






1,概述
在NLP中孪生网络基本是用来计算句子间的语义相似度的。其结构如下
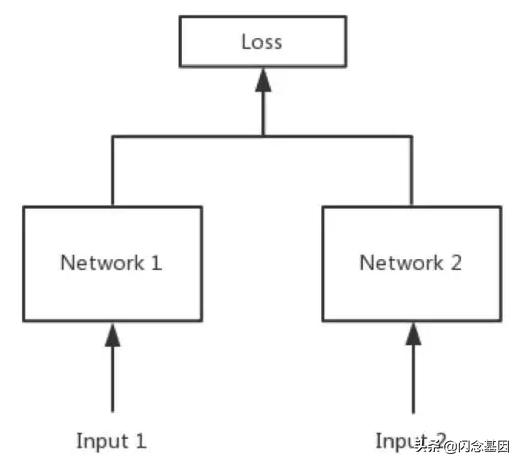
在计算句子语义相似度的时候,都是以句子对的形式输入到网络中,孪生网络就是定义两个网络结构分别来表征句子对中的句子,然后通过曼哈顿距离,欧式距离,余弦相似度等来度量两个句子之间的空间相似度。
孪生网络又可以分为孪生网络和伪孪生网络,这两者的定义:
孪生网络:两个网络结构相同且共享参数,当两个句子来自统一领域且在结构上有很大的相似度时选择该模型;
伪孪生网络:两个网络结构相同但不共享参数,或者两个网络结构不同,当两个句子结构上不同,或者来自不同的领域,或者时句子和图片之间的相似度计算时选择该模型;
另外孪生网络的损失函数一般选择Contrastive loss Function(对比损失函数)。接下来具体看看孪生网络在句子语义相似度计算中的几篇论文:
2,论文模型介绍
1)Siamese CBOW: Optimizing Word Embeddings for Sentence Representations
该论文提出了一种基于孪生网络+CBOW的方式来无监督式的训练句子的向量表示。网络的结构图如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1853
1853











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









