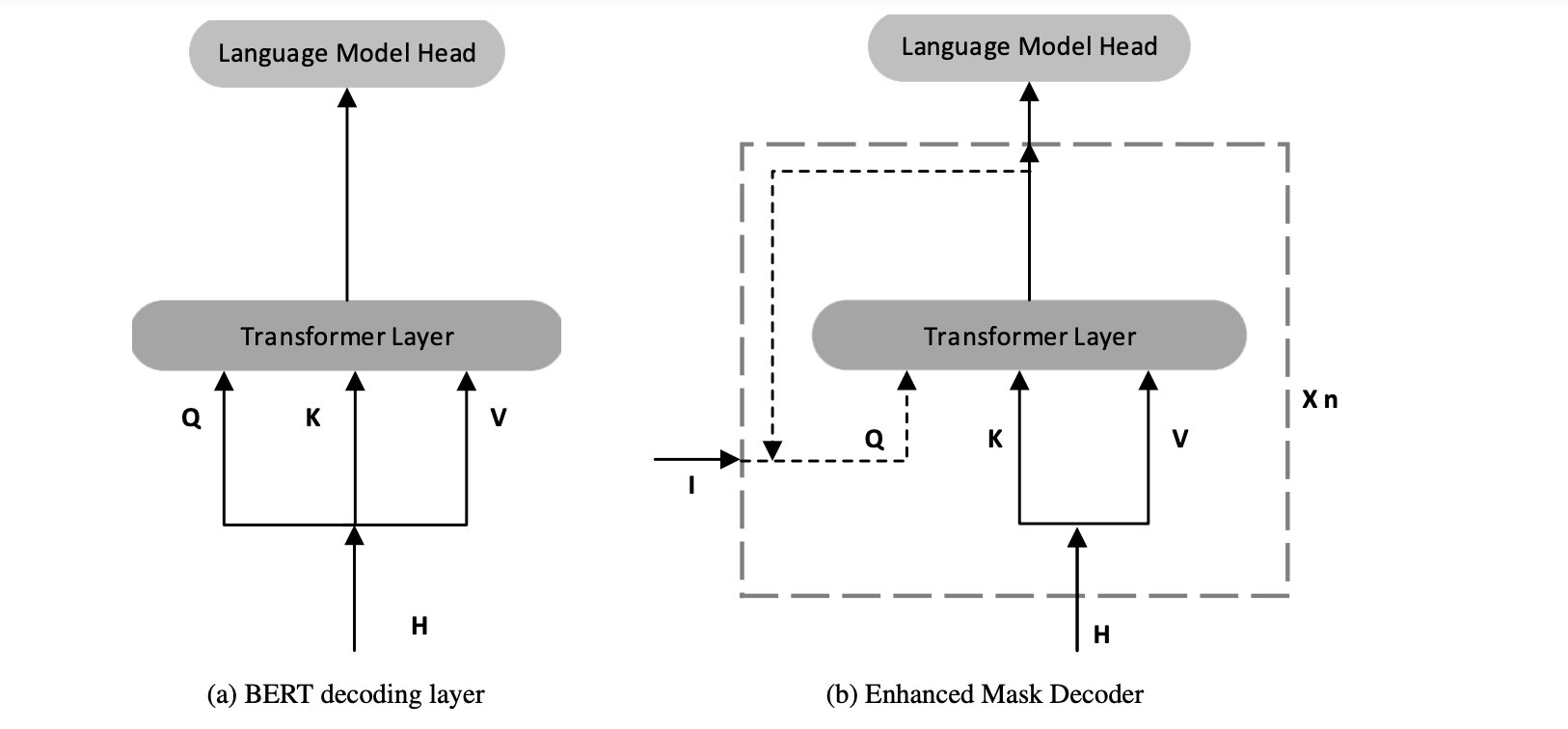
图3: 解码器比较
来源:https://arxiv.org/pdf/2006.03654.pdf
EMD的结构如图2b 所示。 EMD有两个输入(即 I , H I,H I,H)。 H H H 表示来自先前的transformer层的隐藏状态,并且 I I I 可以是用于解码的任何必要信息,例如,绝对位置嵌入或从先前的EMD层输出。 n n n 表示 n n n 个EMD堆叠层,其中每个EMD层的输出将是下一个EMD层的输入 I I I,最后一个EMD层的输出将直接输出到语言模型头。 n n n 层可以共享相同的权重。 在实验中,微软设定 n = 2 n=2 n=2 ,即2层共享相同的权重,以减少参数的数量,并使用绝对位置嵌入作为第一个EMD层的 I I I。 当 I = H I=H I=H 和 n = 1 n=1 n=1 时,EMD与BERT解码器层相同。 不过,EMD更通用、更灵活,因为它可以使用各种类型的输入信息进行解码。
c) 虚拟对抗训练方法
对抗训练是NLPer经常使用的技术,在做比赛或者公司业务的时候一般都会使用对抗训练来提升模型的性能。DeBERTa预训练里面引入的对抗训练叫SiFT,它攻击的对象不是word embedding,而是embedding之后的layer norm。
规模不变微调(Scale-invariant-Fine-Tuning SiFT)算法一种新的虚拟对抗训练算法, 主要用于模型的微调。
虚拟对抗训练是一种改进模型泛化的正则化方法。 它通过对抗性样本提高模型的鲁棒性,对抗性样本是通过对输入进行细微扰动而创建的。 对模型进行正则化,以便在给出特定于任务的样本时,该模型产生的输出分布与该样本的对抗性扰动所产生的输出分布相同。
对于之前的NLP任务,一般会把扰动应用于单词嵌入,而不是原始单词序列。 但是嵌入向量值的范围在不同的单词和模型之间有所不同。 对于具有数十亿个参数的较大模型,方差会变大,从而导致对抗训练有些不稳定。
受层归一化的启发,微软提出了SiFT算法,该算法通过应用扰动的归一化词嵌入来提高训练稳定性。 即在实验中将DeBERTa微调到下游NLP任务时,SiFT首先将单词嵌入向量归一化为随机向量,然后将扰动应用于归一化的嵌入向量。 实验表明,归一化大大改善了微调模型的性能。
2.2 DeBERTa V2
2021年2月微软放出的 V2 版本在 V1 版本的基础上又做了一些改进:
**1.词表:**在 v2 中,tokenizer扩的更大,从V1中的50K,变为 128K 的新词汇表。
2.nGiE(nGram Induced Input Encoding) v2 模型在第一个转换器层之外使用了一个额外的卷积层,以更好地学习输入标记的依赖性。
**3.共享位置和内容的变换矩阵:**通过实验表明,这种方法可以在不影响性能的情况下保存参数。
**4.应用桶方法对相对位置进行编码:**v2 模型使用对数桶对相对位置进行编码。
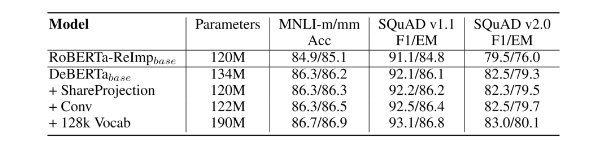
图3: DeBERTa V2优化结果对比
来源:https://arxiv.org/pdf/2006.03654.pdf
优化结果:2.0版几个变更对模型的影响,增大词典效果最显著。
2.3 DeBERTa V3
2021年11月微软又放出了 V3 版本。这次的版本在模型层面并没有修改,而是将预训练任务由掩码语言模型(MLM)换成了ELECTRA一样类似GAN的RTD (Replaced token detect) 任务。
