







Simese network
简单来说,孪生神经网络(Siamese network)就是“连体的神经网络”,神经网络的“连体”是通过共享权值来实现的
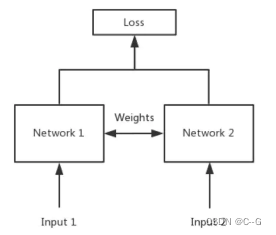
所谓权值共享就是当神经网络有两个输入的时候,这两个输入使用的神经网络的权值是共享的(可以理解为使用了同一个神经网络)。
很多时候,我们需要去评判两张图片的相似性,比如比较两张人脸的相似性,我们可以很自然的想到去提取这个图片的特征再进行比较,自然而然的,我们又可以想到利用神经网络进行特征提取。
如果使用两个神经网络分别对图片进行特征提取,提取到的特征很有可能不在一个域中,此时我们可以考虑使用一个神经网络进行特征提取再进行比较。这个时候我们就可以理解孪生神经网络为什么要进行权值共享了。
孪生神经网络有两个输入(Input1 and Input2),利用神经网络将输入映射到新的空间,形成输入在新的空间中的表示。通过Loss的计算,评价两个输入的相似度。
网络结构

上面图例使用VGG16实现图像特征提取(本博客使用VGG19,换VGG16也行),然后将两个图像的特征摊平后进行求L1距离,然后将结果放入全连接层
简单代码实现
VGG19
class VGG19(nn.Module):
def __init__(self, num_classes=1000):
super(VGG19, self).__init__()
##加载基于VGG19的模型
vgg_based = torchvision.models.vgg19(pretrained=True)
for param in vgg_based.parameters():
param.requires_grad = False
# 修改最后一层
number_features = vgg_based.classifier[6].in_features
# 移除最后一层
features = list(vgg_based.classifier.children())[:-1]
# 添加自己的最后一层
features.extend([torch.nn.Linear(number_features, num_classes)])
vgg_based.classifier = torch.nn.Sequential(*features)
self.features = vgg_based
def forward(self, x):
# 我们使用VGG19的features层
with torch.no_grad:
x = self.features(x)
# 摊平
x = torch.flatten(x, 1)
return x
Siamese
class Siamese(nn.Module):
def __init__(self, input_shape, num_classes=1000):
super(Siamese, self).__init__()
self.vgg = VGG19(num_classes)
self.fully_connect1 = torch.nn.Linear(num_classes, 512)
self.fully_connect2 = torch.nn.Linear(512, 1)
def forward(self, x):
x1, x2 = x
x1 = self.vgg.features(x1)
x2 = self.vgg.features(x2)
x = torch.abs(x1 - x2)
x = self.fully_connect1(x)
x = self.fully_connect2(x)
return x
训练
vgg19 = VGG19(num_classes=2)
for i in range(10):
image = torch.randn(1, 3, 224, 224)
siamese = Siamese(image.shape, 2)
# 这里随机拿两个张量用于测试
out = siamese((image, image))
print(out)
out = out.squeeze(dim=-1)
mse_loss = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(siamese.parameters(), lr=0.001)
print(out)
# 实际要根据两张图片是否为同一个体输入labels
loss = mse_loss(out, torch.tensor([1], dtype=torch.float))
print("loss", loss)
optimizer.zero_grad()
loss.backward()
optimizer.step()
损失函数优化
对比度损失(Contrastive loss)
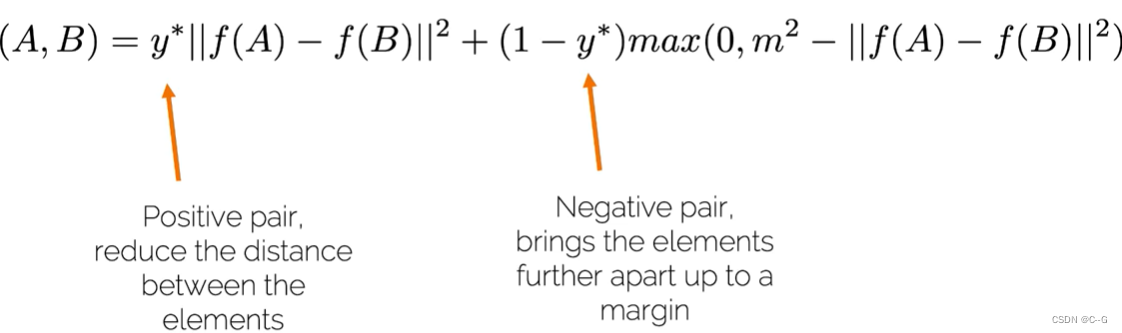
Triplet Loss
训练集中随机选取一个样本:Anchor(a)
再随机选取一个和Anchor属于同一类的样本:Positive(p)
再随机选取一个和Anchor属于不同类的样本:Negative(n)
这样<a, p, n>就构成了一个三元组
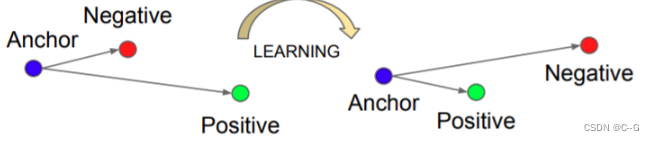
我们想要的是P靠近A,N远离A,用数学表达如下图
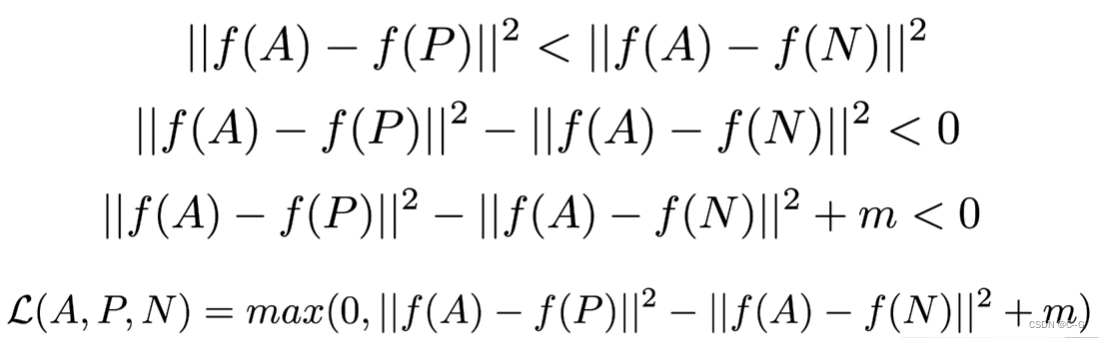
pytorch 代码实现
CLASS torch.nn.TripletMarginLoss(margin=1.0, p=2.0, eps=1e-06, swap=False, size_average=None,
reduce=None, reduction='mean')

