






对于xgboost的理解一直处在半知不解的情况,知道这个东西,大致知道这个原理;
但是让自己说一遍的它的原理的时候,发现根本说不出什么:它就是一个一棵树,用boost的方式串行,让模型上下相关联,关联的方式是用残差。
那具体是怎么构建这棵树的呢?怎么通过残差进行上下关联?怎么计算目标函数的?
带着这个问题查了资料,看到了一篇真的通俗易懂的文章,而且很深入。
王改改:【通俗易懂】XGBoost从入门到实战,非常详细zhuanlan.zhihu.com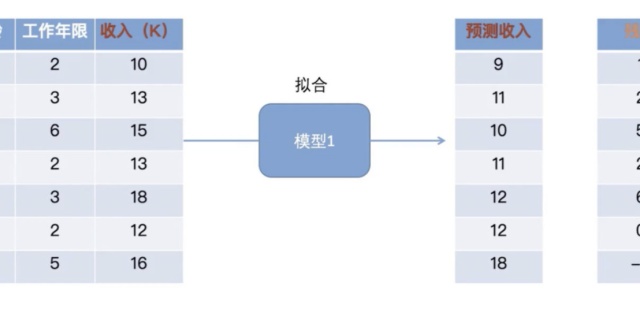
通过自己的理解,再咀嚼后,记录此笔记。
一、进入模型前的简单案例
在上一篇文章中的案例,通俗的讲解了思路:
训练出第一个模型,计算其预测结果及残差;
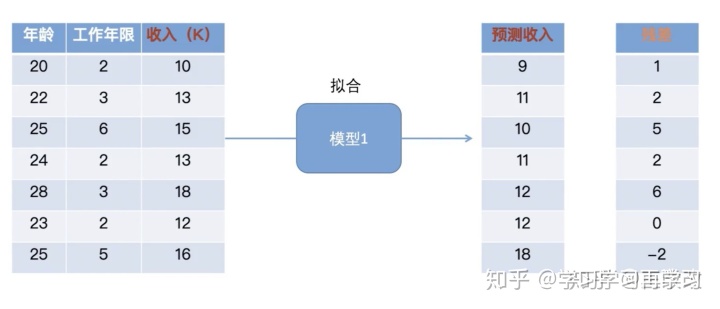
然后再以当前模型的残差,作为下一个模型的实际输出,将其与下一个模型的预测结果作对比,得出这个模型的残差;
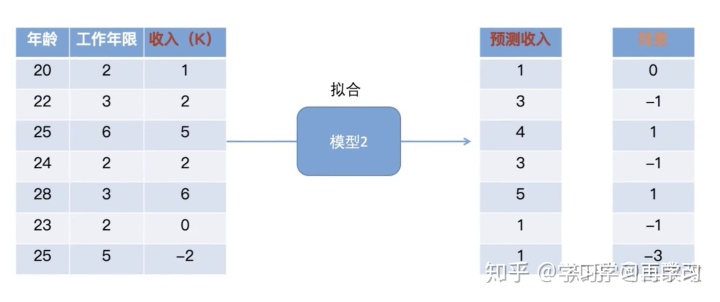
再迭代到下一个......(看案例中的图更容易理解)
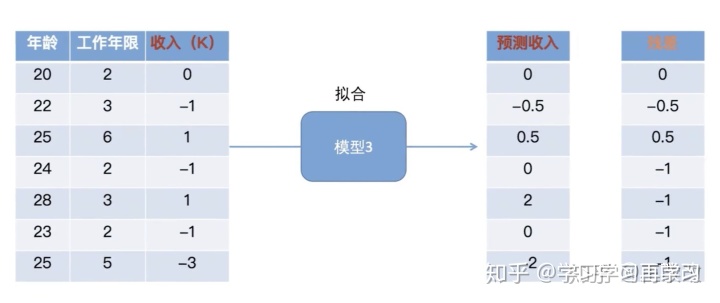
最终的输出结果是所有模型的预测结果之和

这个案例解决了我在看其他人写xgboost案例时看不懂的地方,其他地方写的都是以家庭中每个人的那个作为案例。我看的时候完全不知道它到底想干嘛,最后为什么又是把所有结果加起来,直到我看到了这位作者后才真正直到原理。
二、构建损失函数
个人在学习机器学习和深度学习的时候,除了要了解原理,另外最重要的就是要重点知道该算法的损失函数是怎么计算的!这是每个算法的核心。
假设我们已经训练了
其中
再结合真实的结果label是
其中
后一项是用来控制复杂度的,类似于l1,l2正则,可以防止过拟合。
对于目标函数我们可以再拆开,类似于动态规划的思想,将
这其中就是将
通过泰勒展开近似损失函数
泰勒展开式为:
将损失函数套用上泰勒展开,
即可得
代入损失函数即可得:
再重复一遍,当前目标函数是训练第
如上所说,
定义树的复杂度
一颗树的复杂度可以用叶节点个数和节点值计算得:
给两个都乘上一个超参数,用来控制他们,
最终可以再优化得到:
最后得:
我们知道
所以,所以当树的结构固定,也就是说
其中
三、构建树的形状
在得到了损失函数,就可以开始构建树了,那怎么构建树呢?贪心算法!
没错,先计算当前树的损失函数,再穷举出所有可能性,然后计算所有穷举后的损失函数,然后取损失函数降的最多的那棵树最为当前树的形状,然后再重复......直到损失函数减少的不够多的时候,我们可以设个阈值,就可以停下来!
「卓拾书非卓师叔」
作者:卓师叔,爱书爱金融的NLPer
了解更多和AI、金融相关的知识,请关注公众号:卓拾书非卓师叔















 899
899











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