我们知道BERT模型只使用了编码器层和MLM进行训练。而ELECTRA 使用 GAN 的思想,利用生成对抗网络构造两个编码器层进行对抗训练。其中一个是基于MLM训练的生成模型,另一个是基于二分类训练的判别模型。生成模型用于生成不确定的结果同时替换输入序列中的掩码标记,然后将修改后的输入序列送到判别模型。判别模型需要判断对应的 token 是原始 token 还是被生成器替换的 token。
不同的训练方法实验尝试:
- 1、[ES]生成模型和判别模型共享embedding层训练;
- 2、[NES]生成模型和判别模型不共享embedding层,也不共享参数层,交替训练;
- 3、[GDES]生成模型和判别模型部分共享。
通过实验表明:

图3: DeBERTa V3优化结果对比
来源:https://arxiv.org/pdf/2111.09543.pdf
DeBERTa V3 在某些任务中相比之前模型有不小的涨幅,其中GDES模式优化效果最好。
3.相关code
DeBERTa官方文档,可以直接调库实现:
- DeBERTa code_1: https://deberta.readthedocs.io/en/latest/index.html
haggingface实现DeBERTa,可以直接调库实现:
- DeBERTa code_2: https://huggingface.co/docs/transformers/model_doc/deberta
官方源码:
- DeBERTa code_3: https://github.com/microsoft/DeBERTa
4.总结
- 1.DeBERTa V1 相比 BERT 和 RoBERTa 模型的改进:
- 两种技术改进:
- 注意力解耦机制
- 增强的掩码解码器
- 新的微调方法:虚拟对抗训练方法(SiFT)。
- 两种技术改进:
- 2.DeBERTa V2 改进
- tokenizer扩的更大(优化效果最明显)
- transformer外使用了额外的卷积层
- 共享位置和内容的变换矩阵
- 应用桶方法对相对位置进行编码
- 3.DeBERTa V3 改进
- 在模型层面并没有修改,将预训练任务MLM换成了ELECTRA一样类似GAN的RTD任务
5.参考文献
[1] SuperGLUE: https://super.gluebenchmark.com/leaderboard
[2] DeBERTa: https://arxiv.org/pdf/2006.03654.pdf
[3] DeBERTa 2.0: https://huggingface.co/docs/transformers/model_doc/deberta-v2
[4] DeBERTa 3.0: https://arxiv.org/pdf/2111.09543.pdf
[5] 微软 deDERTa 官网: https://www.microsoft.com/en-us/research/blog/microsoft-deberta-surpasses-human-performance-on-the-superglue-benchmark/?lang=fr_ca



















 1077
1077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











