






 本文介绍了Stata中进行全局主成分分析的命令与步骤,包括PCA命令、Estat工具、预测、碎石图等,并讨论了面板数据实证分析中的聚类问题、工具变量回归和PSM-DID方法的应用。此外,还涉及了ttest和ranksum检验的差异以及模型假设验证的注意事项。
本文介绍了Stata中进行全局主成分分析的命令与步骤,包括PCA命令、Estat工具、预测、碎石图等,并讨论了面板数据实证分析中的聚类问题、工具变量回归和PSM-DID方法的应用。此外,还涉及了ttest和ranksum检验的差异以及模型假设验证的注意事项。
热烈欢迎张晓峒老师成为免费问答平台的学术委员会主席!
问题1: 关于GPCA(全局主成分分析模型)的相关Stata 命令
老师能否给一个使用全局主成分分析法,包括Stata命令的参考案例?
回答1
1.Stata可以通过变量进行主成分分析,也可以直接通过相关系数矩阵或协方差矩阵进行。
(1)sysuse auto,clear
pca trunk weight length headroom
pca trunk weight length headroom, comp(2) covariance
(2)webuse bg2,clear
pca bg2cost*, vce(normal)
2.Estat
estat给出了几个非常有用的工具,包括KMO、SMC等指标。
webuse bg2,clear
pca bg2cost*, vce(normal)
estat anti
estat kmo
estat loadings
estat residuals
estat smc
estat summarize
3.预测
Stata可以通过predict预测变量得分、拟合值和残差等。
webuse bg2,clear
pca bg2cost*, vce(normal)
predict score fit residual q (备注:q代表残差的平方和)
4.碎石图
碎石图是判断保留多少个主成分的重要方法。命令为screeplot。
webuse bg2,clear
pca bg2cost*, vce(normal)
screeplot
5.得分图、载荷图
得分图即不同主成分得分的散点图。命令为scoreplot。
webuse bg2,clear
pca bg2cost*, vce(normal)
scoreplot
6.旋转
对载荷进行旋转的命令格式为rotate。
webuse bg2,clear
pca bg2cost*, vce(normal)
rotate
问题2: 有关数据分析的几个问题
在用中国工业企业数据库的微观企业面板数据进行实证分析,被解释变量是y,核心解释变量是x和x^2,检验x对y的影响是否是U型,即一次项回归系数是负的,二次项回归系数是正的,还包括一些其它控制变量,回归方程是xtreg y x x^2, fe。我的问题包括:
第一,在做企业固定效应时,stata自动对100多万样本分了几十万聚类,是否还有必要在回归中加入聚类(cluster),如果要加入聚类的话,应该加入什么层面的聚类?比如省层面、地级市层面、县层面、行业层面、企业层面?有人提出cluster的数目不能太少,至少应该大于42,但是为什么国内《经济研究》等杂志使用了省份聚类?聚类数目只有30个。
第二,找到一个x的工具变量z,回归是xtreg y (x x^2=z z^2),fe,把内生变量和工具变量的平方项也放进括号里面,请问这种做法没问题吧?
第三,在用xtivreg2做工具变量回归时,尝试加入聚类(cluster)时,stata不允许,回归是xtreg y (x x^2=z z^2), fe vce(cluster provincecode)。provincecode是省份代码。请问如何在工具变量回归中加入聚类?
回答2
第一,企业面板数据分析中,如果控制了企业的固定效应,一般需要在企业层面聚类,xtreg这个命令默认聚类到fe对应的单位,在这里就是企业。例如:
xtset firmid time
xtreg y x, fe vce(cluster firmid)
此时,第二行命令等价于使用了robust选项【xtreg y x, fe vce(cluster firmid) 等价于 xtreg y x, fe vce(robust)】。理论上,你也可以在更高层级上聚类(比如行业或省份,前提是企业所属行业或省份不随时间变化),取决于你如何理解个体之间的横向关联。存在聚类时,估计量的渐进分布等性质在聚类数量足够大时才成立,多大算大没有定论——都是数值模拟的结果。30个聚类可以接受,但如果小于10个就会有问题,需要调整标准误。
第二,如果工具变量 z 不是0-1二元变量(此时z与z平方完全相同),一般来说就没问题。
第三,你没有提供Stata错误代码。如果你的fe依然是在企业层面,但程序不允许你估算省份层面聚类标准误,可能的原因是某个企业的地址随时间发生了变化——由一个省搬到了另一个省,所以无法聚类。正如我第一点说的,固定效应的层级不能超过聚类层级,需要嵌套在聚类层级里。
问题3: 关于PSM核匹配和DID的相关问题
我最近在研究PSM-DID这个具体做法,在学习过程中遇到以下问题,请教您一下。首先第一操作是进行PSM核匹配,这步我没有问题:

第二步,进行DID:

