





当下绝对是移动平台最火热的阶段,各色各样的游戏纷纷占领移动平台,包括NS也算一个移动平台,曾经的移动平台主力军Unity引擎,在现在UE4越来越火热的时候,Unity明显感觉到了UE4的压力,尤其是EPIC这一年来对移动平台的各种疯狂技术秀,这篇文章分享一些在开发中的小小经验。
在移动平台我们知道近些年出现了新的API,一个是vulkan,一个是metal,使用全新的API可以更高效的发挥硬件的性能,当描绘一个画面,CPU会向GPU发送许多的数据指令去描绘当前形形色色的几何体,着色。每发送一次绘制称为一次DC(DrawCall),当不合理的使用许多资源会造成DC的急剧增加,带来的结果就是CPU不堪负担,因为CPU每次开拓一个新的DC都需要经过很多准备工作,检查渲染对象,提交渲染数据等等,此时GPU基本上处于闲置状态,这就好比2个人一个人累死了一个人还在泡温泉。那么新的API可以更有效率的,或者说能够承受更多的DC,但是这里所说的承受更多的DC并不是说他能承载很多DC就各种不合理的使用,这里只是举个例子,说明新的图形API可以承担更大量的数据吞吐。
那么如何降低DC的绘制,以减轻整个CPU的过渡开销,就需要对资源进行合理利用,现在的移动设备,像高通820,835,或者现在的845,都可以承受较高的DC,但是尽量保持在100-150以下,像一些比较中低端的性能不是特别强劲的,例如麒麟960、高通660这些,尽量控制在更低的DC数量,不过这个同时还要看游戏的类型,比如2D游戏可能本身就很低,你再往更低的优化可能会损失很多细节。在PC平台上尽量控制在1000-1500或者更低。在UE4中可以使用命令 stat scenerendering来查看drawcalls的数量,观察Max的值。
这里再插入一点,实际需求根据实际情况来测试,博主的820CPU再跑场景时,如果保证60fps,必然要降低到100DC左右,实际情况下300多DC跑30FPS,在往上就开始卡了,更高的CPU可能会有更强大的性能,不过这只做一个参考,因为我只有场景和2个UI,没有游戏逻辑,加上其他的妥妥的肯定会降低很多。

nvidia之前发表在GDC的PPT上,有一个计算移动设备上可承受的DC值,大概是25K batch/s * CPU频率 * percentage(屏幕百分比)/理想帧率,这样得到的最终数值就是可承载的DC值,可以查看nvidia的PDF:
下载PDF
那么DC优化的方向,虽然说做不到100%完美,但是尽可能的找到通用的解决方案,然后或根据自己的实际需求专门的进行逐一优化。
我们都知道DC属于CPU要做的内容,同时属于CPU处理的还有游戏逻辑,物理对象,下面就先从DC说起。
进行DC优化之前,先要搞清楚啥东西会消耗DC,简单地说,我们每次渲染一个图形,哪怕是一个CUBE,都会执行一次或者多次的DC,假设,一个CUBE的材质占用一个DC(这里的材质按照只有一个贴图计算),场景里如果有10个CUBE分别给他一个材质,就会占用10个DC,如果这10个CUBE都是用一个材质球,那么这10个CUBE只会占用一个DC,因为他们都基于同一个材质球渲染,而不是每个单独的材质球所以需要每一个都走一次DC,这针对场景模型,UI也是一样,10个图标,就会占用10次DC,如果10个图标在一个图上,只会占用一个DC,这种方法叫做纹理集(texture atlas),获取纹理的pisition来选取不同元素。
除此之外,我们在更多的处理上,还要尽可能的减少同屏幕的渲染数量,例如使用遮挡剔除,PrecomputedVisibility,流关卡,各种实例化的组件,减少同屏幕的渲染数量也会减轻GPU的负担,遮挡剔除有一个问题要了解,他的剔除方式,是对相机视野(视锥体遮挡)以外的东西进行剔除,如果在相机体以内的物体,但是这个物体前面被一个遮挡了,那么被挡着的物体照样会被渲染出去,这种虽然看不见,但是也会占至少一个DC。
