





下个星期课变得好少,我最爱的咸鱼生活开始喽~~~
接上上次的牛顿法,这次开始的两篇文章写写拟牛顿法。
目录:
- 拟牛顿法
- 拟牛顿法框架
- 拟牛顿法是在
下的最速下降法
- 几种经典的拟牛顿算法
- SR1
- DFP
- BFGS
- SR1,DFP,BFGS之间的关系
- Broyden族
- 代码实现三种拟牛顿算法
拟牛顿法
回顾一下牛顿法的表达式:
拟牛顿法(Quasi-Newton methods)的思路就是通过在牛顿法的迭代中加入近似求取每一步Hessian矩阵的迭代步,仅通过迭代点处的梯度信息来求取Hessian矩阵的近似值。现在我们把Hessian矩阵在第
拟牛顿法框架
有了之前的认识,我们可以大致写出拟牛顿法的算法过程。
当然,你也可以在更新迭代点时增加步长因子,使其变成阻尼拟牛顿法:
如何根据处的信息更新
会在后面讲到,它确定了具体的拟牛顿法。
拟牛顿法是
在具体展开有哪些可以使用的拟牛顿法之前,我觉得我们可以对牛顿法和拟牛顿法来做个比较,来获取一些拟牛顿法本身的性质亦或是难能可贵的认识,这会是在实际工程应用中难以获取的。
我们完全可以从另一个角度来看这个问题,类似于牛顿法的推导过程,我们现在处在迭代点
为了使得,此处默认
![]()
也就是说,在误差允许的情况下(不要太大,Taylor展开式的领域近似,懂的都懂,不懂的我也没有办法=_=),
故,在我们将
由于每次迭代时的都会变化,那么度量
变尺度法的范数也会随之变化,因此,我们会将这样的方法称为
那么当
几种典型的拟牛顿算法
还记得在拟牛顿法框架中讲到的模糊不清的最后一步——“根据
下面介绍三种具体的拟牛顿法,而推导它们的关键则是确定如何迭代得到每步迭代点Hessian矩阵逆矩阵的倒数
首先做几个符号的规定,来为我们后续的推导做符号运算上的简化。记
很明显,我们就有:
SR1
SR1的全称为Symmetric Rank-One,是William C. Davidon在1956年提出的,但由于缺少收敛性分析,所以Davidon的论文被拒稿,导致SR1算法没能成为第一个公认的拟牛顿法。
SR1确定迭代式的逻辑比较简单——根据
而SR1算法就直接把这个对称矩阵
很显然
我们在①的两边乘上
其中
将③和⑤代入①中可得:
结合之前的拟牛顿法框架,我们可以整合出SR1算法的具体步骤:
SR1虽然能近似
DFP
DFP是其发现者Davidon, Fletcher, Powell的开头大写字母拼成的,也是第一个公认的拟牛顿法。
其基本思路和SR1差不多,也是想着确定一个对称矩阵修正量
那么接下来和推导SR1一样咯,我们在①式的两边右乘上
接下来便是确定
对于
同理我们也可以得到
将
DFP的推导过程看似随意,但是DFP的迭代公式也可以通过如下的优化问题的解得到:
结合之前的拟牛顿法框架,我们可以整合出DFP算法的具体步骤(水行数警告):
BFGS
BFGS这个算法的记忆没有诀窍=_=,因为它是下面这四个人分别提出的,所以和DFP一样,用四个人的名字的开头字母命名。

其推导其实和DFP一样,不过BFGS是从
对于
那么我们要求的

我们可以递归地使用上面的式子,令
SR1, DFP, BFGS之间的关系
有了之前的SMW公式,我们可以尝试求取上述的三个拟牛顿法的
SR1的迭代式为
因此,我们说SR1是自对偶的。
再看看DFP和BFGS迭代公式两边取逆后的结果:
可以看到DFP和BFGS公式高度对称,只需
因此,我们说DFP和BFGS互为对偶。
Broyden族
既然DFP和BFGS是互为对偶的,那用哪一个比较好呢?你当然可以通过若干组实验来测试哪个的性能的更优,或者对其收敛一通验证。但是一个比较的朴素的做法就是“我都要”,也就是取DFP迭代式和BFGS迭代式的正加权组合:
随着
而且根据定义,
代码实现三种拟牛顿算法(Python)
终于到了我最爱的编程环节了,这次我们就不像上次的梯度下降法一样造轮子了,我们直接调取写好的优化库来快速完成项目需求。
因为笔者是个Python小白,所以关于数值优化的Python第三方库我知道如下三个:cvxpy,cvxopt,scipy。其中scipy.optimize子库有关于优化的算子。
由于上述的三个库都是基于numpy库开发的,所以在调用pip指令安装时,请先安装numpy库
我翻了一上午的源代码和document,并没有在cvxpy和cvxopt中找到关于拟牛顿法的算子。因此,笔者下面采用scipy.optimize来实现三种拟牛顿法。如果你没有安装相关的依赖库,请打开命令行,输入以下命令来自动安装(请确保你的Python解释器的Script文件夹的路径已被添加到环境变量Path中):
