





过去的十多年中,深度学习领域的创新,海量数据的便捷可用性和 GPU 单元的可访问性,已经将计算机视觉领域推到了镁光灯下。它甚至已经开始在某些任务中实现了傲人的性能,比如人脸识别和验证(实际上,用于身份确认的自动人脸验证如今已变得越来越普遍了)。
近年来,在计算机视觉领域中,在网络架构、激活函数、损失函数等方面都看到了很多创新性工作。其中,损失函数在模型的性能中扮演着一个至关重要的角色。选择正确的损失函数可以帮助你的模型学会关注数据中正确的特征集,从而实现最优和更快的收敛。
本文旨在总结计算机视觉中使用的一些重要的损失函数。你可以在这个链接[1]中找到这里讨论的所有损失函数的 PyTorch 实现。
1像素级损失函数
顾名思义,这种损失函数计算预测图像和目标图像在像素级别上的损失。一般用到的大部分损失函数,如 MSE 或 L2 损失,MAE 或 L1 损失,交叉熵损失等,都可以应用于每一对预测和目标图像的像素之间。
由于这些损失函数分别评估每个像素向量的类预测,然后对所有像素取平均,因此可以断言图像中每个像素的学习是平等的。这些在图像的语义分割中特别有用,其中模型需要学习像素级的密集预测。
这些损失函数的变体也被用于像 U-Net[2] 这样的网络中,其中采用加权像素交叉熵损失来解决用于图像分割时的类不平衡问题。
类不平衡性是像素级分类任务中的常见问题。当图像数据中的各种类不平衡时,就会出现这种情况。由于像素级损失平均了所有像素的损失,因此训练往往会由最普遍的类主导。
2感知损失函数
由 Johnson 等人(2016)引入的感知损失函数[3],用于比较两张看起来相似但不同的图像,例如同一张照片但是移动了一个像素,或者相同的图像跨越不同的分辨率。在这些情况下,尽管图像非常相似,像素级损失函数将输出一个较大的误差值,而感知损失函数则比较图像之间的高级感知和语义差异。
考虑像 VGG 这样的图像分类网络,它已经在 ImageNet 数据集的数百万张图像上进行了训练,第一层的网络倾向于提取低层特征(如线、边缘或颜色梯度),而最后的卷积层会对更复杂的概念(如特定的形状和图案)作出反应。根据 Johnson 等人的说法,在前几层捕获的低级特征对于比较非常相似的图像很有帮助。
例如,假设你创建了一个网络来从输入图像构建一个超分辨图像。在训练期间,你的目标图像将是输入图像的超分辨版本。你的目标是比较网络的输出图像和目标图像。为此,我们将这些图像传递给一个预先训练好的 VGG 网络,并提取 VGG 中前几个块的输出值,从而提取图像的低层特征信息。这些低级特征张量可以用一个简单的像素级损失来比较。
01感知损失的数学表示
假设有真实图像 和预测图像 ,感知损失为,
其中, 表示对于输入图像 ,VGG 网络的第 层的激活,并且具有形状 。我们使用平方 L2 损失,通过图像的形状归一化,比较真实图像 和预测图像 的激活。
如果你想使用 VGG 网络的多个特征图作为损失计算的一部分,只需将多个 的 值相加即可。
