







大语言模型(LLM)为基于文本的对话提供了强大的能力。那么,能否进一步扩展,将其转化为语音对话的形式呢?本文将展示如何使用 Whisper 语音识别和 llama.cpp 构建一个 Web 端语音聊天机器人。
系统概览
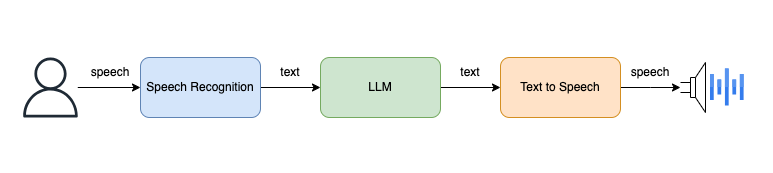
如上图所示,系统的工作流程如下:
- 用户通过语音输入。
- 语音识别,转换为文本。
- 文本通过大语言模型(
LLM)生成文本响应。 - 最后,文本转语音播放结果。
系统实现
端侧的具体形态(如 web 端、桌面端、手机端)直接影响了第一步用户语言的输入,以及最后一步响应结果的语音播放。
在本文中,我们选择使用 Web 端作为示例,利用浏览器本身的语言采集和语音播放功能,来实现用户与系统的互动。
下图展示了系统架构:
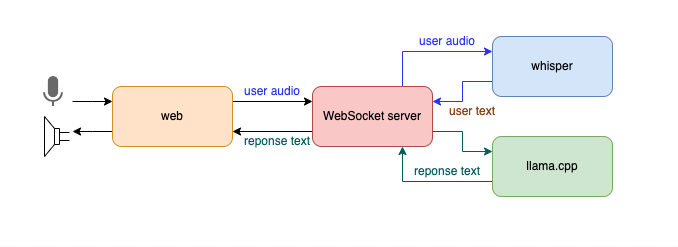
用户通过 Web 端与系统交互,语音数据通过 WebSocket 传输到后端服务,后端服务使用 Whisper 将语音转换为文本,接着通过 llama.cpp 调用 LLM 生成文本响应,最后,文本响应通过 WebSocket 发送回前端,并利用浏览器的语音播放功能将其朗读出来。
Web 端
Web 端的实现主要依赖 HTML5 和 JavaScript。我们使用浏览器的 Web API 进行语音采集和语音播放。以下是简化的 Web 端代码示例:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Voice Chat AI</title>
<style>
#loading {
display: none; font-weight: bold; color: blue }
#response {
white-space: pre-wrap; }
</style>
</head>
<body>
<h1>Voice Chat AI</h1>
<button id="start">Start Recording</button>
<button id="stop" disabled>Stop Recording</button>
<p id="loading">Loading...</p>
<p>AI Response: <span id 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









