 HunyuanVideo:开源视频生成大模型解析
HunyuanVideo:开源视频生成大模型解析




目录
2.2 Unified Image and Video Generative Architecture
3.4 High-performance Model Fine-tuning
HunyuanVideo是由腾讯公司开发的开源视频生成大模型。该模型基于深度学习技术,参数规模达130亿,支持文本生成视频、图像生成视频及视频编辑功能,具备物理规律模拟和高动态画面生成能力。它采用3D因果变分自编码器架构和全注意力机制,支持480P至720P分辨率视频生成,应用于广告创作、短视频制作等领域。
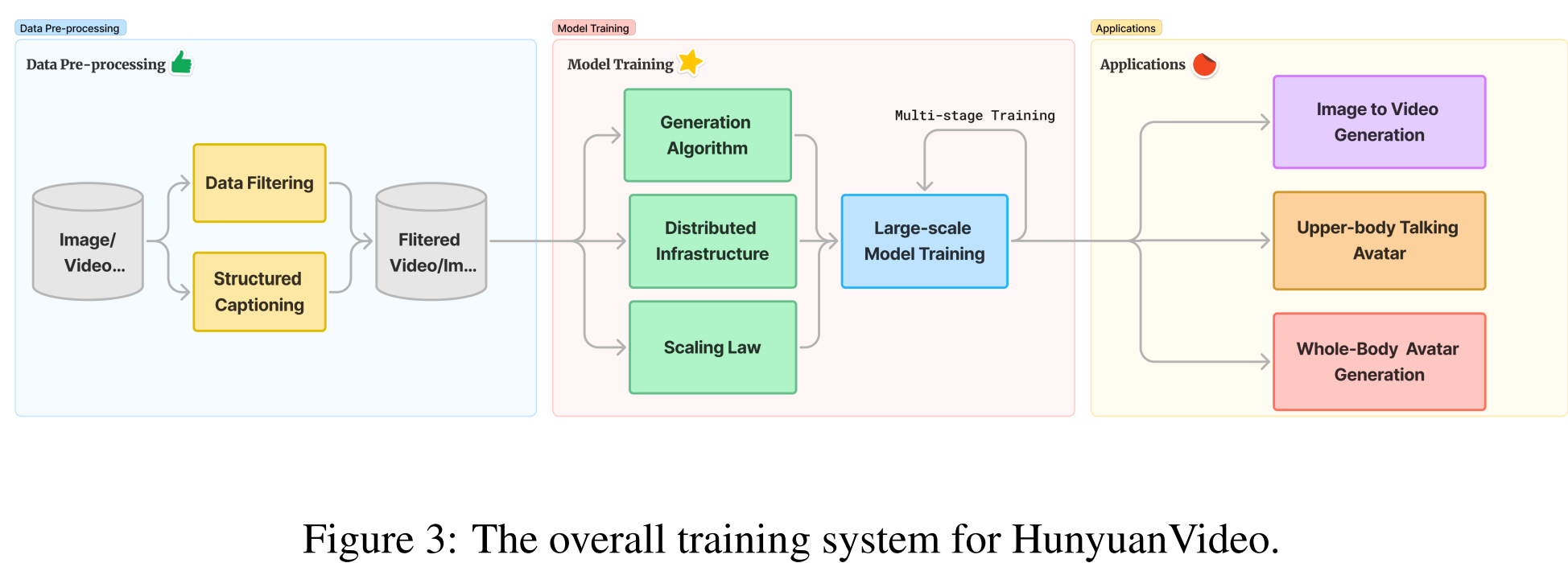
1、Data Pre-processing
与Movie Gen一样, HunyuanVideo也是使用图像-视频联合训练策略。其中视频被精心分为五个不同的组,而图像被分为两组,每组都是根据各自训练过程的具体要求而定制的。原始数据池最初包括广泛素材的视频,包括人物,动物,植物,景观,车辆,物体,建筑物和动画。每个视频的采集都有一组基本阈值,包括最低持续时间要求。此外,数据的子集是基于更严格的标准收集的,例如空间质量,遵守特定的长宽比,以及构图,颜色和曝光的专业标准。这些严格的标准确保收集的视频具有技术质量和美学吸引力。数据质量越高,模型效果越好。
1.1 数据过滤
HunyuanVideo也是采用了一系列的技术来预处理原始数据。与Movie Gen的数据处理流程是非常类似的。首先,作者利用PySceneDetect将原始视频拆分为单镜头视频剪辑,把长视频拆分成短视频 ,减少token压力 。然后,作者使用OpenCV中的拉普拉斯算子来识别一个清晰的帧,作为每个视频剪辑的起始帧。使用内部VideoCLIP模型,我们计算这些视频剪辑的Embedding。这些Embedding有两个目的:1)基于Embedding的余弦距离对相似片段进行重复数据删除;2)我们应用k-means 来获得10000个概念质心,用于重新排序和平衡。这两个对应的是Movie Gen中的conten filtering。