PrecomputedVisibility是一种除剔除遮挡外的另一个遮挡方法,下面一个文章非常详细的描述了预计算可见性的介绍,参数设置以及有限制的地方:
http://timhobsonue4.snappages.com/culling-precomputed-visibility-volumes
合并MESH作为一个处理,也会减少一次或者多次的DC,那么刚才说到CUBE的时候,一个材质球可能不止一次DC,但是明明只有一个CUBE和一个材质球啊,为什么还有可能会占用更多的DC,其实这个和贴图包括材质球的复杂程度有关,每一个材质,会占用一次DC,也就是说一般会存在一个MESH有许多个材质球的情况,这种情况下,可以尽量在一个材质中处理多个纹理,做成通用的材质球,也是一种降低DC的方法,另外有一点就是注意贴图的使用数量,虽然说更高特性的API,比如ES_3.1或者vulkan支持16个纹理贴图的材质,但是很少这么做的。
另一方面就是对材质的实例使用,举个例子,我们有A和B两个模型,他们两个分别基于一个母材质而做了2个不同的实例材质,这样也会执行2次DC,如果是对参数的修改调用不同在母材质中的数值切换纹理或者参数,那么只会有一次DC,除此之外还可以使用材质参数集,这样可以更高效率的使CPU进行计算,因为A和B两个物体的不同材质实例需要每一个都算一次计算,如果使用材质参数集同时驱动,那么只会执行一次。
Unity里有批量处理DC的功能,UE4暂时没有批量将对象作为一次DC的功能。
最后就是对代码的优化,游戏的逻辑,是靠CPU去计算,这里就不说了,尽量优化代码结构,和比如说某些获取参数的方法会花费很多查找时间,那么就会有一个更快速的查找方法来获取对象或者参数,同时引擎在不断的更新中也会废除老旧的方法。
说了一些CPU的东西,紧接着就来说说GPU方面的东西,其实GPU方面也无非就是那么多内容,什么删减面啊,和减少DC一样的剔除方法同样会降低GPU的运算啊,增加LOD啊,还有贴图的精度啊,材质球的复杂程度啊,光照啊等等,无一不再强调的就是减少面数,降低贴图分辨率等等。
减少面数这个就是常识了,什么合并MESH删除不渲染面什么的,在移动端通常情况下的三角面也就是50-60万的样子,不过也见过有些是在更高,PC上则大概就是在100万左右的样子,也有更高。
除了面数,就是贴图的复杂程度了,这里就提到了刚才说过的纹理数量,虽然高级的图形API支持16张纹理,但是移动平台上不会用到这么多,你要说PC还有可能,比如做影视的,所以尽量优化材质球的复杂程度,会降低GPU的计算,也包括纹理的分辨率,一般2K就已经很大了,移动设备基本上除非特别醒目的会使用1024,大部分还是像128、256为主,一些不起眼的小东西其实16或者32就已经足够了,还有就是像法线贴图,博主在之前测试一个小萝莉,在高通625上,不加法线可以跑在40fps,加了法线只能跑20fps,当然这也存在一定可以优化的地方,只是说不同的纹理所带来的开销也会根据不同的类型增加。如果既要使用高一点的纹理还想要优化性能,贴图存在mipmap的设置,mipmap就是根据最原始的贴图进行等比例的特定缩小备份图,在例如对需要精细显示的使用最高质量的mipmap等级,如果退回到十万八千里,他就会用最小的mipmap等级代替,不同等级的mipmap备份图,产生的大小也不一样,还有就是CPU优化时说过的纹理集-texture atlas。
哦了,还有最重要的光照,光照往往也是一个性能开销的罪魁祸首,移动端跑动态光照,不是不可以,也行,移动端适合选择前向渲染,在UE4的项目设置,rendering中,可以启用forward shading,前向渲染中,我们可以使用MSAA抗锯齿,但是使用抗锯齿必然也会造成一定的性能开销。好像跑题了,回到光照上,在移动端,尽量使用lightmass。
