







rappor是谷歌研发的用于收集用户回答的LDP协议,例如 设定哪个页面为浏览器的homepage、搜索引擎等。
LDP的一个基本目标是频度估计
LDP的协议基本可以分为三个步骤:编码、随机化、聚集
文中提到的攻击:heavy hitter identification 和 frequent itemset mining
Basic rappor
basic rappor也是这三个步骤
编码使用的是一元编码、扰动分为两个部分:永久和顺时==(?)== 聚集中的==-1/2fn==
permanent randomized response的作用
本地化差分隐私保护技术首先在每个用户端对个人数据进行隐私化处理,如Tom 将以40%的概率提交“艾滋病”,分别以10%的概率提交其余 6 种疾病,如此一来,Tom 所提交的数据就具有了一定的随机性,从而保护了敏感信息。
这里应该就是昨天看的那个spinner的意思了吧
永久扰动,只执行一次。目前看到过两种写法

这篇是2017年的软件学报综述中所用的
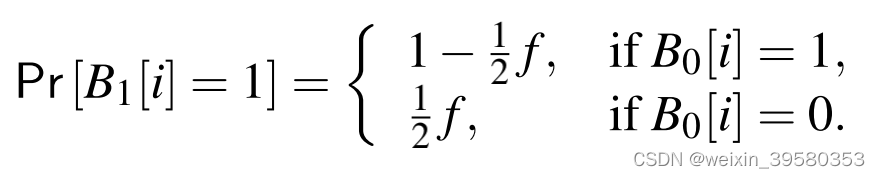
这个是Locally Differentially Private Protocols for Frequency Estimation中所给的,这里1-1和0-0的概率是相同的 都是1-1/2f
但是具体为什么要有一个永久的扰动呢?
每次报告值 V 时,都重用位向量 B,使用瞬时随机响应计算长度为 k 的实际响应位向量 S 瞬时随机响应是利用随机响应参数 p,q 扰动 B′的每一位得到实际响应位向量。
是否是每次都是直接扰动的话多次会推测出原值?
这里需要看下代码或看跑出来的结果吧
瞬时扰动
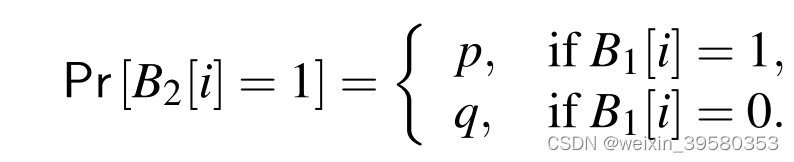
这里1-1是p 0-1是q p + q = 1
0-1是1-q 1-0是1-p 可是 这也是对称吗
扰动后再发给aggregator
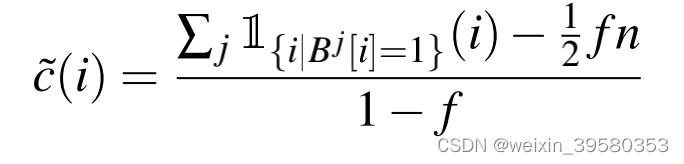
这里为什么要-1/2fn啊
rappor
basic rapor对数据维度较大时表现的不是很好,所以rappor采用bloom filter, bloom filter其实是一种 判断含有某个元素的数据结构。Bloom Filter是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。Bloom Filter的这种高效是有一定代价的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。(这里是别人的笔记写的)
隐私里为什么要用bloom filter 文中解释是 membership testing 有道理,这也是rappor和basic rappor之间的区别吧,rappor的motiation中也有这一点。
rappor 也是三个步骤

















 4469
4469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