为了进一步增强视频美学、运动和概念范围,作者实现了一个分层数据过滤管道来构建训练数据集。具体流程如下图所示:
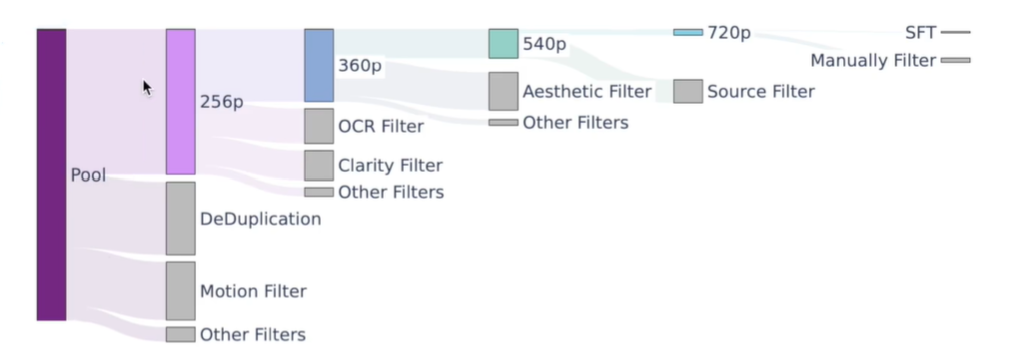
- 1)使用Dover从美学和技术角度评估视频剪辑的视觉美学。
- 2)此外,作者还训练了一个模型来确定清晰度并消除具有视觉模糊的视频片段。
- 3)通过使用估计的光流预测视频的运动速度,过滤掉静态或慢动作视频。
- 4)将PySceneDetect和Transnet v2的结果结合以获得场景边界信息。
- 5)利用内部的OCR模型来删除带有过多文本的视频片段,以及定位和裁剪字幕。
- 6)作者还开发了类似YOLOX的视觉模型来检测和删除一些遮挡或敏感信息,例如水印、边框和徽标。
- 7)为了评估这些过滤器的有效性,HunyuanVideo还使用较小的hunyuan-video模型进行简单的实验并观察性能变化。(scaling low)
针对视频数据的分层数据过滤管道产生了五个训练数据集,对应于五个训练阶段。这些数据集(除了最后一个微调数据集)通过逐步提高上述过滤器的阈值来管理。随着视频空间分辨率逐渐增加,对过滤器的筛选级别也逐级变严。
SFT数据:为了提高模型在最后阶段的性能,HunyuanVideo构建了一个微调数据集,包括1000万个样本。该数据集通过人工注释精心策划,由具有复杂运动细节的视觉上吸引人的视频剪辑组成。
1.2 数据标注
对应的是Movie Gen中的Captioning的section。字幕的精确性和全面性对提高生成式模型的快速跟踪能力和输出质量起着至关重要的作用。大多数先前的工作集中在提供简短的字幕或密集的字幕。但是它们都存在信息不完整、话语冗余和不准确等问题。
为了实现更全面、更高信息密度和更高准确度的字幕,HunyuanVideo开发并实施了一个内部视觉语言模型(VLM),旨在为图像和视频生成结构化字幕。这些结构化的标题,以JSON格式保存,从不同的角度提供多维描述信息,包括:
- 1)简短描述:捕获场景的主要内容。
- 2)密集描述:详细描述场景的内容,其中特别包括与视觉内容相结合的场景过渡和摄像机移动,例如摄像机跟随某个主题。