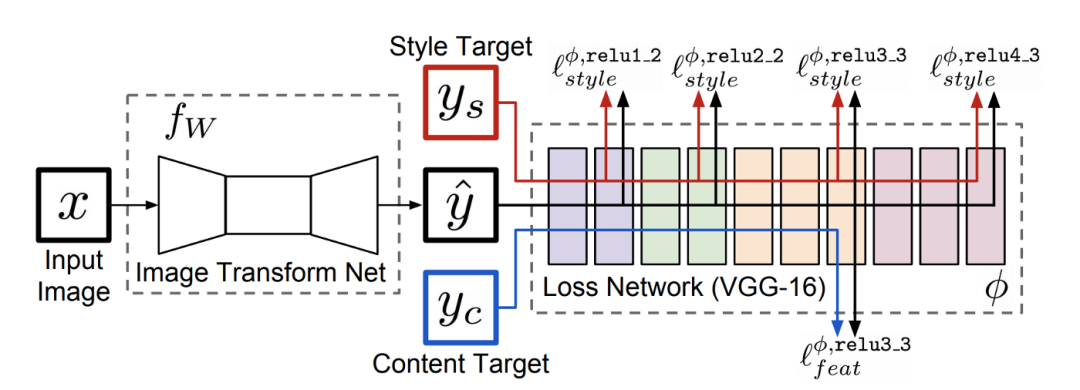
3内容风格损失函数

风格迁移是将图像的语义内容呈现为不同风格的过程。风格迁移模型的目标是,给定一张内容图像()和一张风格图像(),生成包含 内容和具有 风格的输出图像。
这里,我们讨论用于训练这种风格迁移模型的 Content-Style 损失函数的最简单实现之一。Content-Style 损失函数的许多变体已用于其他研究中。下一节将讨论这样的损失函数,称为纹理损失。
02Content-Style 损失的数学表示
研究已发现,CNN 在较高层捕获有关内容的信息,而在较低层则更关注于单个像素值。
因此,我们采用 CNN 的一层或多层,并计算原始内容图像()和预测输出()的激活图:
类似地,可以通过将预测图像()和风格图像()的较低层特征图的 L2 距离来计算风格损失。最终的损失函数定义为,
这里的 和 是可以调整的超参数。
注意: 仅考虑风格和内容损失的优化会导致高度像素化和带噪的输出。为了解决这个问题,引入了全变分损失[4],以确保所生成图像的空间连续性和平滑度。
4纹理损失函数
风格损失[5]被 Gatys 等人于 2016 年首次引入,以实现图像风格迁移。
纹理损失是作为感知损失的改进版而引入的损失函数,特别适用于捕获图像风格。Gatys 等人发现,我们可以通过查看激活或(来自 VGG 网络的)特征图的空间相关性来提取图像的风格表示。这是通过计算 Gram 矩阵完成的,
关于 VGG 网络的第 层的 Gram 矩阵就是第 层中的特征图 和 矢量化后的内积。Gram 矩阵描述了特征在图像不同部位的相关性。
03纹理损失的数学表示
第 层的纹理损失 为,
其中, 和 分别是模型输出的第 层和目标图像的第 层的风格表示。 是第 层中不同特征图的数量, 是第 层中特征图的体积(即 通道宽度高度)。
总的纹理损失是所有层纹理损失的加权总和,表示如下,
这里, 是原始图像, 是预测的图像。
注意: 尽管此处的数学公式看起来有些复杂,但纹理损失可以理解成仅仅是应用于特征图的 Gram 矩阵的感知损失。
5拓扑感知损失函数
最近的文献中,另一个有趣的损失函数是拓扑感知[6](Topology-aware)损失函数,由 Mosinska 等人于 2017 年引入。可以将其视为感知损失的扩展,应用于分割掩模的预测。
Mosinska 等人认为,在图像分割问题中使用的像素级损失(例如,交叉熵损失),仅依赖于局部测量,而不考虑拓扑的特征,例如连接的组件或孔的数量等。结果,传统的分割模型(例如 U-Net)会倾向于对薄结构进行错误分类。这是因为就像素级损失而言,对像素薄层进行错误分类的惩罚代价很低。作为对像素级损失的一种改进,他们建议引入一个基于 VGG-19 网络生成的特征图(类似于感知损失)的惩罚项,来考虑拓扑信息。
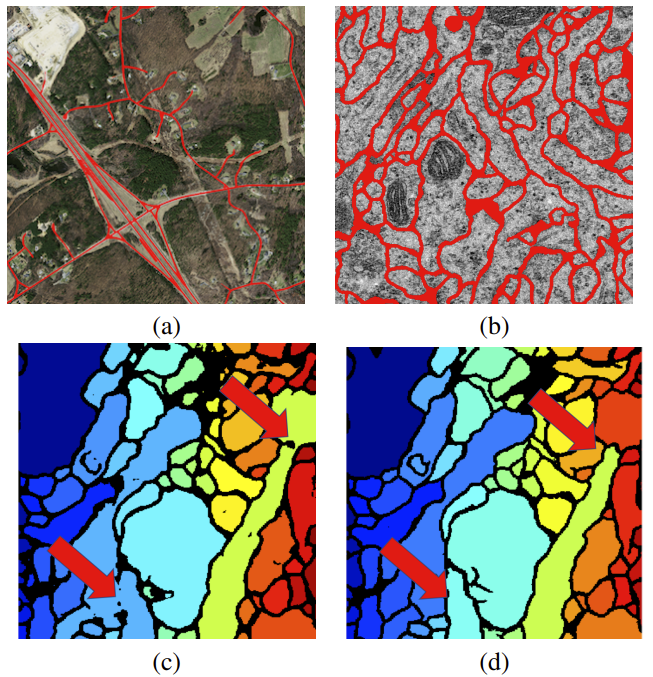
