






1. GAN Compression: Efficient Architectures for Interactive Conditional GANs
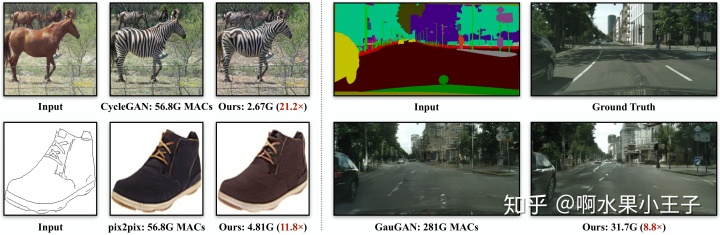
韩松组与朱俊彦合作的GAN压缩的文章。GAN自2014年发明以来,在图像领域产生了深刻的影响,但是GAN模型的好坏越来越依赖大的模型大的计算量,这使得将神奇的GAN模型部署到手机上成为困难。
本文提出了一种通用的条件生成GAN模型的压缩算法,在pix2pix,cylegan或者GauGAN上可以达到9-21倍的压缩性能而几乎不损失效果。
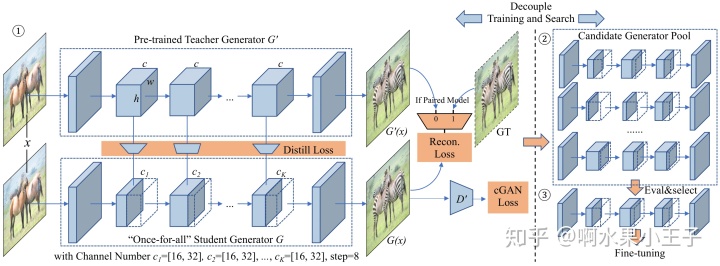
算法主要过程:
- 给定一个预训练的teacher
,首先从 teacher
中蒸馏一个“once-for-all”的student
,通过权重共享的策略这个
包含了所有可能的通道组合方式。在训练的每一步中选择不同的通道数构成
。
- 从once-for-all
中sample一些sub generators,然后评估每个generator的性能。
- 从2.中选择满足压缩比与效果条件的模型作为候选模型,fine-tune候选模型,将其作为最终的压缩模型。
这篇文章提供了一个很好的GAN压缩思路,实际生产过程中值得一试。而且已经开源:
https://github.com/mit-han-lab/gan-compression
2. Momentum Contrast for Unsupervised Visual Representation Learning
作者提出了基于momentum constrast的一种无监督表达学习方法。将对比学习看作查字典的过程,我们可以通过一个queue与moving average encoder来构建一个动态的字典。这样就可以构建一个足够大的字典满足对比学习。MoCo提供强大表达能力,除了在ImageNet分类任务上取得显著的效果,在其他下游的视觉任务上可以超越许多监督预训练的模型。
从这篇文章的效果看,在视觉任务上将有监督的表达学习与无监督的表达学习的gap又拉近了很多。整体思路其实还是比较简单,这里附一下论文里的pytorch 风格伪代码:

期待在工业界中的表现。
3. MSG-GAN: Multi-Scale Gradient GAN for Stable Image Synthesis
高质量图像生成一直是GAN领域的应用热点,随着ProGAN,BigGAN,StyleGAN,StyleGAN2等的提出图像生成的质量也越来越高。但是这些模型在应用到不同的数据集的时候需要精细的调整超参数,即便如此在使用渐进训练(StyleGAN2, BigGAN除外)的框架的时候也容易出现训练不稳定问题导致的奔溃。为了人人都能够更加愉快的训练GAN,本文提出了一种Multi-Scale Gradient训练的框架,当然这篇文章非常实验性,没有深刻的理论解释,现在这个年代在这个领域靠设计简单的结构做实验的文章能中CVPR也挺难的,这篇就当一些trick来看,文章的主要精华就在网络结构这里了:
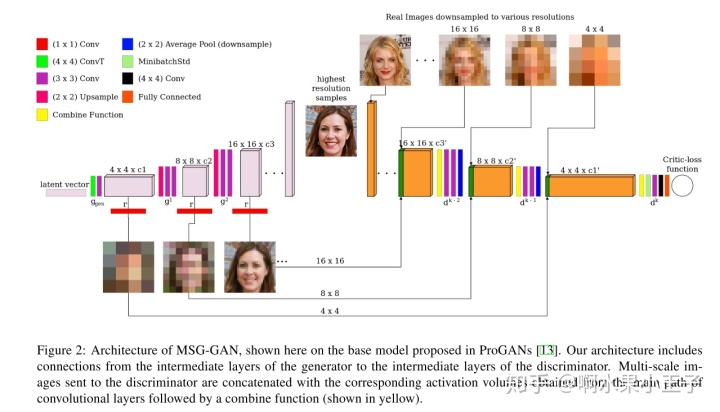
生成器包含两种一种基于ProGAN,一种基于StyleGAN。判别器使用一个multiscale-in-one的模型,如果把判别器跟生成器接起来非常像一个类Unet结构,这样这些多尺度的gradient就可以直接通过internal的层稳定传播。
文章的结论是通过这种multiscale的设计,可以用一组超参数在各种不同的数据集上得到稳定的训练结果。
4. GhostNet: More Features from Cheap Operations
CNN网络中存在很多冗余的feature,但是这些feature对于CNN的效果表现很重要(个人觉得冗余是在同一个level上看的,如果在不同的尺度上看,有些并不一定冗余)。本文作者发现,没有人从这个角度直接出发去解决网络性能优化的问题,作者认为这些冗余的featrure map可以通过简单的线性操作得到,从而提升性能,所以本文的motivation从下面这张示意图中就可以看出。
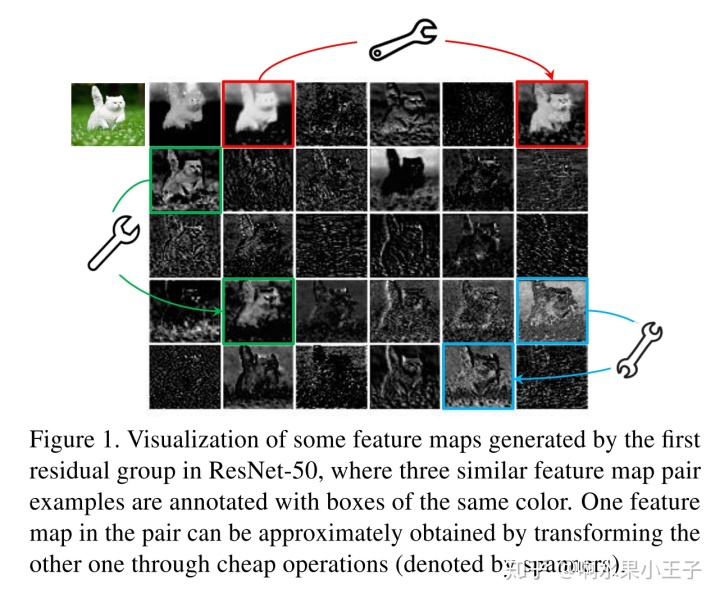
根据这个直观的发现,可以通过设计一些简单线性变换就可以得到对应的ghost feature,将这些ghost feature与原本的feature组合就可以在更低计算量的情况下得到类似的表达能力,本文提出的ghost module可以做到即插即用,可以非常方便的替换普通的conv layer。代码已经开源:
huawei-noah/ghostnetgithub.com













 1723
1723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