- 3)背景:描述受试者所处的环境。
- 4)风格:描述视频的风格,如纪录片、电影、写实或科幻。
- 5)镜头类型:标识突出显示或强调特定视觉内容的视频快照类型,如航拍、特写、中摄或远景。
- 6)照明:描述视频的照明条件。
- 7)氛围:传达视频的氛围,如温馨、紧张或神秘。
除此之外,HunyuanVideo还扩展了JSON结构体,添加了一些metadata-derived 元素,包括源标签、质量标签等。但是可能多样性存在问题,所以设计了dropout机制增加合成标签的多样性。
HunyuanVideo也做了摄影机移动类型的相机运动分类器,能够预测14种不同的相机运动类型,包括放大,缩小,向上摇摄,向下摇摄,向左摇摄,向右摇摄,向上倾斜,向下倾斜,向左倾斜,向右倾斜,向左左右,静态拍摄和手持拍摄。相机运动类型的高置信度预测被集成到JSON格式的结构化字幕中,以实现生成模型的相机运动控制能力。
2、Model Architecture Design
HunyuanVideo 在一个时空压缩的潜在空间上进行训练,该潜在空间通过3D VAE进行压缩。文本提示通过大型语言模型进行编码,并用作条件。以高斯噪声和文本提示作为输入,生成模型输出潜在表示,然后通过3D VAE解码器将其解码为图像或视频。
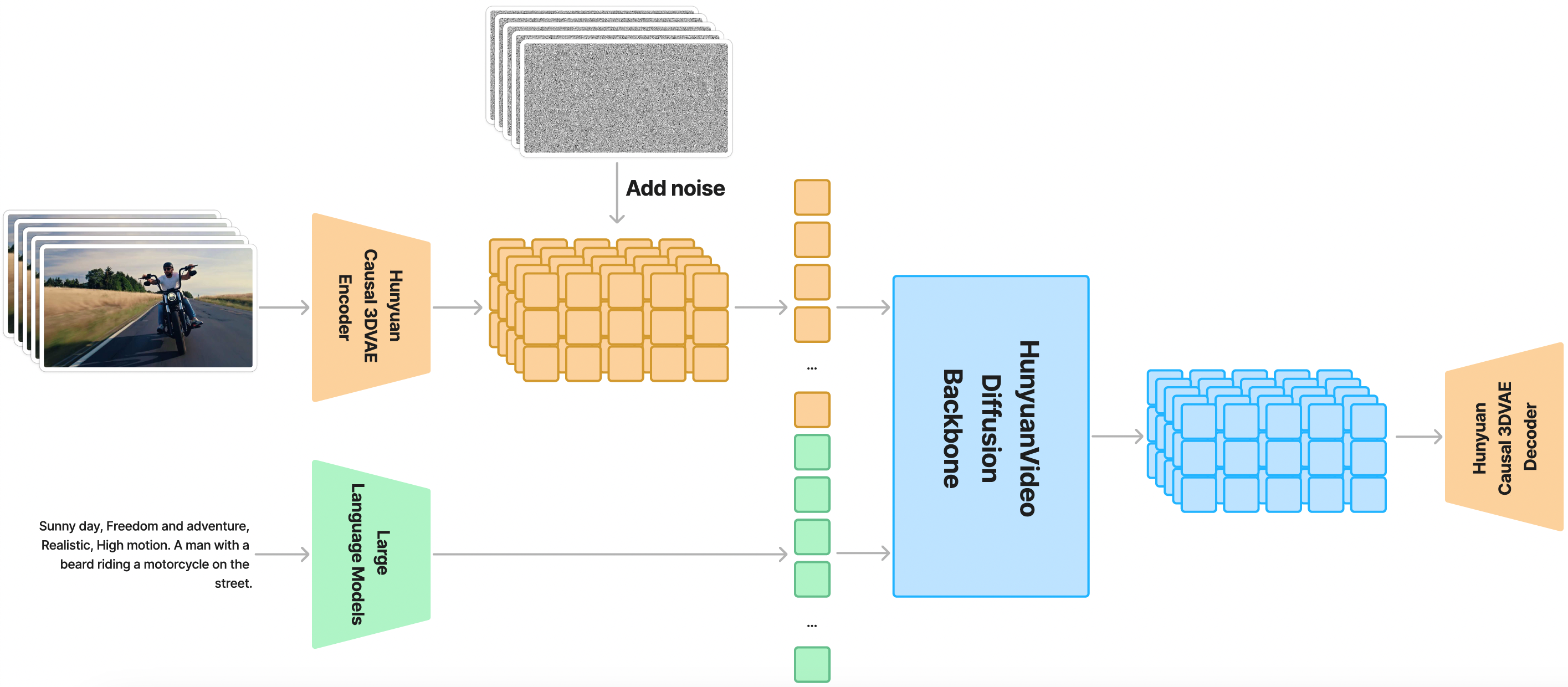
2.1 3D VAE
HunyuanVideo 使用 CausalConv3D 训练了一个 3D VAE,以将像素空间的视频和图像压缩到一个紧凑的潜在空间中。我们将视频长度、空间和通道的压缩比分别设置为 4、8 和 16。这可以显著减少后续扩散变换模型所需的token数量,所以可以以原始分辨率和帧率训练视频。

上图中(T+1)中的1指的是第一帧,可以同时兼容图像和视频。
2.1.1 训练
HunyuanVideo是从头开始训练3DVAE的,而非常见的预训练后微调。为了平衡视频和图像的重建质量,以4:1的比例混合视频和图像数据。除了常规使用的L1重建损失和KL损失Lkl之外,还使用了感知损失Llpips和GAN对抗损失Ladv以提高重建质量。
![]()