pip install numpy, matplotlib, scipy -i https://pypi.tuna.tsinghua.edu.cn/simple此处我们分别使用SR1,DFP和BFGS拟牛顿法优化如下的函数:
其中
已知上述的优化问题的最优点为
我们首先先实现上述的函数,我通过一个函数获取一个映射
下面所有的代码都写在一个文件中
# -*- utf-8 -*-
# date: 2020-10-22
# author: 锦恢
from scipy.optimize import fmin_powell, fmin_bfgs, fmin_cg, minimize, SR1
import numpy as np
import matplotlib.pyplot as plt
def r(i, x):
if i % 2 == 1:
return 10 * (x[i] - x[i - 1] ** 2) # 因为ndarray数组的index是从0开始的, i多减一个
else:
return 1 - x[i - 2]
def f(m):
def result(x):
return sum([r(i, x) ** 2 for i in range(1, m + 1)])
return result通过
为了观察拟牛顿法运行过程中迭代点的下降情况,我们需要计算
# 获取retall的每个点的值损失|f(x) - f(x^*)|
def getLosses(retall, target_point, func):
"""
:param retall: 存储迭代过程中每个迭代点的列表,列表的每个元素时一个ndarray对象
:param target_point: 最优点,是ndarray对象
:param func: 优化函数的映射f
:return: 返回一个列表,代表retall中每个点到最优点的欧氏距离
"""
losses = []
for point in retall:
losses.append(np.abs(func(target_point) - func(point)))
return lossesscipy.optimize子库中的许多执行拟牛顿法的算子提供了call_back参数,该参数要求传入一个函数对象,在拟牛顿每步迭代完后,传入的call_back函数会被调用。由于使用SR1法的算子minimize无法返回迭代过程中的每一个迭代点(也就是retall),于是我们需要call_back函数来将迭代完的点传入外部的列表,从而获取SR1的retall。除此之外,我们可以使用call_back函数来指定迭代停止的条件。
我们编写一个返回函数对象的函数,它会根据我们传入参数的不同返回不同的call_back函数:
sr1_losses = [] # 存储SR1的retall的列表
func = f(4) # 获取需要优化的函数
# 通过callback方法来添加迭代的停止条件
def getCallback(func, target_point, ftol, retall):
"""
:param func: 优化目标的函数
:param target_point: 目标收敛点
:param ftol: 收敛条件:|f(x) - f(x^*)| < ftol时,迭代停止
:param retall: 是否存储迭代信息
:param extern_retall: 如果retall为True, 填入一个列表,迭代信息会存在这个列表中
:return: call_back函数对象
"""
def result(xk, state=None):
if retall:
global func, sr1_losses
loss = np.abs(func(target_point) - func(xk))
if loss < ftol:
return True
else:
if retall:
sr1_losses.append(loss)
return False
return result为了方便可视化,我们将数据可视化的逻辑封装到一个函数中:
# 绘制下降曲线
def plotDownCurve(dpi, losses, labels, xlabel=None, ylabel=None, title=None, grid=True):
plt.figure(dpi=dpi)
for loss, label in zip(losses, labels):