该方法也特别适用于从卫星图像中分割道路,例如被树木遮挡的情况。
04拓扑感知损失的数学表示
假设真实和预测分别为 和 ,可以如下计算损失,
在上式右边, 代表 VGG-19 网络第 层中第 个特征图。 是一个标量,衡量像素损失和拓扑损失的相对重要性。
6Triplet 损失
Triplet 损失是由 Florian Schroff 等人在 FaceNet[7] 中于 2015 年引入,目的是建立一个包含有限数据集且规模较小的人脸识别系统,例如针对办公室中的人脸识别系统。在这种情况下,用于人脸识别的传统 CNN 架构往往行不通。
Florian Schroff 等人关注的事实是,在一个很小的人脸识别样本空间中,我们不仅必须正确识别人脸匹配,而且还要准确地区分两张不同的人脸。为了解决这个问题,FaceNet 论文引入了一个称为 Siamese 网络的概念。
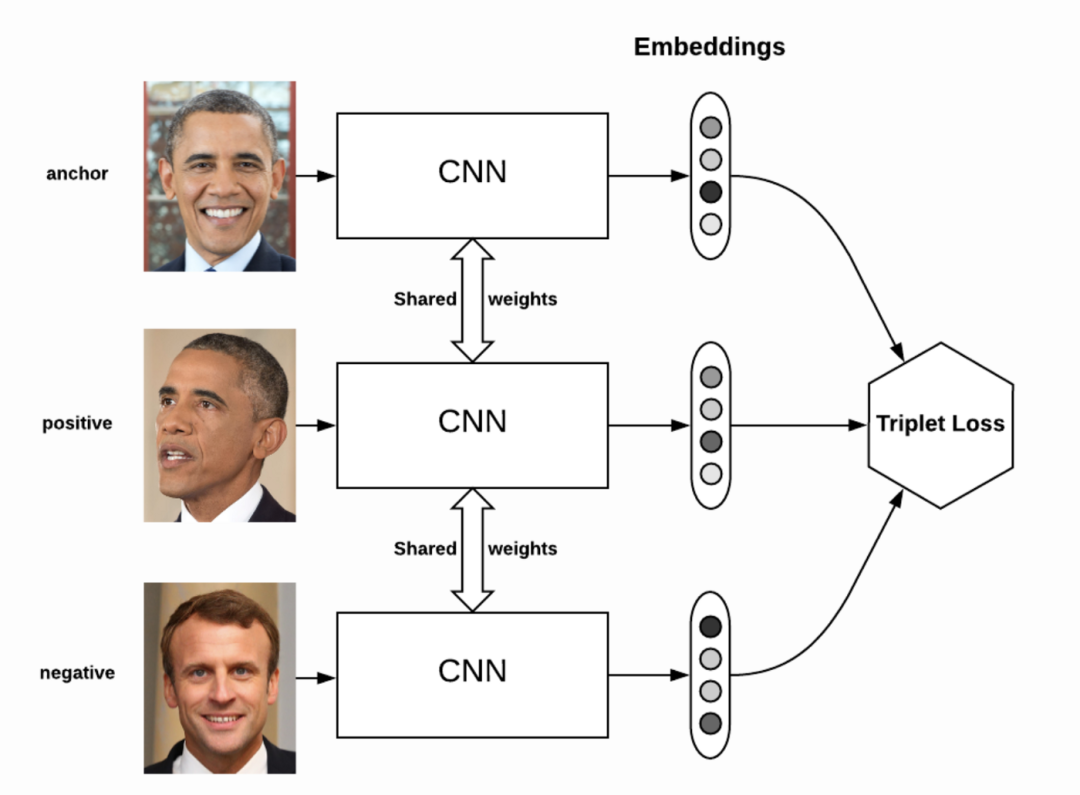
在 Siamese 网络中,我们通过网络传递图像 A,然后转换为较小的表示形式,称为嵌入。现在,在不更新网络任何权重或偏差的情况下,我们对其他图像 B 重复此过程,并提取其嵌入。如果图像 B 与图像 A 属于同一个人,则它们的相应嵌入也必须非常相似。如果他们是不同的人,那么图像的嵌入之间的差异应该比较大。
重申一下,Siamese 网络旨在确保某个人 (anchor)的图像比同一个人的其他图像 (positive)更接近,而不是与任何其他人的图象 (negative)更接近。
为了训练这样的网络,他们引入了一个所谓的 Triplet 损失函数。考虑一个三重态 — (见图)。通过这三个图像来定义损失函数,如下所示,
- 1、定义距离度量 d = L2 范数
- 2、计算 anchor 图像和 positive 图像的嵌入之间的距离为
- 3、计算 anchor 图像和 negative 图像的嵌入之间的距离为
- 4、Triplet 损失 = d(a,p) - d(a,n) + 偏移
05Triplet 损失的数学表示
假设给定一些三元组训练数据,可以如下计算损失,
其中, -> anchor, -> postive 和 -> negative 。
注意: 要实现快速收敛,对用于计算损失的正确的三元组进行采样至关重要。FaceNet 论文讨论了实现此目的的两种方法,即三元组的线下生成方式和在线生成方式。具体你可以参考 FaceNet 论文。
7GAN 损失
生成对抗网络[8](Generative Adversarial Network,简称 GAN),最早由 Ian Goodfellow 等人于 2014 年提出。是迄今为止最普及的图像生成任务解决方案。GAN 受到博弈论的启发,并采用对抗性方案,因此可以用无监督的方式训练它们。