训练过程也是采用了从低分辨率的短视频逐渐变化到高分辨率的长视频的策略。为了重建出高运动视频,从1到8的范围内随机选择一个采样间隔,在视频剪辑中均匀地对帧进行采样(抽帧,加大动作幅度)。
2.1.2 推理
在单个GPU上进行高分辨率长视频的编码和解码,可能会导致内存不足错误(OOM)。为了解决这个问题,HunyuanVideo使用空间-时间Tiling策略,将输入视频沿空间和时间维度分割成重叠的块。每个块分别编码/解码,然后输出结果拼接在一起。对于重叠区域,使用线性组合进行融合。这种Tiling策略可以实现在单个GPU上编码/解码任意分辨率和时长的视频。
在推理过程中直接使用Tiling策略可能会由于训练和推理之间的不一致而导致可见的伪影。为了解决这个问题,又引入了一个额外的微调阶段,在训练过程中随机启用/禁用平铺策略。这确保了模型与平铺和非平铺策略兼容,保持了训练和推理之间的一致性。
2.2 Unified Image and Video Generative Architecture
HunyuanVideo 引入了Transformer设计,并采用全注意力机制用于统一的图像和视频生成。采用这种设计的原因有三:首先,相较于时空分别进行注意力表现出了更好的性能;其次,支持图像和视频的统一生成,简化了训练过程,提高了模型的可扩展性;最后,更有效地利用了现有的LLM相关加速力能,提高了训练和推理效率。
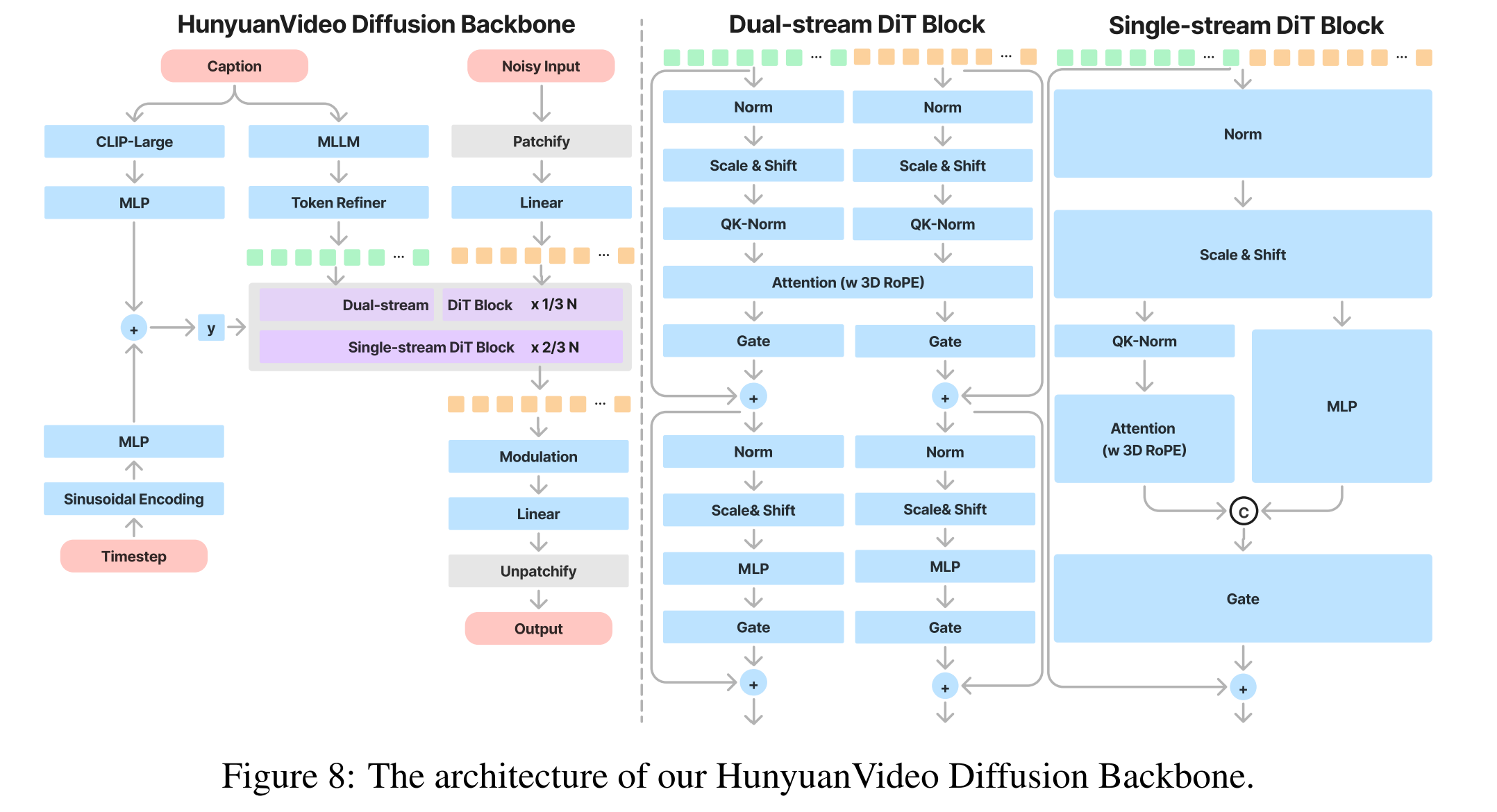
输入:对于给定的视频-文本对
对于视频分支,输入首先被压缩成形状为T × C × H × W的潜在空间。为了统一输入处理,将图像视为单帧视频。然后使用内核大小为的3D卷积分割成形状为的1D token序列。
对于文本分支,首先使用大语言模型将文本编码成一系列包含细粒度语义信息embedding。
同时,使用CLIP模型提取包含全局信息的文本向量,在送入模型之前,把它拼接到细粒度语义信息上,并加在timestep embedding上。
模型设计:为了有效地整合文本和视觉信息,使用了“双流到单流”混合模型设计的策略。
在双流阶段,视频和文本token通过多个Transformer块独立处理,使每种模态都能在不受干扰的情况下学习自己的合适调制机制。