这一步是我学习《中国工业经济》上的文章《延付高管薪酬对银行风险承担的政策效应——基于银行盈余管理动机视角的PSM-DID分析》时看到的,我不明白为什么先要生成vnimw=vnim*weight,而不是直接用vnim进行回归呢?所有的匹配方法都需要在匹配完成后先生成一个带权重的被解释变量,然后再做DID吗?还是只有核匹配需要将原来的被解释变量乘以匹配的权重生成一个新的被解释变量然后再DID呢?
(向上滑动启阅)
回答3
做PSM-DID时,首先需通过PSM相关命令(比如psmatch2)生成一套匹配权重(比如psmatch2运行完毕之后默认生成的_weight),然后将这套权重应用在DID分析中。比如某个对象的权重是0,那么它在匹配阶段没有找到匹配对象,也就不会参与DID阶段的分析;如果某个对象的权重是2,那么它在匹配阶段与两个不同对象匹配成功,在DID分析中的重要性就是原来的两倍。该权重在DID阶段的用法是加权在回归式中(比如在回归命令中加入[aw=_weight]),问题中提到的把因变量与权重相乘再做回归似乎没什么道理。建议提问者联系作者进一步确认这么做的原因——从我个人角度来说,这么做是有问题的。
PS:再一次盛赞《中国工业经济》公开数据和代码的做法,使得每一个研究步骤都变得透明和可检验。
问题4: 关于收入均值处理的问题
怎么根据统计年鉴上提供的收入分组及落入分组的居民户数占比,计算出各个收入分组的均值呢?如何从表1的数据得到表2中每组的人均收入呢?
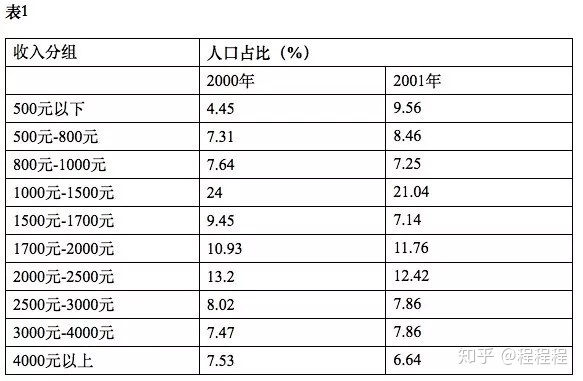
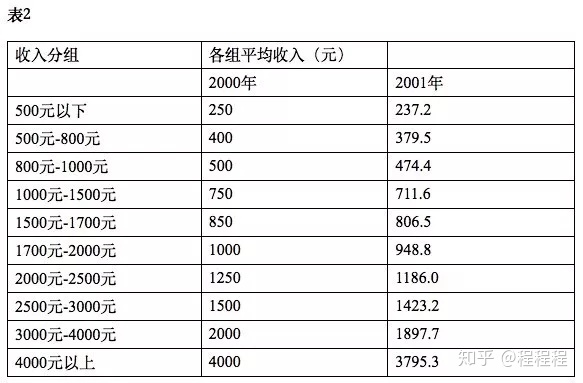
[1]胡兵,赖景生,胡宝娣.经济增长、收入分配与贫困缓解——基于中国农村贫困变动的实证分析[J].数量经济技术经济研究,2007(05):33-42.
[2]林伯强.中国的经济增长、贫困减少与政策选择[J].经济研究,2003(12):15-25+90.
上述两篇文章提到这个估计方法,由于Lorenz曲线方程的估计需一组Lorenz点,即人口和收入的累计比例的数值,但统计年鉴上的分组数据仅提供了收入分组及落入各分组的居民户数,无法直接计算收入的累计比例。林伯强(2003)利用1985年我国农村家庭调查数据拟合的结果表明,我国农村家庭收入的密度曲线是对数正态的。因此,可根据对数正态分布的性质,采用非线性回归拟合其参数,进而计算收入分组数据的各组均值,得到一组Lorenz点。
回答4
早期的统计年鉴里面没有提供分组的平均收入,需要知道收入的密度分布函数,根据密度分布函数计算均值,得出洛伦兹曲线。近些年的统计年鉴已经公布了各组的人口占比和平均收入数据,可以直接得出洛伦兹曲线。
问题5: ranksum和ttest的区别
《中国工业经济》2018年4月的文章《高管股权激励合约业绩目标的强制设计对公司管理绩效的影响》提供的代码中,在应用psmatch2函数进行配对之后,用了ttest和ranksum做检验,请问ttest和ranksum除了一个是t检验,一个是Z检验,分别适用于小样本和大样本之外,还有别的区别吗?
回答5
pstest, both做匹配后均衡性检验,理论上说此处只能对连续变量做均衡性检验,对分类变量的均衡性检验应该重新整理数据后运用χ2检验或者秩和检验。但此处对于分类变量也有一定的参考价值 。两者之间最主要的区别是ttest是参数检验,ranksum是非参数检验,非参数检验不需要满足参数检验所需的数量条件。在具体使用上,两组之间连续性变量的比较,如果为正态分布,可采用独立样本t检验,偏态分布可采用Wilcoxon秩和检验(即ranksum检验);两组之间分类变量之间的比较,可采用卡方检验,如果是等级变量,则采用秩和检验。
问题6: 不符合经典模型假设的情况
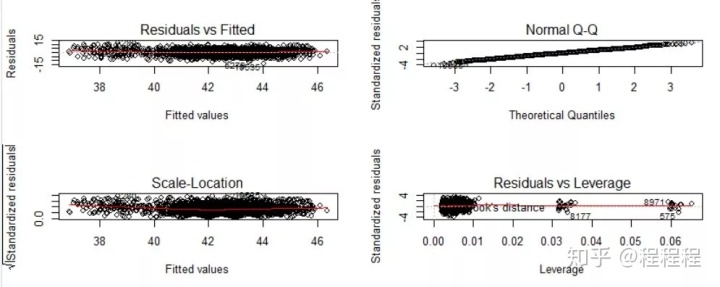
通过R语言的命令包(gvlma)进行综合验证的时候,“峰度”、“偏斜度”都没有通过。其他的R2,F值,T检验都是好的。但是,单独去检验没有通过的指标时,显示是好的。不明白为什么会这样?