官方例子
triplet_loss = torch.nn.TripletMarginLoss(margin=1.0, p=2)
anchor = torch.randn(20, 20, requires_grad=True)
positive = torch.randn(20, 20, requires_grad=True)
negative = torch.randn(20, 20, requires_grad=True)
output = triplet_loss(anchor, positive, negative)
output.backward()
- triplet hard loss
三元损失约束条件需要在所有的三元组上面都成立,但是如果严格按照这个约束,那么三元组集合可能会相当大,需要穷举所有的三元组,显然不太现实,所以常用的办法就是选取部分进行训练,也就是选取困难样本对(hard triplets)进行训练
那么hard triplets怎么选


Hierarchical Triplet loss
通过建立层次树表示,递归合并叶子结点,直到到达根节点

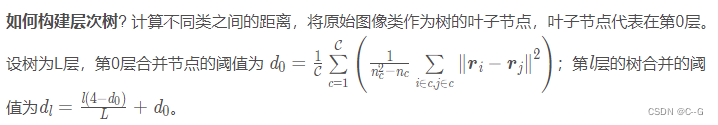
首先要建立类间距离公式,如果两个类之间距离近则合并到下一层
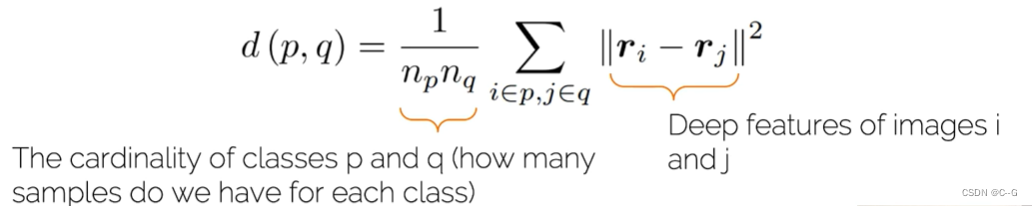