在单流阶段,将视频和文本token连接起来,并将它们输入后续的Transformer块以实现有效的多模态信息融合。这种设计捕捉了视觉和语义信息之间复杂的交互,增强了整体模型性能。
位置Embedding:为了支持多分辨率、多宽高比和不同持续时间的生成,在每个Transformer块都使用Rotary Position Embedding(RoPE)。
RoPE在embeddings上使用旋转频率矩阵,增强了模型捕获绝对和相对位置关系的能力,并在LLM中展示了一些外推能力。将RoPE扩展到三个维度,分别为时间(T)、高度(H)和宽度(W)的坐标计算旋转频率矩阵。然后将查询和键的特征通道分割成三个部分(dt,dh,dw),将每个部分乘以相应的坐标频率并连接这些部分。这个过程产生了位置感知的查询和键embeddings,用于注意力计算。
2.3 Text Encoder
之前的文本到视频模型通常使用预训练的CLIP和T5-XXL作为文本编码器,其中CLIP使用Transformer编码器而T5使用编码器-解码器结构。相比之下,HunyuanVideo利用具有仅解码器结构的预训练多模态大语言模型(MLLM)作为文本编码器,这具有以下优点:
- 1) 与T5相比,经过视觉指令微调后的MLLM在特征空间中的图像-文本对齐更好,这减轻了扩散模型中指令跟随的难度;
- 2) 与CLIP相比,MLLM在图像细节描述和复杂推理方面表现出更强的能力;
- 3)MLLM可以作为zero-shot学习者,通过遵循用户提示前的系统说明,帮助文本特征更多地关注关键信息。
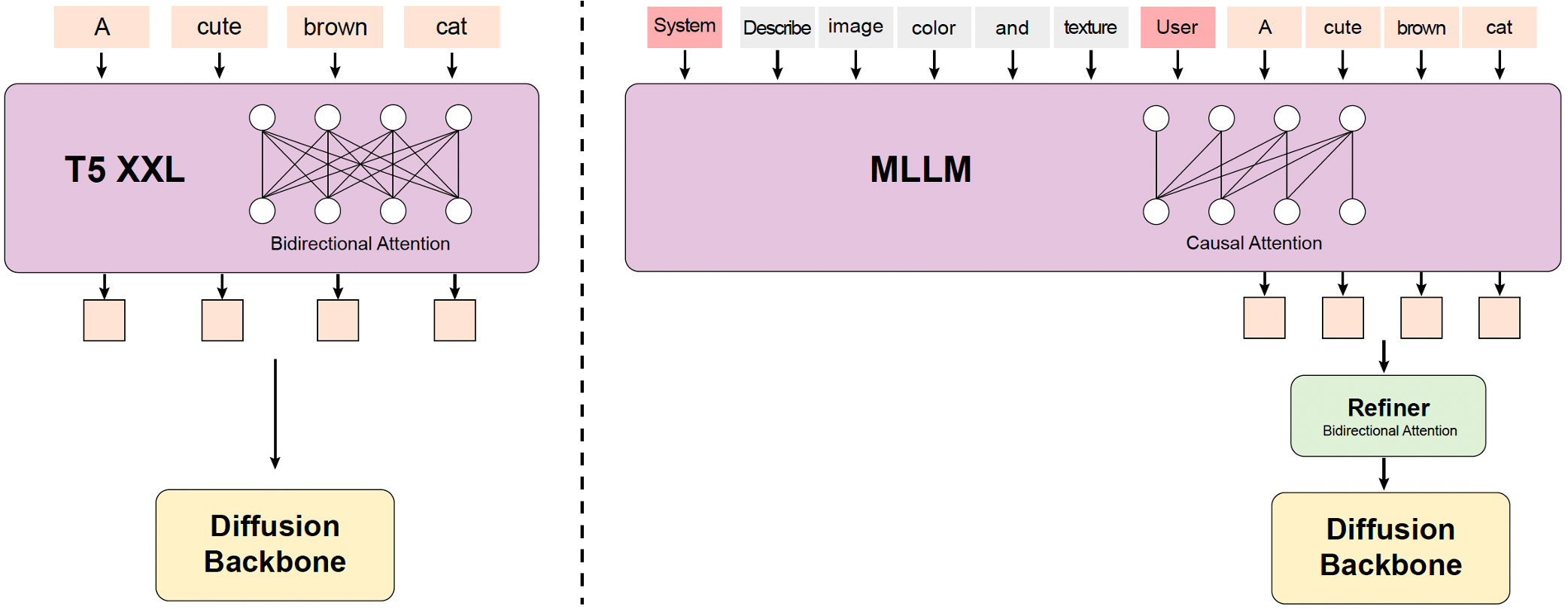
此外,如上图所示,MLLM基于因果注意力,而T5-XXL利用双向注意力为扩散模型提供了更好的文本指导。因此,又引入了一个额外的bidirectional token refiner来增强文本特征。
3、模型训练
3.1 预训练
HunyuanVideo使用Flow Matching进行模型训练,并将训练过程分为多个阶段。首先在256px和512px的图像上预训练模型,然后从256px到960px的图像和视频上进行联合训练。
