





这是《ESL》
第11章"neural networks"
1~5节
1.introduction
神经网络的核心是通过线性组合进行自动特征提取,然后对这些特征进行非线性建模。以下我们先讨论半参数统计和平滑中投影模型(projection pursuit model),然后介绍神经网络。
2.projection pursuit regression (PPR)
PPR模型的形式,
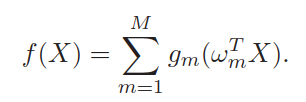
原始输入
PPR模型的一个特点是增大了模型的表达能力,它先进行线性组合再进行非线性变换,可以产生很多其它新的属性。如假设
实际上如果
然而缺点是解释性差,普通的线性模型我们可以清楚地看到响应变量随某个自变量的变化,比例模型(cox模型)可以看到各个属性间的比例风险,但在PPR模型中,经过组合产生了大量类似
目标函数,

优化这个函数时我们同样要考虑由于模型过于复杂而导致过拟合的问题。
我们首先从 M=1 开始,此时去掉下标
(1)给定
(2)给定

代入目标函数得,
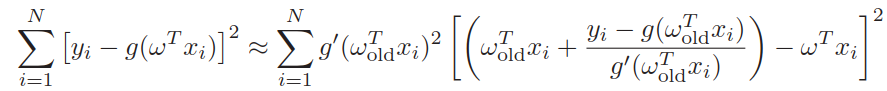
问题变为如何最小化上图右边的式子,右边的式子可以看成是对点
总的过程是初始随机给定
如果有更多的
实际中
3.neural networks
介绍神经网络的基本结构。
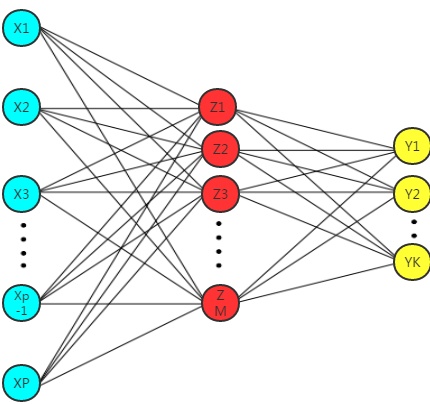
上图就是一个带一个隐藏层的神经网络,输入层-隐藏层-输出层。把每个圈都称为一个神经元,神经元之间的连接称为突触。这个模型既可以用来做回归也可以用来分类,回归是输出仅有一个神经元
神经网络的训练分为前向过程和逆向过程,这里先讲前向过程,下节为逆向过程。
前向过程(上图从左到右),
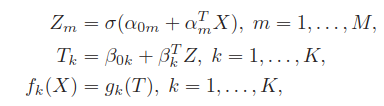
激活函数实际是模仿生物神经元的域电位,当刺激达到阈值时神经元细胞才产生兴奋介质或抑制介质,生物神经细胞中的阈值是“硬”的,即仅但刺激超过阈值才产生兴奋或抑制,对应的数学模型中的激活函数是RELU=max(0,x)函数,如下图

sigmoid函数则属于“软”阈值,

可以看到带一个隐藏层、输出只有一个y的NN和PPR模型几乎相同,先对输入 X 进行线性变换,然后经过一个非线性函数,最后将上一步的输出组合起来作为最终输出。
4.fitting neural networks
这里仅使用链式规则推导只带一个隐藏层的NN,关于多层的使用链式和优化方法推的看这里
逆向传播,
参数总个数为,
回归问题时的目标函数,使用误差平方和,

这里
分类问题时的目标函数,使用交叉熵,
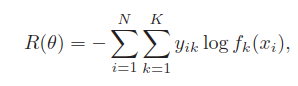
说明下经过softmax函数,使用交叉熵为目标函数,实际是使用极大似然估计。
案例
对数似然,
总的误差,
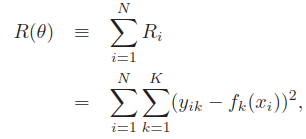
一部分是最后的隐藏层到输出层的参数,
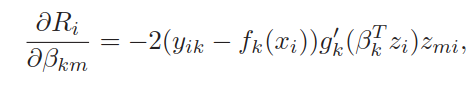
另一部分是最后的隐藏层直到输入层的参数,