光照分一段落写,UE4给我们提供了3个光照模式,全静态(static),固定的,但是我更喜欢叫它混合光照(stationary),还有一个全实时(movable),为什么使用全静态,因为全静态不会独立产生阴影贴图,要知道在移动端,PBR材质的开销都很小相反阴影贴图会造成巨大的性能开销,所以这里使用全静态构建,阴影直接烘焙在lightmass贴图上。这个坏处就是说,你人的影子进入一个背光的墙背后,你不会被影子影响,这里可以参考写的unity光照系统剖析文章中的第四点,有描述:
https://ericsong.org/2018/05/2717.html
但是好处就是说,太能节省性能了,那么stationary光照,他会对静态物体做烘焙,对动态物体进行光影影响,也就是说静态物体构建了后,角色移动到比如还是背光墙背后,此时角色也会阴影影响变黑,但是这种方法就产生了阴影贴图,刚才说过移动端阴影贴图的性能开销是比较大的。最后一个movable光照就不说了,实时的光影,手游里如果做逼真的手电筒或者什么特殊需求的可能需要。反正在光照方面,能作假的就尽量作假好了,如果真的不在乎硬件性能的话,比如做极致视效或者过个多少年以后手机性能厉害的一批了,那什么体积光体积雾动态GI如果都能在移动平台上用那就随便用。移动平台下的动态阴影,如果想要的话,可以尝试使用modulated shadow,这个坏处就是2个影子不会融合。
在移动端平台上,UE4可以打包的贴图压缩里,可以使用ASTC或者PVRTC2,可以在提供更高的纹理质量。
这里插播一个关于压缩贴图的知识,通用的格式是ETC,但是ETC有着一些缺陷,比如它不支持alpha通道,ETC2支持RGBA,ASTC是ARM提出的高质量纹理压缩格式,PVRTC本身是支持PowerGPU设备。
GPU的优化离不开模型,材质贴图,光照方面的东西,总之一句话就是能想到的都用上。
这里还想说一点,因为GPU和CPU都会用到的,就是骨架物体的处理,一个骨架物体的骨骼,普通情况下引擎都会有限制,通常情况下也就是30-60个骨骼,根据游戏项目角色不同使用,移动平台也就是再25-30或者更低,因为骨架的蒙皮和结算都离不开GPU和CPU的处理,以前是CPU蒙皮,现在可以使用GPU计算,同时引擎有着同一个顶点权重不超过4根骨头控制的限制。
大概把一些主要的讲了一下,本文内容随着更深入的开发获得的经验持续更新中,另外说一点,上文开头写了个尽量使用实例化各种组件,这里指的是类似像static mesh component instance,基于一个staticmesh去创建更多的实例对象。
写在最后,其实UE4还提供了非常多的性能监测工具,例如输入stat startfile和stat endtfile,会录制一个游戏的分析文件,该现成可以使用session frontend工具打开查看UE4里所有的分析,AI、音频、模型、UI、Canvas、地形、动画、材质等等UE4里所有可分析对象的统计数据,可以更快的排查一个时间段的瓶颈。
还有GPU分析的工具,UE4提供了一个叫ProfileGPU的工具,可以监测当前在场景中每帧的绘制过程中什么东西花费了多少毫秒,就可以基于这一块进行专项的优化。
还有一些命令,stat unit啊,stat engine中看三角面数量啊,更多命令可以在UE4面板上,Help-Console Variables中查看。
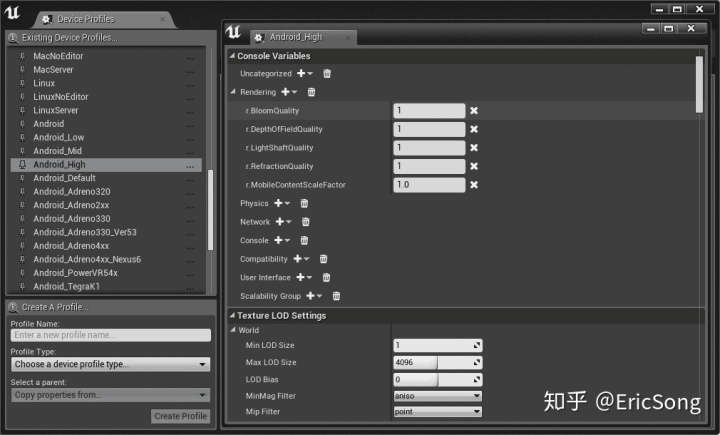
另外UE4对设备的平台,有用一个可控的参数面板,也在Window-Development Tools中,有个叫Device Profiles,如下图所示,它可以对当前平台添加一些预先配置好的设置,非常的方便:















 1108
1108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









