





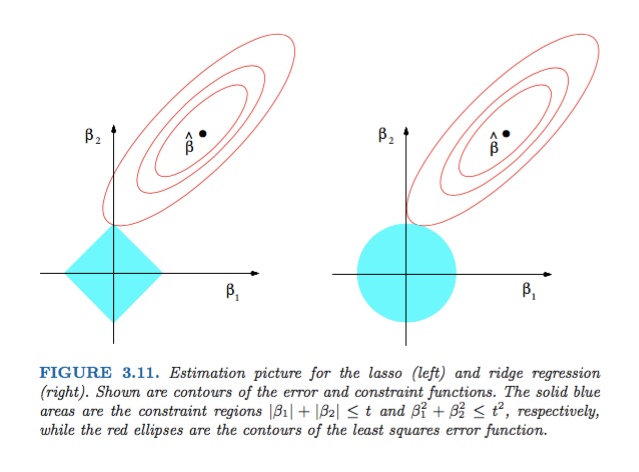
这两种回归与普通的回归就是在后面多加了一个正则项,两种回归就是两种不同的正则项。
在机器学习中,处理过拟合的问题,或者在计量经济学中,处理多重共线性问题可以使用这两种方法来解决,其中,岭回归用的较多。
在普通的线性回归中,我们希望最小化损失函数,在计量中的称之为误差平方和(sum of squared errors),即所有预测值与其实际值之间的差的平方的和。
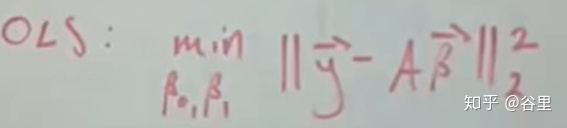
如果满足所有的前提假设的话,那么估计出来的权重便是blue的,即最佳线性无偏估计(best linear unbiased estimates)。在计量经济学中,我们需要的是对于样本更好的拟合,从而得到各个因素与因变量的准确关系。
但是机器学习中,情况确实不一样了,目标是得到一个分类或预测能力更好的模型。样本被分成了两块或三块,通过对于训练样本的训练得到模型,然后对于另一块测试样本进行预测,这样由于两块数据不一样,对于训练样本拟合的过好,反而可能是一个不好的结果,即模型太针对训练集,而对于测试集的预测反而下降,这是机器学习中的biased和variance的问题。
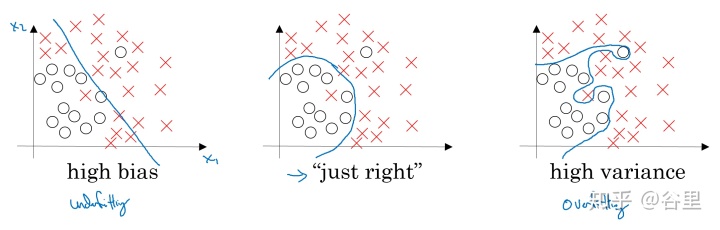
所以,在机器学习中,我们主动加入正则项,引入估计误差,虽然可能会降低在训练集上的表现,但是可以使模型拥有更好的泛化能力,而不过于针对于训练集而导致在测试集上表现变差很多。
而在计量经济学中,多重共线性的问题或导致估计权重参数的“膨胀”,为了需要约束估计权重参数在一定范围之内,而引入了约束项,即所有权重的和或是平方和需要小于一定的数值。
岭回归和lasso回归就是两种不同的约束,岭回归使所有估计权重参数的平方和需要小于一定值,而lasso回归是所有权重参数的绝对值的和需要小于一定值。
机器学习中,通常会直接甩出原始代价函数,以及加了正则项之后的,如下