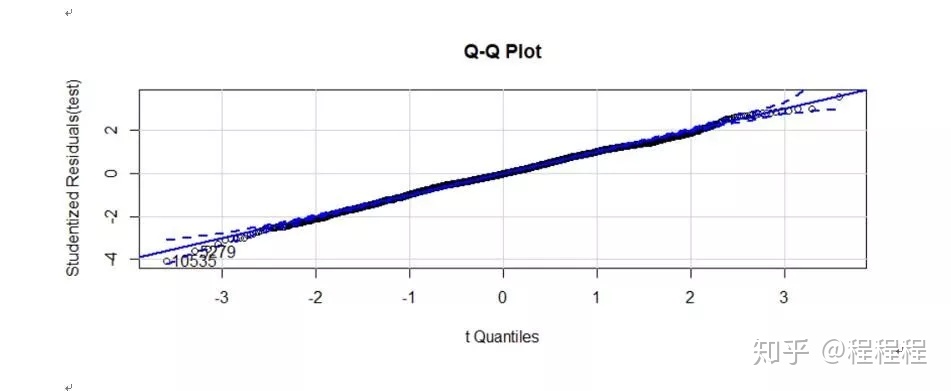
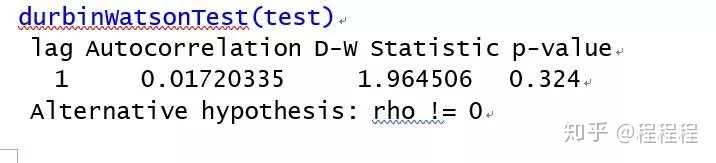
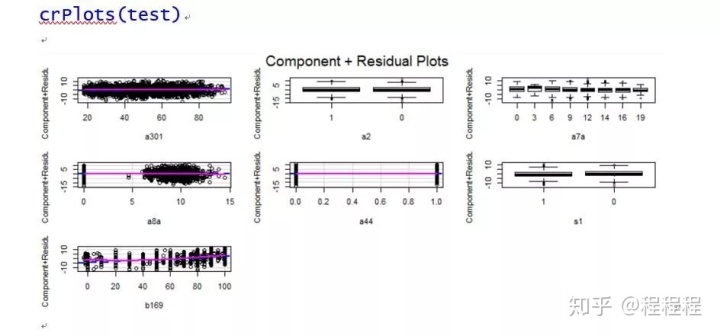
回归诊断图
回答6
gvlma包的gvlma()函数是对线性模型假设进行综合验证,单独验证是对模型中的单个变量进行验证,两者之间并没有必然的联系。建议参考伍德里奇《计量经济学导论》统计推断部分内容。
学术指导:张晓峒老师
本期解答人:杨芳博士 田人合博士 中关村大街
统筹:芋头
技术:知我者
往期回顾
互助问答第12期:截面数据的控制变量选取
互助问答第10-11期:观测数据频次、受限因变量模型等问题
互助问答第9期:工具变量、虚拟变量问题等
关于我们

如果您在计量学习和实证研究中遇到问题,请及时发到邮箱szlw58@126.com,专业委员会有20名编辑都会看,您的问题会得到及时关注!请您将问题描述清楚,任何有助于把问题描述清楚的细节都能使我们更方便地回答您的问题,提问细则参见:实证研究互助平台最新通知
如果您想成为问题解答者,在帮助他人过程中巩固自己的知识,请发邮件至szlw58@126.com(优先)或给本公众号留言或加微信793481976给群主留言,我们诚挚欢迎热心的学者和学生。具体招募信息请参见:实证研究互助平台志愿者团队招募公告
鲜活的事例更有助于提高您的研究水平,呆板的教科书让人生厌。如果您喜欢,请提出您的问题,也请转发推广!


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