3.1.1 训练目标
Flow Matching通过一系列概率密度函数的变量变换,将复杂的概率分布转换为简单的概率分布,并通过逆变换生成新的数据样本。
在训练过程中,给定训练集中的图像或视频的latent表示x1,我们首先从logit-normal
分布中采样t ∈ [0, 1],并初始化服从高斯分布 N(0, I)的噪声x0。然后使用线性插值的方法,重建出训练样本xt。模型被训练以预测速度ut = dxt/dt,指导样本xt逐渐变为样本x1。通过最小化预测速度vt和真实速度ut之间的均方误差来优化模型参数,损失函数如下:
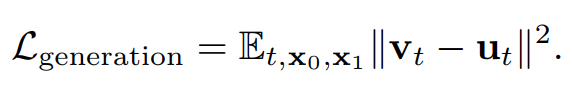
在推理过程中,初始化采样噪声样本x0 ∼ N(0, I)。然后使用一阶欧拉常微分方程(ODE)求解器,通过对模型的dxt/dt估计值进行积分来计算x1。该过程最终生成样本x1。
3.1.2 图像预训练
作者引入了一个两阶段渐进式的图像预训练策略,作为视频训练的热身。
图像阶段1(256px训练):模型首先使用低分辨率256px图像进行预训练。具体来说,使用不同宽高比的数据进行训练,这有助于模型生成具有广泛宽高比的图像,同时避免了图像预处理中由于裁剪操作造成的文本图像错位。同时,使用低分辨率样本进行预训练使模型能够从更多的样本中学习低频概念。
图像阶段2(混合比例训练):作者发现在512px图像上微调后的模型在256px图像生成上的性能会严重下降,这可能影响到随后基于256px的视频预训练。因此,作者进行了混合比例训练,其中每个训练全局批次包括两个或更多比例的多宽高比集合。每个比例都有一个锚定大小,然后基于锚定大小构建多宽高比集合。作者在两个比例的数据集上训练模型,学习更高分辨率的图像,同时保持对低分辨率的能力。作者还引入了动态批次大小,用于具有不同图像比例的微批次,最大化GPU内存和计算利用率。
3.2 视频图像联合训练