有了函数便可以开始工作了。
如果关心这个函数是如何由来的,可以从原始的OLS来看,我们为的是最小化代价函数,加入了正则项就是在最优化问题中引入了一个约束条件,以下为岭回归示例。
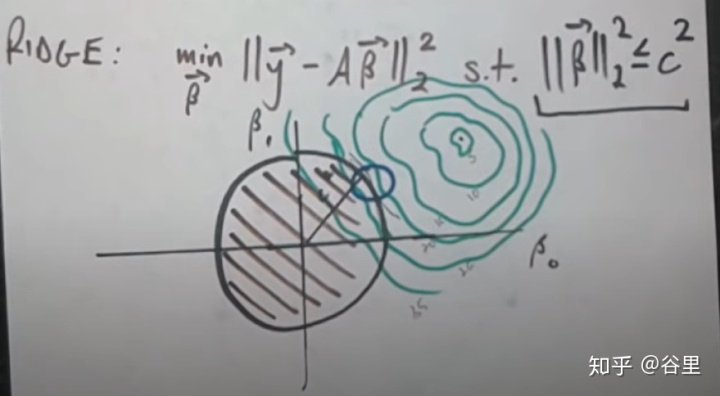
绿色的等高线图是原本的最优化问题,如果没有约束项,那毫无疑问选择最中心的那个最好,但如果加入了约束条件,即黑色的圈,既要最小化代价函数,又要符合约束条件,那选取的点总是在切线的位置,因此这里的约束条件可以视作为等于,而不是小于等于。
这样我们就可以使用拉格朗日乘子法,问题变成最小化下面这个函数的问题。
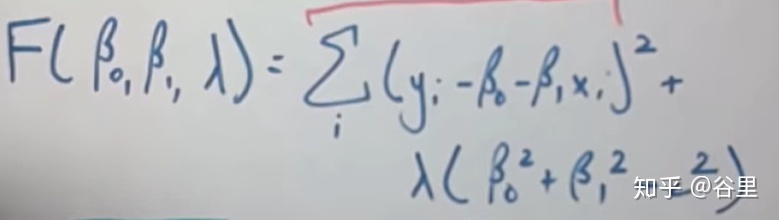
这个函数就跟前面甩出来的岭回归的代价函数很像了,这里的λ就是惩罚系数,是事先给定的一个超参数,在这里可以视作常数,而后面一项c方与λ相乘也是一个常数,在最小化问题中没有什么用,可以直接忽略掉,因此,这个函数就与代价函数完全一样了。

由代价函数对β求偏导,如果是个凸函数,那就可以得到以下的结果。

由此方程可以得知为什么惩罚系数λ越大,权重β就越小了,前面包含惩罚系数项的为分母,如果很大,那边上的就可以忽略不计,分母由λ决定,自然λ越大,β就越小了。
因此,引入正则项就是为了约束权重参数β,使它小一点,对于因变量贡献变小。
以下Andrew在梯度下降过程中引入正则项的推导也就很好懂了。

这里的权重w即为β,由于一层神经网络有多个神经元,因此权重是二维的,正则项把他们都加起来即可。有最后的式子也可以很容易看出,就是在每次梯度下降之前就先对权重进行缩小,缩小惩罚系数的某个倍数。
lasso与岭回归不一样的就是惩罚项为一次项,那么约束条件在坐标轴上就从一个圆变成了一个菱形。
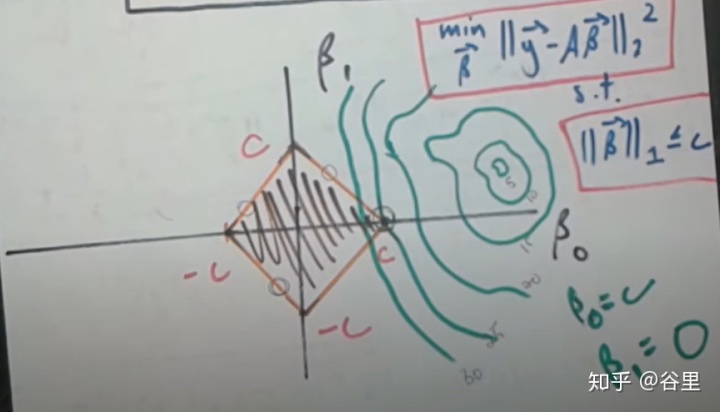
同样取切点。之后的推到就类似了。
常说lasso被用于特征选取,因为lasso回归的结果很多权重等于0,说明这个特征或是变量没有作用,可以丢弃。原因在于上面的约束图形,如果是一个这样的图形,那么很显然,像比如岭回归的圆,这样的情况使得切点更可能在坐标轴上,所以会出现一个特征的权重为0的情况。
另外需要注意的一点是,可以看出权重参数是整体缩减的,因此,我们需要在训练之前对数据进行标准化,以消除不同特征之间的量纲影响。因为这可能使得一些并不重要的特征的权重反而大于重要的权重,使得惩罚出现问题。而消除了量纲影响之后,就避免了这样的情况。并且,标准化不会带来什么负面影响,因此,默认选择做一般不会出现问题。
以上公式截图与图形于:
https://www.youtube.com/watch?v=jbwSCwoT51Mwww.youtube.com https://www.youtube.com/watch?v=5asL5Eq2x0Awww.youtube.com https://www.coursera.org/learn/deep-neural-network/lecture/Srsrc/regularizationwww.coursera.org封面图来自于:Elements of Statistical Learning by Hastie, Tibshirani, and Friedman















 4554
4554











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