GAN 可以被视为两人游戏,我们将生成器(例如产生超分辨率图像)与另一个网络 — 鉴别器进行对比。鉴别器的任务是评估图像是来自原始数据集(真实图像)还是由其他网络生成的(伪造图像)。鉴别器模型像其他任何深度学习神经网络一样进行更新,尽管生成器使用鉴别器作为损失函数,这意味着生成器的损失函数是隐式的,并且是在训练期间学习的。通常对于机器学习模型,收敛被视为在训练数据集上所选损失函数的最小化。在 GAN 中,收敛标志着两人游戏的结束。取而代之的是寻求生成器和鉴别器损耗之间的均衡。
对于 GAN,生成器和鉴别器是两个角色,它们轮流更新其模型的权值。下面我们将总结一些用于 GAN 网络的损失函数。
- 1、最小 — 最大损失函数(Min-Max Loss Function)
然而,在实际应用中,发现生成器的损耗函数存在饱和现象。也就是说,如果它不能像鉴别器一样快速地学习,鉴别器获胜,游戏结束,并且模型不能得到有效的训练。
- 2、非饱和 GAN 损失(Non-Saturating GAN Loss)
非饱和 GAN 损耗是对生成器损失的一种改进,以便克服饱和问题。生成器不是使生成图像的鉴别器反向概率对数最小化,而是使生成图像的鉴别器概率对数最大化。
- 3、最小二乘 GAN 损失 (Least squares GAN Loss)
由 Mao 等人于 2016 年引入[9],当生成的图像和真实的图像有很大的差异时,此损失函数特别有用,这会导致很小或者消失的梯度,从而对模型的更新很少或几乎没有更新。
- 4、Wasserstein GAN 损失
该损失由 Martin Arjovsky 等人于 2017 年引入[10]。他们观察到,传统的 GAN 是为了最小化真实图像和生成图像的实际概率分布和预测概率分布之间的距离,即所谓的 KL-散度。相反,他们建议在 Earth-Mover[11] 距离上对问题建模,从而根据该距离来计算将一个分布转换成另一个分布的成本。
使用 Wasserstein 损失的 GAN 涉及到将鉴别器改为评估器,评估器的更新频率比生成器模型的更新频率要高(例如,更新频率高 5 倍)。此评估器用一个实数给图像打分,而不是预测概率。它还要求模型的权重保持较小。通过计算分数,使真实图像和伪造图像之间的分数距离得到最大限度的分离。Wasserstein 损失的好处是,它几乎在任何地方都提供了一个有用的梯度,允许对模型进行持续有效的训练。
- 5、循环一致损失(Cycle Consistency Loss)
图像到图像的翻译是一种图像合成任务,它需要生成一张新图像,且该图像是对给定图像的可控转换。

例如,把马翻译成斑马(或反过来),把绘画翻译成照片(或反过来),等等。
该损失由朱俊彦等人于 2018 年在实现图像到图像之间的翻译任务[12]中引入。训练一个图像到图像的翻译通常需要大量成对示例的数据集,而一般情况这些例子很难找到。CycleGAN 是一种无需成对例子的自动训练技术,且使用源和目标域中不需要成对的图像集合,以无监督的方式训练模型。
