






 这篇教程详细介绍了如何重置Windows 10和7系统的步骤。对于Win10,用户需要按Win+R打开运行窗口,输入`systemreset`,选择删除所有内容并备份重要数据。对于Win7,同样按Win+R输入`sysprep`,启动系统准备工具,然后按照提示进行操作。无论台式机还是笔记本,都可以通过这些方法恢复系统出厂设置,解决系统故障问题。此外,还提供了一键重置的便捷选项供用户选择。
这篇教程详细介绍了如何重置Windows 10和7系统的步骤。对于Win10,用户需要按Win+R打开运行窗口,输入`systemreset`,选择删除所有内容并备份重要数据。对于Win7,同样按Win+R输入`sysprep`,启动系统准备工具,然后按照提示进行操作。无论台式机还是笔记本,都可以通过这些方法恢复系统出厂设置,解决系统故障问题。此外,还提供了一键重置的便捷选项供用户选择。
我们知道win10系统提供系统重置的选项,但是使用win7系统的小伙伴就不知道如何重置win7系统了,其实小编已经把win10和win7系统重置的方法都整理成教程文章,帮助你恢复系统出厂设置,希望对你有所帮助。
电脑使用时间长了,会出现意想不到的系统小问题,比如无法打开程序、关机慢、运行卡顿等等,很多朋友不习惯定期清理垃圾,就会出现上述的情况,小编建议你通过系统自带的重置方式恢复系统出厂设置,下面一起看下具体操作步骤吧。
电脑系统怎么重置呢?很多大品牌的笔记本电脑都提供可快速重置系统的方法,比如联想、惠普等等,通过特殊的启动方式重置系统,那么台式电脑如何重置系统呢?其实台式电脑系统重置也并不是很复杂,接着小编给大伙带来系统重置的方法。
很多小伙伴的电脑出现系统故障的时候都喜欢ghost重装电脑,对于不懂ghost重装系统的朋友来说,还有没有其他办法解决系统故障呢?下面,就随小编看看电脑系统重装的具体操作方法,帮助各大网友解决系统问题。
PS:如果觉得下面的重置方法麻烦看不懂,可以尝试这个一键重置的方法哦。
以下是关于电脑系统重置的方法:
win10系统重置方法
1、同时按下键盘快捷键Win+R,打开运行窗口输入【systemreset】回车确定。
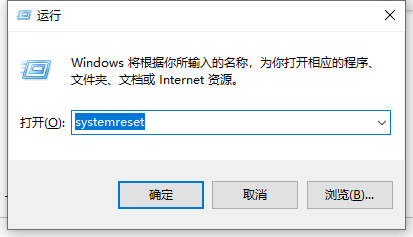
系统重装电脑图解1
2、出现的弹窗中,我们选择 删除所用内容,请注意,在操作前请把系统盘上面的资料备份好哦,下图所示:
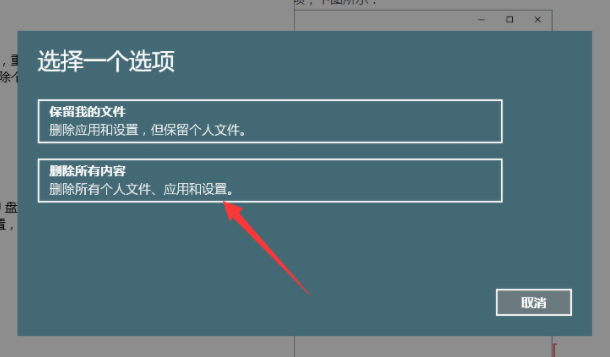
系统重装电脑图解2
3、然后等待安装完成就可以重置系统哦。
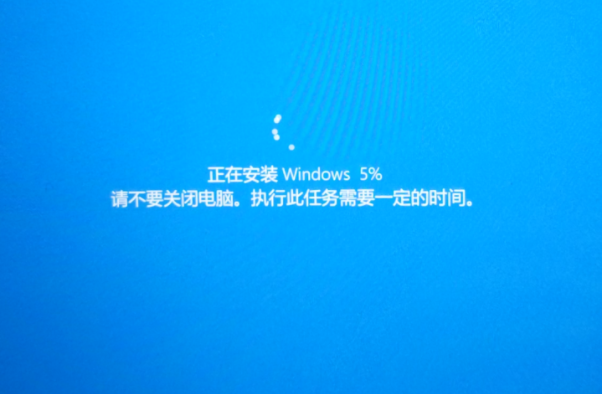
重置系统电脑图解3
win7系统重置方法
1、同时按下键盘快捷键Win+R,打开运行窗口输入【sysprep】回车确定
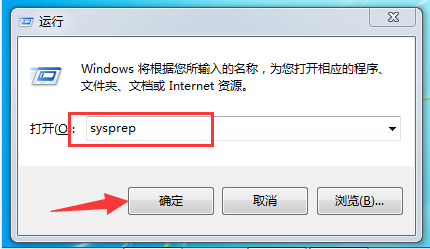
重置系统电脑图解4
2、打开的文件夹中双击打开【sysprep】程序。
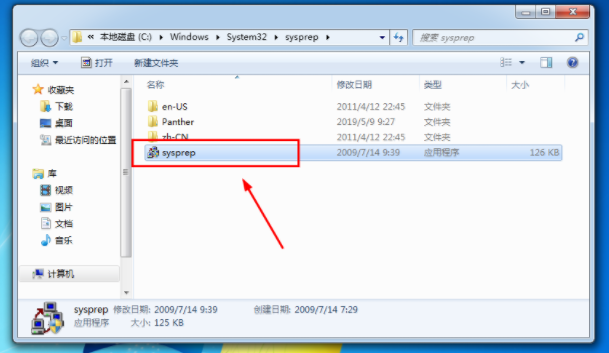
系统重装电脑图解5
3、出现系统准备工具,直接点击【确定】。
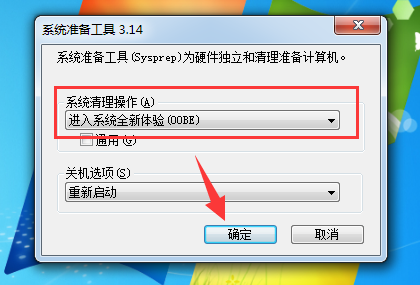
重置系统电脑图解6
4、耐心等候sysprep工作完成,自动重启。

重置系统电脑图解7
5、重启后开始安装系统,根据提示操作即可。
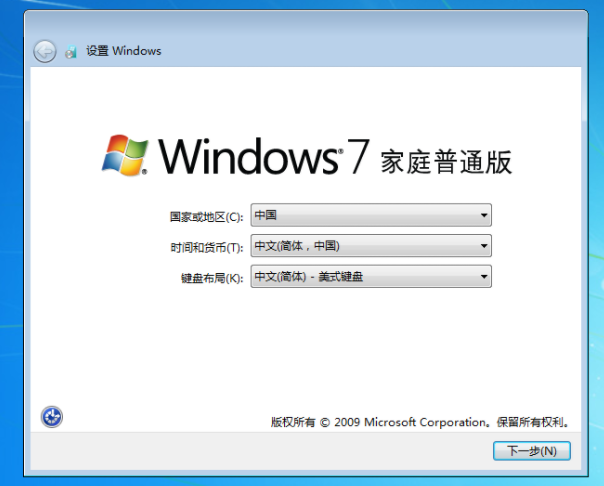
系统重装电脑图解8
以上就是关于电脑系统重置的方法。

















 2120
2120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









