







- 阅读《李航统计学习方法》的65-74页
- 学习Gini指数
- 学习回归树
- 剪枝
-
CART算法
1984年提出,1和2由此引入,CART算法同样由特征选择、树生成、剪枝组成,既可用来分类也可用于回归。
- 分类树的生成
本质是递归的构建二叉决策树,回归树用平方误差最小化准则,分类树用Gini指数选择最优特征,同时决定该特征的最优二值切分点。- 回归树的生成:

停止条件可以为树深度等。 - 分类树生成:

- Gini指数:分类问题中,假设有K个类,样本点属于第k类的概率为
p
k
p_{k}
pk,则概率分布的Gini指数定义为:
G i n i ( p ) = ∑ k = 1 K p k ( 1 − p k ) = 1 − ∑ k = 1 K p k 2 Gini(p)=\sum_{k=1}^{K}p_{k}(1-p_{k})=1-\sum_{k=1}^{K}p_{k}^{2} Gini(p)=∑k=1Kpk(1−pk)=1−∑k=1Kpk2
对于二分类问题:
G i n i ( p ) = 2 p ( 1 − p ) Gini(p)=2p(1-p) Gini(p)=2p(1−p)
对于给定的样本集合D:
G i n i ( p ) = 1 − ∑ k = 1 K ( ∣ C k ∣ ∣ D ∣ ) 2 Gini(p)=1-\sum_{k=1}^{K}\left ( \frac{\left | C_{k} \right |}{|D|} \right )^{2} Gini(p)=1−∑k=1K(∣D∣∣Ck∣)2
如果样本集合D根据特征A是否为a被分割成D1和D2,即:
D 1 = { ( x , y ) ∈ D ∣ A ( x ) = a ) } , D 2 = D − D 1 D_{1}=\{ (x,y)\in D|A(x)=a)\},D_{2}=D-D_{1} D1={(x,y)∈D∣A(x)=a)},D2=D−D1
则在特征A的条件下,集合D的基尼指数:
G i n i ( D , A ) = D 1 D G i n i ( D 1 ) + D 2 D G i n i ( D 2 ) ) Gini(D,A)=\frac{D_{1}}{D}Gini(D_{1})+\frac{D_{2}}{D}Gini(D_{2})) Gini(D,A)=DD1Gini(D1)+DD2Gini(D2))
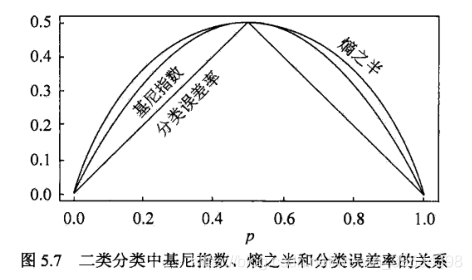
Gini G i n i ( D ) Gini(D) Gini(D)指数表示集合D的不确定性,Gini(D,A)表示经过A=a分割后D的不确定性。Gini指数越大表示不确定性越大。 - 下图显示二分类问题中Gini指数、1/2熵和分类误差率的关系。横坐标表示概率,纵坐标表示损失。可以看出基尼指数和熵之半的曲线很接近,可以近似地表示分类误差率。
- 回归树的生成:
- 剪枝
- 剪枝:决策树过拟合风险很大,理论上可以完全分得开数据
- 策略:
- 预剪枝:一边建立树一边进行剪枝操作
- 后剪枝:当建立完决策树后进行剪枝操作
- 预剪枝:限制深度,叶子节点个数,叶子节点样本数,
- 后剪枝:通过一定标准衡量
决策树的剪枝往往通过极小化决策树整体的损失函数来实现,设树T的叶结点个数为|T|,t是树T的叶结点,该叶结点有 N t N_{t} Nt个样本点,其中k类的样本点有N_{tk}个,k=1,2,…,K,H_{t}(T)为叶结点t上的经验熵, α ≥ 0 \alpha\geq 0 α≥0为参数,则决策树学习的损失函数可以定义为。
C a ( T ) = ∑ t = 1 ∣ T ∣ N t H t ( T ) + α ∣ T ∣ C_{a}(T)=\sum_{t=1}^{\left | T \right |}N_{t}H_{t}(T)+\alpha |T| Ca(T)=∑t=1∣T∣NtHt(T)+α∣T∣
∑ t = 1 ∣ T ∣ N t H t ( T ) \sum_{t=1}^{\left | T \right |}N_{t}H_{t}(T) ∑t=1∣T∣NtHt(T)表示模型对训练数据的预测误差,即模型与训练数据的拟合程度,|T|表示模型复杂度,参数 α ≥ 0 \alpha\geq0 α≥0控制两者之间的影响。














 184
184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









