





“爱数据学习社”关注我们吧! -

文末领取【100份简历模板】
聚类分析的基本原理是,根据样本的属性,使用某种算法计算相似性或者差异性指标,以确定每个个案之间的亲疏关系,最终将所有个案分为多个相似组(即聚类),同一聚类的个案彼此相同,不同聚类中的个案彼此不同。常见的聚类方法有K均值聚类法、系统聚类法(也叫层次聚类法)等。
简而言之,聚类分析根据样本的多个属性,将相似的对象聚为一类,使同类之间尽量同质、不同类之间尽量异质。
特征:
聚类分析简单、直观
聚类分析主要应用于探索性的研究,其分析的结果可以提供多个可能的解,选择最终的解需要研究者的主观判断和后续的分析
不管实际数据中是否真正存在不同的类别,利用聚类分析都能得到分成若干类别的解
聚类分析的解完全依赖于研究者所选择的聚类变量,增加或删除一些变量对最终的解都可能产生实质性的影响
异常值和特殊的变量对聚类有较大影响,当分类变量的测量尺度不一致时,需要事先做标准化处理
K-means算法
K均值算法比较简单,在SPSS中也被成为快速聚类,K均值算法中的每个类都是使用对象的平均值来表示。
步骤:
将所有对象随机分配到k个非空的类中
计算每个类中所有对象的平均值,表示类的中心点
根据每个对象与各个类中心的距离,分配给最近的类
若满足【终止条件】,则结束聚类;否则,转到步骤2
终止条件可以是:
没有(或者小于某个数值的)对象被重新分配给不同的类
没有(或者小于某个数值的)类中心发生变化
误差平方和(SSE)达到局部最小
达到指定的迭代次数

K均值算法必须在平均值有意义的情况下才能使用,因此不适用于分类变量。需要给定聚类数目,并且对异常数据和数据噪声比较敏感。
系统聚类算法
系统聚类有两种类型:聚合的(自下而上的)或者分解的(自上而下的)。
聚合的系统聚类法将每个对象都看做独立的一类,每一次通过合并最相似的聚类来形成上一层次中的聚类,整个当全部数据点都合并到一个聚类的时候停止或者达到某个终止条件而结束——这是大部分系统聚类所采取的方式。
分解的系统聚类法首先将所有对象看成一类,然后把根节点分裂为一些子聚类,每个子聚类再递归地继续往下分裂,直到出现只包含一个数据点的单节点聚类出现,即每个聚类中仅包含一个数据点。
系统聚类算法的好处是分析者可以对比不同聚类数量的结果,从中选择更感兴趣(更有解释力)的结果,这种对比可以通过生成的聚类树进行。
实践篇—使用模拟数据进行K均值聚类
1.用R生成模拟数据
为什么不使用现成的数据,而要用R来生成数据呢?
主要是因为在自己生成的数据中,我们可以预先定义存在哪些类型的用户群、每个用户群的属性是怎样的。
通过这种方式我们得以知道“客观现实”是怎样的,后面用SPSS做聚类分析时,可以将分析得出的结果与我们预设的“现实”做对比,看一下效果如何——聚类分析得出的类对我们预设的类的还原度有多高。
假设我们要做的是一款企业管理软件A的用户画像,所得数据中一共有1200个有效样本,其中存在三类用户:
第一类用户是“典型管理者”,年龄大约在30-40岁之间,对使用A软件态度相对较积极,认为公司的管理是很自由的。其样本共有200人
第二类用户是“个性型员工”,年龄大约在20-25岁,对使用A软件态度波动较大,认为公司的管理很不自由。其样本共有400人
第三类用户是“安稳型员工”,年龄大约在25-30岁,对使用A软件态度比较消极,觉得公司的管理是相对自由的。其样本共有600人
接下来使用R来生成以上描述的三类用户的数据,代码如下(对代码没兴趣的同学可以直接跳过):
#定义每类的数据量n1=200n2=400n3=600#画像1的数据set.seed(1000)age1=rnorm(n1,mean=35,sd=3)set.seed(1100)attitude1=rnorm(n1,mean=8,sd=1.5)set.seed(1200)dof1=rnorm(n1,mean=8,sd=1)#画像2的数据set.seed(2000)age2=rnorm(n2,mean=23,sd=2)set.seed(2100)attitude2=rnorm(n2,mean=5,sd=2)set.seed(2200)dof2=rnorm(n2,mean=4,sd=1.5)#画像3的数据set.seed(3000)age3=rnorm(n3,mean=28,sd=2)set.seed(3100)attitude3=rnorm(n3,mean=3,sd=1.5)set.seed(3200)dof3=rnorm(n3,mean=7,sd=1.5)#合并所有数据age=c(age1,age2,age3)attitude=c(attitude1,attitude2,attitude3)dof=c(dof1,dof2,dof3)orig_type=c(rep(1,n1),rep(2,n2),rep(3,n3))data=data.frame(age,attitude,dof,orig_type)#输出到表格write.csv(data,"F:/R/R-cluster.csv")
简而言之,三类用户的特征是这样的:

