






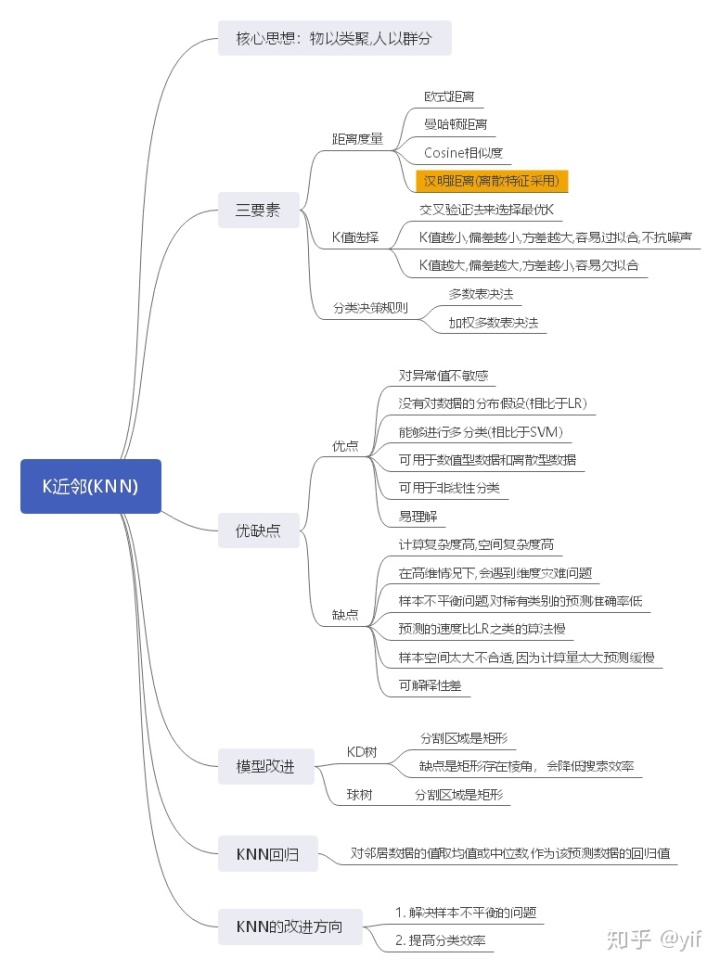
K近邻(KNN)
个人认为这个算法本质是一种基于记忆的学习,类似于人的一种罕见疾病——超忆症。
当然光有记忆对于这种算法还是不够的,还需要一种决策标准——距离+投票。
KNN基本思想
核心思想是:物以类聚,人以群分
算法步骤:
- 存储下训练集中的对象(记忆)
- 计算测试对象到训练集中每个对象的距离(距离计算)
- 按照距离的远近排序(排序)
- 选取与当前测试对象最近的k个的训练对象,作为该测试对象的邻居(找邻居)
- 统计这k个邻居的类别频率(统计)
- k个邻居里频率最高的类别,即为测试对象的类别(决策)
算法内容
数据归一化
为什么要进行归一化? 之前在LR中讲到过。这里举一个具体实例: 比如人的数据有两个特征:身高和体重,我们的身高的单位是米(m),而体重的单位是千克(kg).身高的最小单元会是0.01米,而体重的最小单元会是1kg。这样会导致的问题是:(1.76m,70kg)和(0.76m,70kg)的距离与(1.76m,70kg)和(1.76m,71kg)的距离相等。显然,这种比较是不公的。
不同维度的物理量之间往往具有不同的量纲和单位,这样会造成维度之间可比性较差,为了消除物理量之间绝对值相差太大,需要对样本数据集进行标准化处理,保证各个物理量之间处于同一个数据量之下,消除不同量纲之间的差异。
- 线性归一化:
- 标准化
KNN的三要素:距离度量,k值的选择,分类决策规则
距离度量
- 欧氏距离
- 曼哈顿距离
- cosine similarity
- 汉明距离 比如:1011101与1001001之间汉明距离是2.他表示两个(相同长度)字对应位的不同数量
k值的选择
K近邻算法对K的选择非常敏感。K值越小意味着模型复杂度越高,从而容易产生过拟合;K值越大则意味着整体的模型变得简单,学习的近似近似误差会增大。
可以采用交叉验证法来选择最优的K。
分类决策规则
K近邻算法中的分类决策多采用 多数表决 的方法进行。它等价于寻求经验风险最小化。
但这个规则存在一个潜在的问题:有可能多个类别的投票数同为最高。这个时候,究竟应该判为哪一个类别?
- 从投票数相同的最高类别中随机地选择一个;
- 通过距离来进一步给票数加权;
- 减少K的个数,直到找到一个唯一的最高票数标签。
其他的一些表决方法有:加权多数表决法:可以采用权重与距离成反比
KNN的优缺点
优点
- 对异常值不敏感
- 没有对数据的分布假设
- 能进行多分类,不像SVM。
- 可用于数值型数据和离散型数据
- 可用于非线性分类
- 易理解
缺点
- 计算复杂度高,空间复杂性高
- 在高维情况下,会遇到维度灾难问题
- 样本不平衡问题,对稀有类别的预测准确率低
- 预测的速度比LR之类的算法慢
- 样本空间太大不合适,因为计算量太大预测缓慢
- 可解释性差
KNN的改进——KD树
KD树就是为了解决复杂度大的问题。
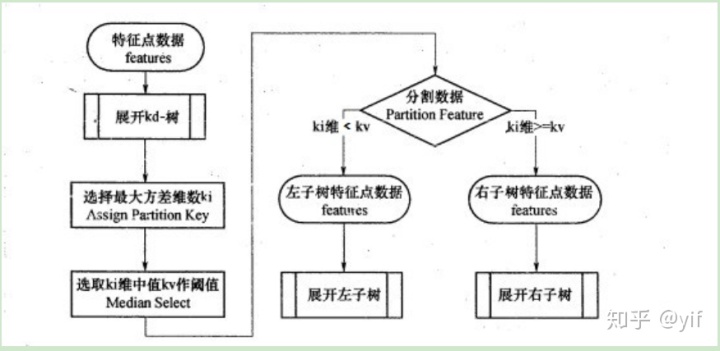
KD树的本质是一个二叉树,即一个根节点,划分为左子树和右子树。所以KD树的构建无非是两个问题:根节点的选择,左右子树的划分规则。
如何构建KD树?
- 选定一个维度i,选择这个维度上的中位数的所在点为根节点(选择维度i的依据可以是因为其方差大)
- 所有维度i上比这个中位数小的数据,都划分为左子树;反之,则划分为右子树
- 对于左右两个子树,重复第一步,选择一个新的维度继续划分。