上面似乎没有说到偏置
上两式可以简写为,
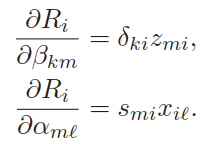
被称为逆向传播公式。可以看到其中的

接着是梯度下降,
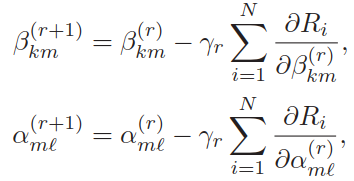
总的过程:
(1)初始化参数;
(2)前向传播,将案例一个个输入模型,保留每个案例在每个神经元的输出值;
(3)逆向传播,使用前向传播保留的值计算每个参数在每个案例的梯度,然后求和为总梯度,如参数
(4)重复(2)(3)直到参数收敛。
BGD(批量梯度下降)
上述过程每次参数更新都使用了所有案例,使得
但批量计算也有缺点,任意选一个初始值,目标函数只会往附近局部极小值点走,且无法跳出这个局部极小值点(目的自然是希望获得最小值点);另一个缺点是如果训练集很大,则每次迭代计算所有案例前向传播过程,并保存每个案例的所有神经元的输出值,会导致设备的内存不够。
OGD(在线梯度下降)
即在线学习,取出训练集的第一个案例,进行前向传播,然后逆向传播更新参数;接着取出第二个案例,前向传播,逆向传播;... ... 取出最后一个后,又从训练集的第一个案例开始,直到参数收敛。和BGD的不同点是BGD每次迭代对
SGD(随机梯度下降)
对训练集的所有案例进行一次随机排序,取出第一个案例进行前向逆向传播,取出第二个案例进行前向逆向传播,...,取出最后一个后,再对重新整个训练集进行随机排序,然后取出第一个案例... ...,循环至参数收敛
MBGD(小批量梯度下降)
每次从训练集中随机选择较少样本(如10个),对这10个样本进行批量梯度下降,迭代固定次数后,再随机选择10个进行批量梯度下降迭代固定次数,... ... 至参数收敛。
显然OGDSGDMBGD每次迭代都对存储要求少,且易跳出局部极小值点。
关于学习率
BP算法仅使用一阶逼近收敛很慢,一种常见的加快方法是使用二阶逼近,但NN的参数很多导致二阶逼近方法需要的Hessian 矩阵很大,不一定可逆且求逆很困难,一般不用。
到这里我们就对神经网络有了一个初步的了解,这里我们来看看网上有人编的可视化的神经网络训练实例 Tensorflow — Neural Network Playground
5.some issues in training neural networks
NN中的重要问题
[1]初始化参数
初始化参数不能过于接近0,也不能太大,服从标准正态分布或均匀分布是一个较好的选择。我们看看参数更新过程就明白了,
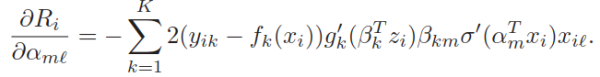
其中的sigmoid函数的导函数为,
当所有参数初始值均十分接近于0,导致
当所有参数初始值直接取0,初始值取接近于0时参数向量有方向,
当
[2]过拟合
显然一旦NN的输入维度高及增加层数和每层的神经元个数,参数会迅速变多,于是模型会很容易过拟合。
防止过拟合的一般方法,
(1)提前终止训练
(2)对损失函数加正则项(如
(3)dropout 方法。即随机将某些参数直接变为0。
[3]标准化输入
[4]NN隐藏层的层数及每层上神经元个数的决定
没有激活函数时,没有隐藏层的NN和含有多个隐藏层的NN是等价。有隐藏层时,实际一个隐藏层只要有足够多的神经元就可以拟合任何函数,但同样多的隐藏层神经元可以分配到更多的隐藏层中去,这样的NN结构训练更加高效。
隐藏层神经元过少可能无法表达过于复杂的问题,过多额外的参数会被正则项压缩到0。最常见的方法就是尽量选个较大的模型然后用正则自动压缩。
[5]众多的极小值
目标函数是非凸的, 因此有许多极小值点,初始点的不同选择可能会得到不同极小值点,而我们的目的是获得最小值点。
一个好的方法是多选几个初始点,分别进行训练,选择误差最小的版本;
更好的办法如使用不同的初始点训练得到多个NN,将这些NN的结果平均为最终结果,这比将这些NN的每个对应的参数进行平均获得一个NN的预测要好;
还有一种办法是使用bagging的方法,先对训练样本添加了随机扰动,然后使用不同初始点获得多个NN,结果为多个NN预测的平均值。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