如何选取Anchor?在层次树的第0层选取l ′ l^{\prime}l
′
个节点,对每个节点分别选取(m-1)个在第0层最近的类,在每个类随机选取t个图片。因此,mini-batch的数量为n =l ′mt。
Hierarchical triplet loss 的表达式为:


Ensembles
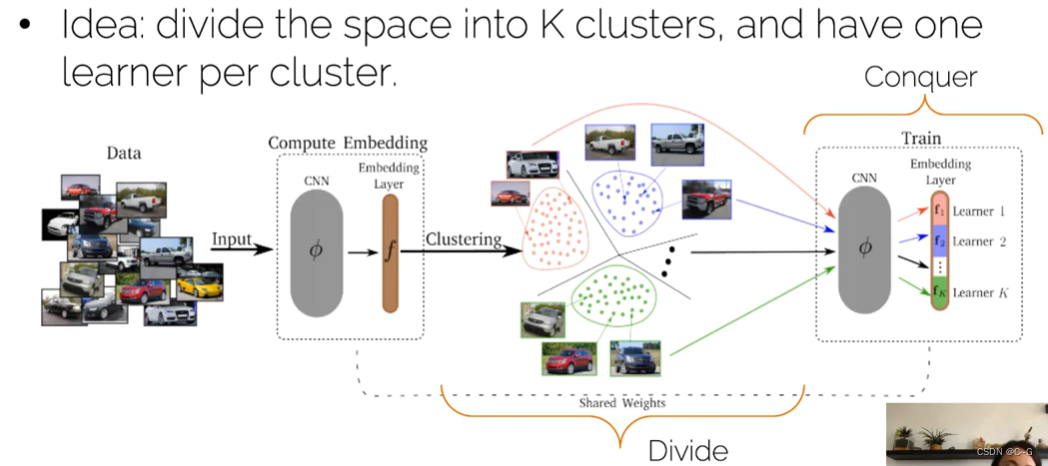

Applications in vision
- Siamese network on MNIST
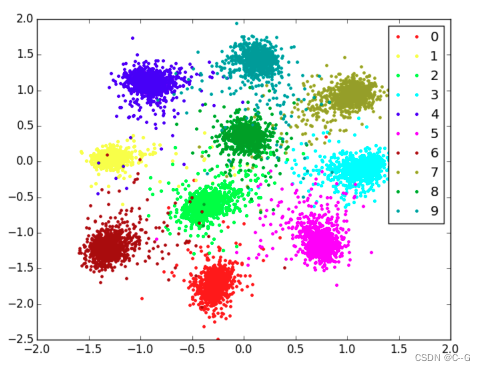
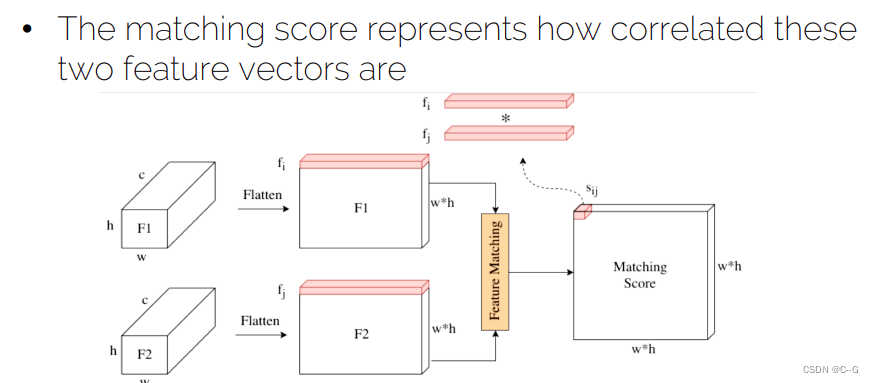
- Establishing image correspondences




