





概述
k-means算法是一种聚类算法,所谓聚类,是指在数据中发现数据对象之间的关系,将数据进行分组,组内的相似性越大,组间的差别越大,则聚类效果越好。聚类算法与分类算法不同,聚类算法属于无监督学习,通俗来讲:分类就是向事物分配标签,聚类就是将相似的事物放在一起。聚类算法通常用来寻找相似的事物,比如:银行寻找优质客户,信用卡诈骗,社交划分社区圈等等。
原理
首先K-means中的K类似与KNN中的参数K,是指将数据聚类成K个类别。
算法原理:
先从没有标签的元素集合A中随机取K个元素,作为K个子集各自的重心。分别计算剩下的元素到K个子集重心的距离,根据距离将这些元素分别划归到最近的子集。(这里的距离可以使用欧式距离或其他的距离量度)根据聚类结果,重新计算重心(即子集中所有元素各个维度的算数平均数)将集合A中全部元素按照新的中心然后再重新聚类重复第4步,直到聚类结果不再发生变化。示例
看着算法的步骤有点懵逼,我们来看个简单的例子。1.假设画布上有四个点,如下:
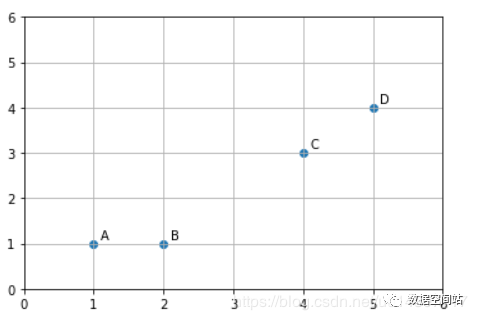
我们想将其聚类成两类,首先我们先随机选取两个点,比如A,B两点选取两个类别的重心点,然后分别计算所有元素到这两个重心的距离,此处采用欧式距离。计算如下:
dotA = np.array([1,1])dotB = np.array([2,1])DATA = [[1,1],[2,1],[4,3],[5,4]]def getDistances(data,dot): distances = [] for dt in data: d = round(sqrt(np.sum((dt-dot)**2)),3) distances.append(d) return np.array(distances)disA = getDistances(DATA,dotA)disB = getDistances(DATA,dotB)print("距离第一个重心点的距离:" , disA)print("距离第二个重心点的距离:" , disB)输出:
A B C D距离第一个重心点的距离:[0. 1. 3.606 5. ]距离第二个重心点的距离:[1. 0. 2.828 4.243]然后我们根据距离进行分类:
print(disA#距离第一个重心点近的是True#out:[ True False False False]print(disA>disB) #距离第二个重心点近的是True#out:[False True True True]所以分类后,A聚为一类,将BCD聚为一类。如图
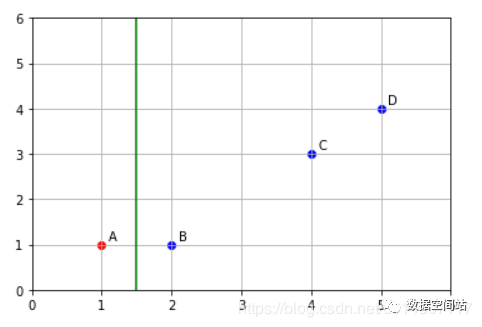
2.然后我们根据聚类结果,再次计算重心。第一个类别的重心重新计算后和原值一样没有变化,对第二个类别的重心重新计算。j计算后新的重心为
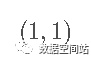
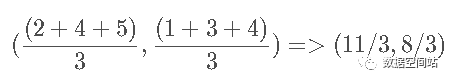
然后继续计算四个点到重心的距离:
A B C D距离第一个重心点的距离:[0. 1. 3.606 5. ]距离第二个重心点的距离:[3.145 2.357 0.471 1.886]继续根据距离分类:
print(disA#距离第一个重心点近的是True#out:[ True True False False]print(disA>disB) #距离第二个重心点近的是True#out:[False False True True]即将AB聚为一类,CD聚为一类,如下图:
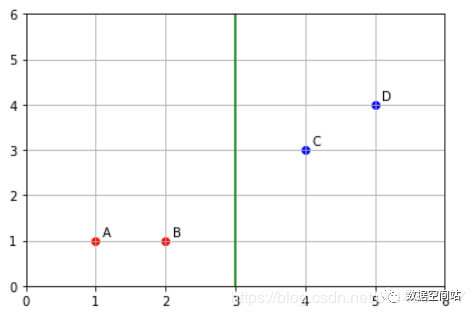
似乎已经达到我们想要的结果,依照算法流程可以验证一下,如果再一次划分重心,聚类结果不改变,那么这便是聚类的最终结果。3.再次重新计算重心:
