







1. 训练,验证,测试集
2. 偏差,方差
3. 机器学习基础
4. 正则化
5. 为什么正则化预防过拟合
6. dropout(随机失活)正则化
7. 理解 dropout
8. 其他正则化
9. 归一化输入
10. 梯度消失 / 梯度爆炸
11. 神经网络权重初始化
12. 梯度的数值逼近
13. 梯度检验
14. 梯度检验的注意事项
参考:吴恩达视频课深度学习笔记
1. 训练,验证,测试集
深度学习是一个典型的「迭代过程」,迭代的「效率」很关键
创建高质量的「训练数据集」,「验证集」和「测试集」有助于提高循环效率
- 切分标准:「小数据」量时代,常见做法是三七分,70%验证集,30%测试集;也可以 60%训练,20%验证和20%测试集来划分。「大数据」时代,数据量可能是百万级别,验证集和测试集占总量的比例会趋于变得更小。我们的目的就是验证不同的算法,检验哪种算法更有效,不需要拿出20%的数据作为验证集,很少的一部分占比的数据就已经足够多了。
- 数据来源:最好要确保 验证集 和 测试集 的数据「来自同一分布」,因为要用验证集来评估不同的模型,如果验证集和测试集来自同一个分布就会很好
2. 偏差,方差
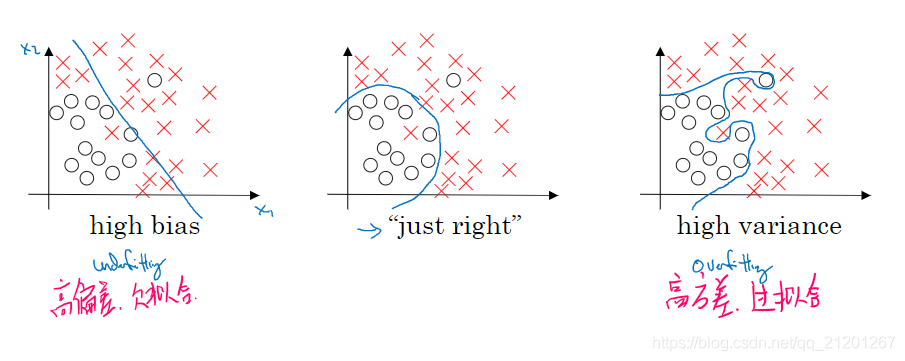 关键数据:训练集误差、验证集误差
关键数据:训练集误差、验证集误差
 如果「最优误差」(贝叶斯误差,人分辨的最优误差)非常高,比如15%。那么上面第二种分类器(训练误差15%,验证误差16%),15%的错误率对训练集来说也是非
如果「最优误差」(贝叶斯误差,人分辨的最优误差)非常高,比如15%。那么上面第二种分类器(训练误差15%,验证误差16%),15%的错误率对训练集来说也是非
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 787
787











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