CycleGAN 是 GAN 架构的扩展,它涉及到同时训练两个生成器模型和两个鉴别器模型。一个生成器从第一域获取图像作为输入并输出第二个域的图像,另一个生成器从第二域获取图像作为输入并生成第一个域中的图像。然后使用鉴别器模型判断如何确定所生成图像的可信度,并更新相应生成器模型。
循环一致性是这样的概念,即第一生成器输出的图像可以作为第二生成器的输入,并且第二生成器的输出应该与原始图像匹配。反之亦然。
CycleGAN 鼓励通过增加一个额外的损耗来衡量第二生成器的生成输出与原始图像之间的差异,以及相反的值,来鼓励循环一致性。这种损失被用作生成器模型的正则项,指导新域中的图像生成过程朝着图像翻译的方向发展。 本文总结了计算机视觉中一些常用的损失函数,希望对你有所帮助。当然,最新提出来的一些损失函数并没有包含在内,后文将作进一步扩展。⟳参考资料⟲
[1]PyTorch 实现: https://github.com/sowmyay/medium/blob/master/CV-LossFunctions.ipynb
[2]U-Net: https://arxiv.org/pdf/1505.04597.pdf
[3]感知损失函数: https://arxiv.org/pdf/1603.08155.pdf
[4]全变分损失: https://www.tensorflow.org/api_docs/python/tf/image/total_variation
[5]风格损失: https://zpascal.net/cvpr2016/Gatys_Image_Style_Transfer_CVPR_2016_paper.pdf
[6]拓扑感知: https://arxiv.org/pdf/1712.02190.pdf
[7]FaceNet: https://arxiv.org/pdf/1503.03832.pdf
[8]生成对抗网络: https://arxiv.org/abs/1406.2661
[9]最小二乘 GAN 损失: https://arxiv.org/pdf/1611.04076.pdf
[10]Wasserstein 损失: https://arxiv.org/pdf/1701.07875.pdf
[11]Earth-Mover: https://en.wikipedia.org/wiki/Earth_mover%27s_distance
[12]循环一致损失: https://arxiv.org/pdf/1703.10593.pdf
[13]英文链接: https://medium.com/ml-cheat-sheet/winning-at-loss-functions-2-important-loss-functions-in-computer-vision-b2b9d293e15a















 2198
2198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