- 重复以上过程,直到所有子集合不能再划分为止。
KD树搜索算法
这个搜索过程与二叉搜索树极其类似。
根据测试数据在对应节点处的维度上的值的大小划分到左右分支中。
直到划分到某个区域里的数据数量小于等于k,然后开始在其附近查找离它最近的k个数据点。
这样的方法就可以避免了搜索时要搜索全部数据的问题。
除了KD树之外还有球树,不同点在于前者的分割块是矩形块,后者的分割块是超球体。
KD树形如:
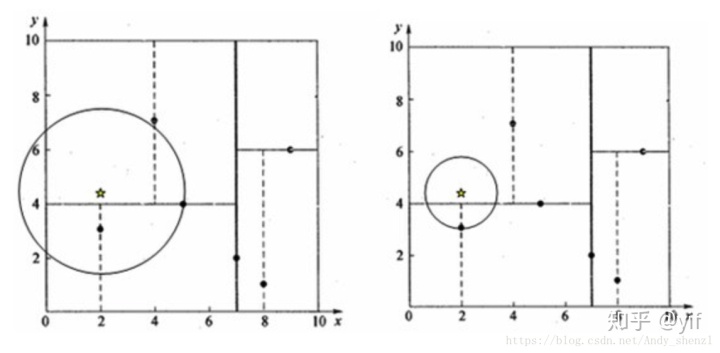
可以从上面看出,KD数在获取k近邻的时候是用圆的,一旦该圆与某个矩形区域相交,就要遍历该区域内的点找是否有其近邻。所以KD树的问题在于它的分割块的形状是矩形的,因为存在角,所以搜索效率会有问题。因此提出了球树。
球树形如
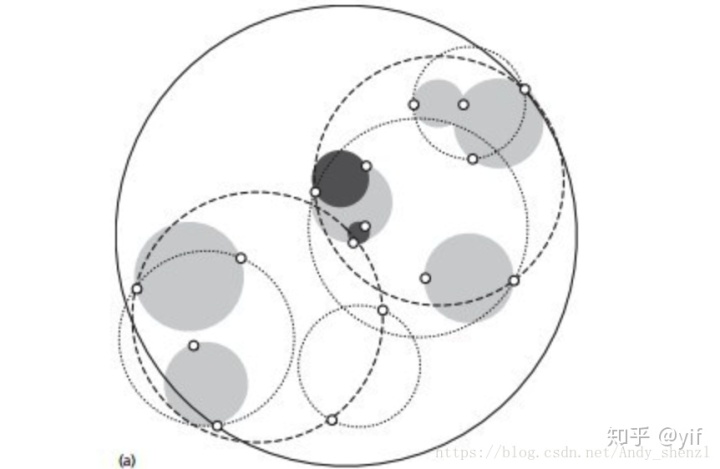
具体可以看K近邻法(KNN)原理小结
KNN回归
算法步骤:
- 存储下训练集中的对象(记忆)
- 计算测试对象到训练集中每个对象的距离(距离计算)
- 按照距离的远近排序(排序)
- 选取与当前测试对象最近的k个的训练对象,作为该测试对象的邻居(找邻居)
- 对这些邻居数据的值取均值或中位数,作为该测试数据的回归值
KNN的应用
- 分类
- 文本分类
- 用户推荐
- 离群点检测(异常检测)
- 回归
KNN实践
import numpy as np
from matplotlib import pyplot as plt
from sklearn import neighbors
input_dim=2
class_num=2
data_num=50
test_data_num=20
Y=np.random.randint(size=(data_num,1),low=0,high=class_num)
X=(np.random.rand(data_num,input_dim)+1)*(Y+1)##+1是为了分离数据
X = X.astype(np.float32)
Y_test=np.random.randint(size=(test_data_num,1),low=0,high=class_num)
X_test=(np.random.rand(test_data_num,input_dim)+1)*(Y_test+1)##+1是为了分离数据
colors=['r' if l== 0 else 'b' for l in Y[:,0]]
plt.scatter(x=X[:,0],y=X[:,1],c=colors)
plt.xlabel("Scaled age (in yrs)")
plt.ylabel("Tumor size (in cm)")
plt.show()上面是数据生成和可视化
KNN_model=neighbors.KNeighborsClassifier()
KNN_model.fit(X,Y)
Y_test_predict=KNN_model.predict(X_test)
colors=['r' if l== 0 else 'b' for l in Y_test_predict]
plt.scatter(X_test[:,0],X_test[:,1],c=colors)上面是模型训练和预测















 1122
1122











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