plt.plot(loss, label=label)
plt.xlabel(xlabel, fontsize=12)
plt.ylabel(ylabel, fontsize=12)
plt.title(title, fontsize=18)
plt.yscale("log")
plt.grid(grid)
plt.legend()接着我们定义一下迭代初值、最优点和终止条件的阈值
call_back函数。
x_0 = np.array([1.2,1.0,1.0,1.0]) # 迭代初值
target_point = np.array([1,1,1,1], dtype="float32") # 最优点
FTOL = 1e-8 # 终止阈值
sr1_callback = getCallback(func, target_point, ftol=FTOL, retall=True)
dfp_callback = getCallback(func, target_point, ftol=FTOL, retall=False)
bfgs_callback = getCallback(func, target_point, ftol=FTOL, retall=False)下面我们我们使用minimum,fmin_powell,fmin_bfgs来实现三种拟牛顿法的迭代,并把DFP和BFGS的retall存入列表中。
minimum = minimize(fun=f(4), x0=x_0, # 通过minimize函数执行SR1,根据内嵌的callback填充loss,并返回OptimizerResult对象
method="trust-constr",
hess=SR1(),
callback=sr1_callback)
dfp_minimum, dfp_retall = fmin_powell(func=func, x0=x_0,
retall=True,
disp=False,
callback=dfp_callback)
dfp_losses = getLosses(dfp_retall, target_point, func=func)
bfgs_minimum, bfgs_retall = fmin_bfgs(f=func, x0=x_0,
retall=True,
disp=False,
callback=bfgs_callback)
bfgs_losses = getLosses(bfgs_retall, target_point, func=func)迭代做完后,我们自然想知道结果如何,可视化是一个直观的方法,我们将plt画布的分辨率调为150,设置一下各个轴的名称,将它可视化出来:
plotDownCurve(dpi=150,
losses=[sr1_losses, dfp_losses, bfgs_losses],
labels=["SR1", "DFP", "BFGS"],
xlabel="#iter",
ylabel="value of $|f(x) - f(x^*)|$",
title="losses curve of SR1, DFP and BFGS")
plt.show() out:
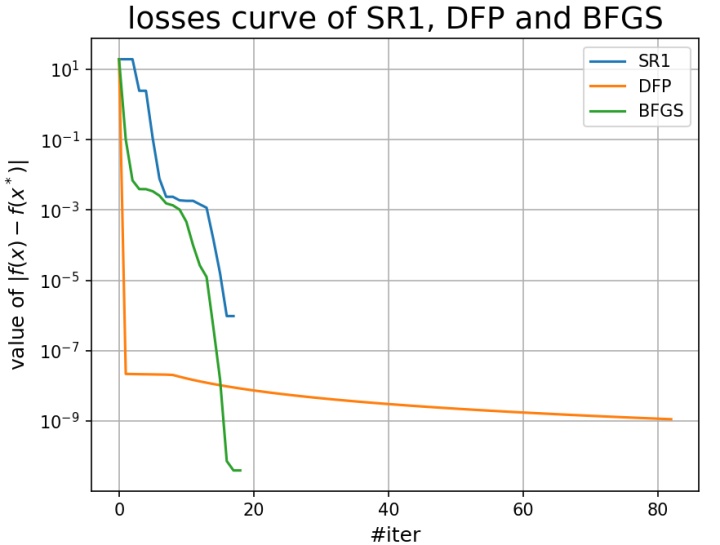
我们可以查看三种方法得到的最优点和它们具体的迭代次数:
print(f"SR1t最终迭代点:{minimum.x.tolist()}, 共经历{minimum.cg_niter}次迭代")
print(f"DFPt最终迭代点:{dfp_minimum}, 共经历{len(dfp_losses)}次迭代")
print(f"BFGSt最终迭代点:{bfgs_minimum}, 共经历{len(bfgs_losses)}次迭代")out:
SR1 最终迭代点:[0.9999962062462336, 0.9999929560009194, 0.9999943517470878, 0.9999915182271095], 共经历35次迭代
DFP 最终迭代点:[0.99998036 0.99996341 1. 1. ], 共经历83次迭代
BFGS 最终迭代点:[0.99999547 0.9999909 0.99999572 0.99999144], 共经历19次迭代可以看到三种方法都成功收敛到了

















 3893
3893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