数据过滤过程之后,视频具有不同的宽高比和持续时间。作者创建了BT个持续时间集合和BAR个宽高比集合,总共有BT × BAR个 集合。由于不同集合中的token数量不同,作者为每个 集合分配了一个最大批次大小,以防止内存不足(OOM)错误,以优化GPU资源利用。在训练之前,所有数据都被分配到最近的 集合。在训练过程中,每个等级随机预提取 集合数据。这种随机选择确保模型在每一步都训练不同大小的数据,这有助于通过避免仅在单一大小上训练的限制来保持模型泛化。
直接从文本生成高质量、长时序的视频序列通常会导致模型收敛困难和次优结果。因此,渐进式学习已成为训练文本到视频模型的广泛采用策略。在HunyuanVideo中,设计了一个全面的课程学习策略。先使用T2I参数进行参数初始化,然后逐渐增加视频分辨率和时长。
- 低分辨率、短视频阶段。模型建立了文本和视觉内容之间的基本映射,确保短期动作的一致性和连贯性。
- 低分辨率、长视频阶段。模型学习更复杂的时间动态和场景变化,确保在更长时间内保持时间和空间的一致性。
- 高分辨率、长视频阶段。模型提高了视频分辨率和细节质量,同时保持时间连贯性,并管理复杂的时间动态。
此外,在每个阶段,都使用不同比例的图像进行视频-图像联合训练。这种方法解决了高质量视频数据的稀缺性,使模型能够学习更广泛和多样化的世界知识。它还有效地避免了由于视频和图像数据之间的分布差异而导致的图像空间语义的灾难性遗忘。
3.3 Prompt重写
为了解决用户提供的提示在语言风格和长度上的变化,作者使用Hunyuan-Large模型作为提示重写模型,以适应原始用户提示到模型偏好的提示。这个提示重写模块的关键功能如下:
- 多语言输入适应:该模块旨在处理和理解各种语言的用户提示,确保保留意义和上下文。
- 标准化提示结构:该模块重述提示,使其符合标准化的信息架构,类似于训练中的字幕。
- 简化复杂术语:该模块将复杂的用户措辞简化为更直接的表达方式,同时保持用户的原始意图。
3.4 High-performance Model Fine-tuning
作者仔细选择了整个数据集中的四个特定子集进行微调。这些子集首先使用自动化数据过滤技术进行筛选,然后进行手动审查。然后使用这个数据集进行微调。

















 558
558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