- Establishing image correspondences
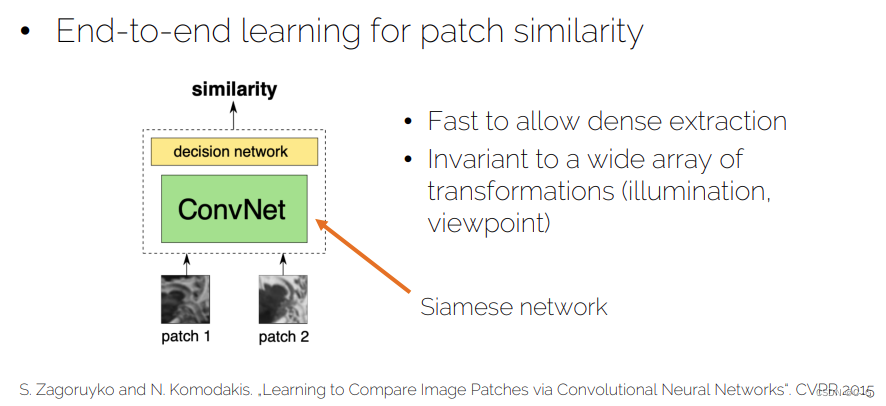

- Image retrieval
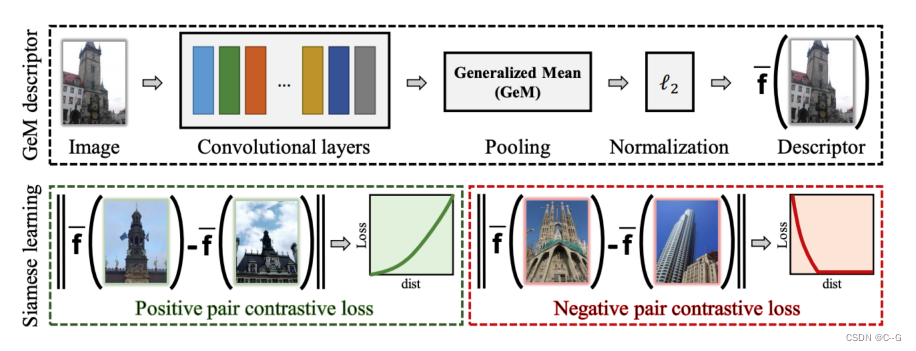
- 无监督学习
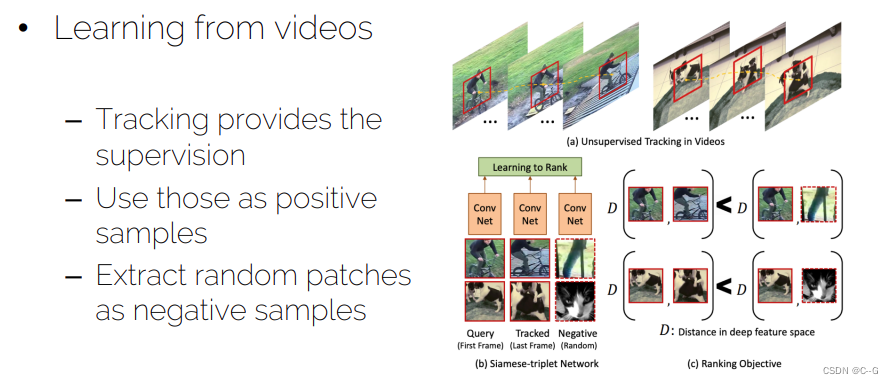
- Optical flow