用SPSS做K均值聚类
接下来使用R生成的数据进行K均值聚类,看看分析得出的结果与我们预设的类别的关系。
1. 先看看三个变量的相关性矩阵:

我们发现几个变量之间相关性都不高,因此可以全部作为聚类的变量进入后续分析过程。
2. 接下来对三个变量进行标准化:
SPSS操作:分析-描述统计-描述-勾选“将标准化得分另存为变量”
3. K均值聚类
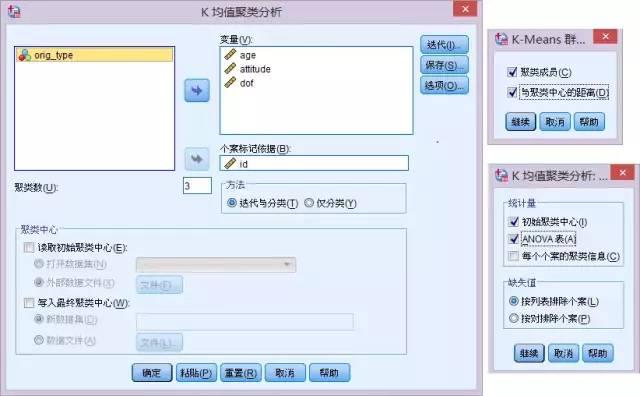
SPSS操作:分析-分类-K均值聚类
填写聚类数:3
“保存”:勾选聚类成员、与聚类中心的距离
“选项”:勾选ANOVA表
4. 查看方差分析结果:
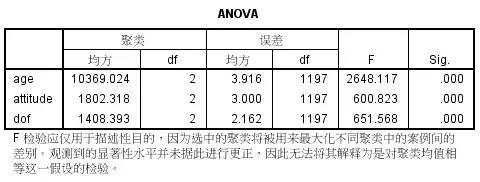
聚类分析得出的类别在三个变量上都呈现出了显著差异,可见三个变量在聚类分析中都起到了作用,当前聚类分析结果可以保留。
预设类别与聚类结果对比
先看看聚类得出的结果:
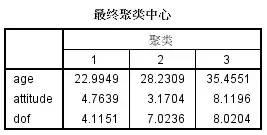

跟我们最初定义的用户特征对比(详见上面的表格),发现聚类分析对用户类别的还原度非常高!聚类得出的几个类别和最初定义的类别在三个变量的均值和类别样本数上差异都很小(注意类别的顺序不同)。
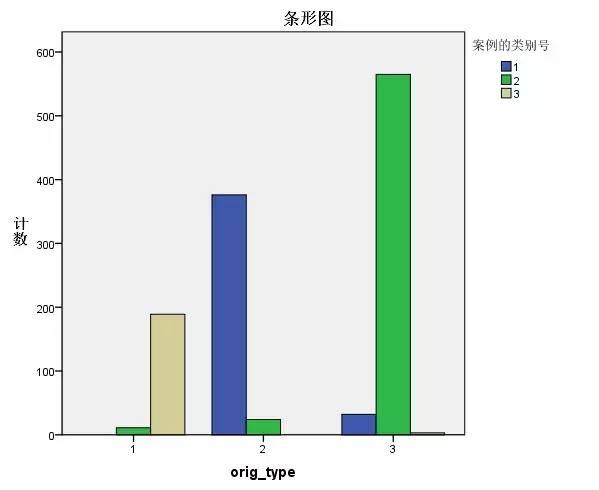
我们再用一个交叉表,看看样本的分布情况:
SPSS操作:分析-描述统计-交叉表,将原始数据定义的类别和K均值聚类得出的类别分别放在行和列变量中。
勾选“显示复式条形图”。

横轴表示我们预设的类别,纵轴表示聚类分析得出的类别。可以看出非常明显的对应关系。
第一类用户大部分被聚类为类别3
第二类用户大部分被聚类为类别1
第三类用户大部分被聚类为类别2
聚类分析定义出来的用户群体,不仅仅在属性上与预设的一致,连用户构成都很一致。
长按下方海报添加微信领取【100份简历模板】

· 爱数据每周免费直播 ·
直播主题:数据分析岗位工作内容及规划
直播内容:
岗位JD解读:数据分析日常、专题和支持工作内容分享
不同经验及薪资对于技能、思维深度和数据管理的要求
企业对数据团队的发展限制及企业不同阶段对数据团队的要求
数据分析师职业生涯的关键是什么?
直播时间:6月22日明晚20:30准时直播分享
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