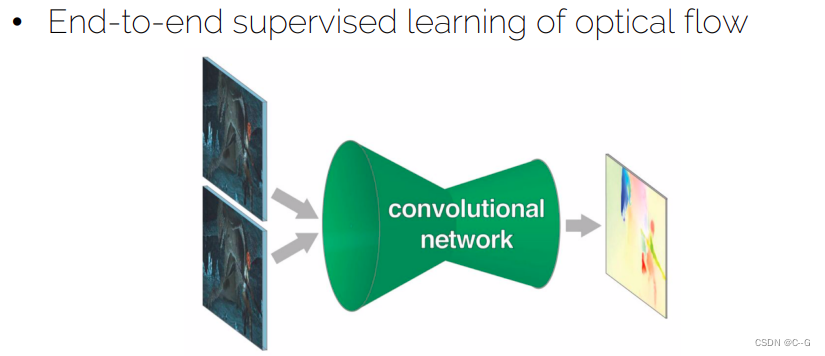
- Optical flow with CNNs

- FlowNet:architecture 1
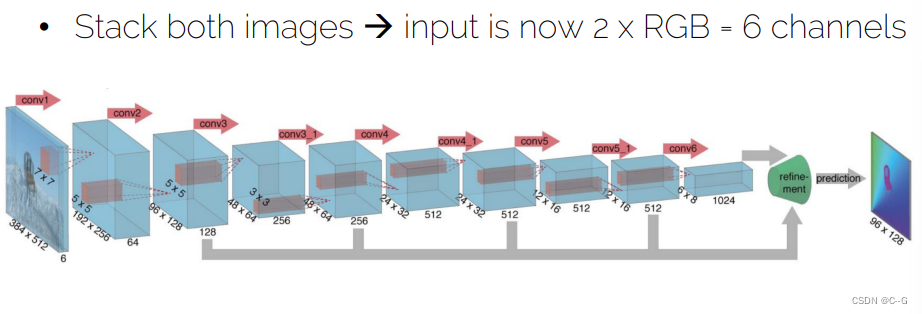
- FlowNet:architecture 2
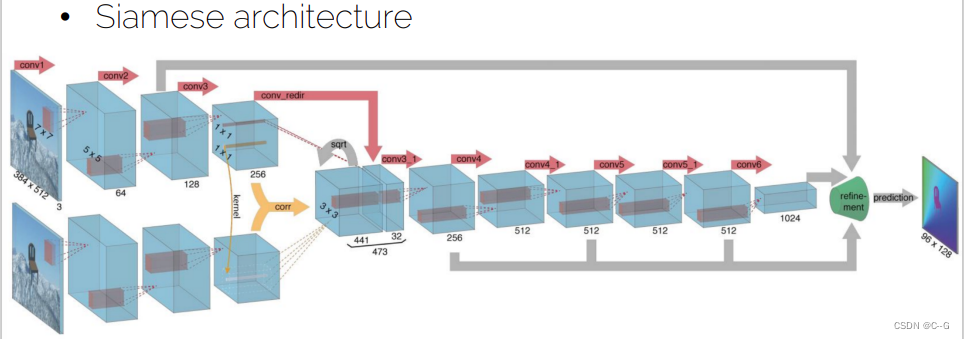
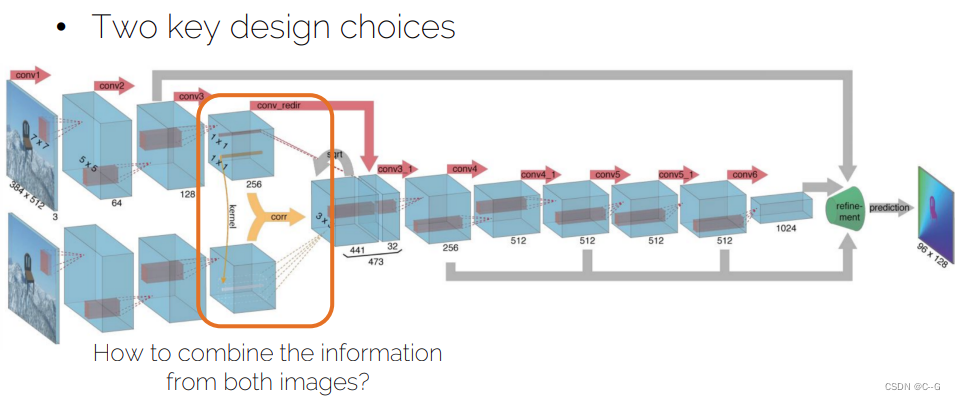
- Correlation layer
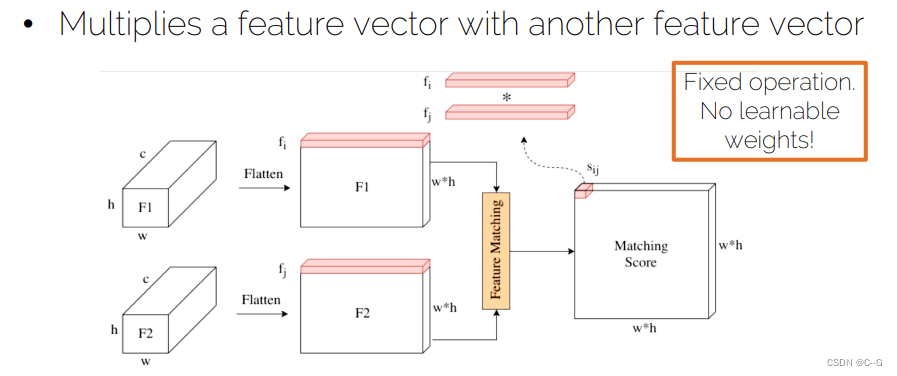



















 9020
9020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