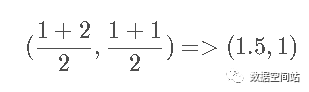
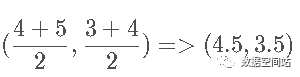
计算四个点到新重心的距离:
A B C D距离第一个重心点的距离:[0.5 0.5 3.202 4.61 ]距离第二个重心点的距离:[4.301 3.536 0.707 0.707]继续根据距离分类:
print(disA#距离第一个重心点近的是True#out:[ True True False False]print(disA>disB) #距离第二个重心点近的是True#out:[False False True True]我们发现聚类后的结果和上次的一样,所以聚类算法停止迭代,聚类完成。所以聚类后的结果为:AB为一类,CD为一类
Sklearn实现
#使用sklearn生成聚类数据集import numpy as npimport matplotlib.pyplot as pltfrom sklearn.datasets.samples_generator import make_blobs# data为样本特征,target为样本簇类别, 共1000个样本,每个样本2个特征,共4个簇,簇中心在[-1,-1], [0,0],[1,1], [2,2], 簇方差分别为[0.4, 0.2, 0.2],随机种子为666data,target=make_blobs(n_samples=1000,n_features=2,centers=[[-1,-1], [0,0], [1,1], [2,2]],cluster_std=[0.4, 0.2, 0.2, 0.2], shuffle=True, random_state=666)plt.scatter(data[:, 0], data[:, 1], marker='o')plt.show()生成的结果如下图:
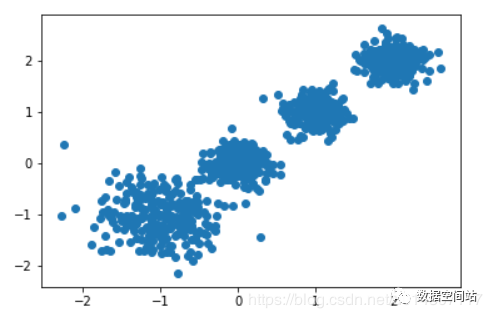
使用sklearn进行聚类,我们首先来看一下sklearn中kmeans的参数代表的意义 KMeans类的主要参数有:
n_clusters: 即我们的k值,一般需要多试一些值以获得较好的聚类效果。下文会说明K值得选取 max_iter:最大的迭代次数,一般如果是凸数据集的话可以不管这个值,如果数据集不是凸的,可能很难收敛,此时可以指定最大的迭代次数让算法可以及时退出循环。 n_init:用不同的初始化重心运行算法的次数。由于K-Means是结果受初始值影响的局部最优的迭代算法,因此需要多跑几次以选择一个较好的聚类效果,默认是10,一般不需要改。如果你的k值较大,则可以适当增大这个值。 init:即初始值选择的方式,可以为完全随机选择'random',优化过的'k-means++'或者自己指定初始化的k个质心。一般建议使用默认的'k-means++'。algorithm:有“auto”, “full” or “elkan”三种选择。"full"就是我们传统的K-Means算法, “elkan”是对于稠密特征的数据改进的算法。默认的"auto"则会根据数据值是否是稀疏的,来决定如何选择"full"和“elkan”。一般来说建议直接用默认的"auto"from sklearn.cluster import KMeans#首先来尝试分为2类KMeansCluster = KMeans(n_clusters=2, random_state=666)y2 = KMeansCluster.fit_predict(data)plt.scatter(data[:, 0], data[:, 1], marker='o',c=y2)plt.show()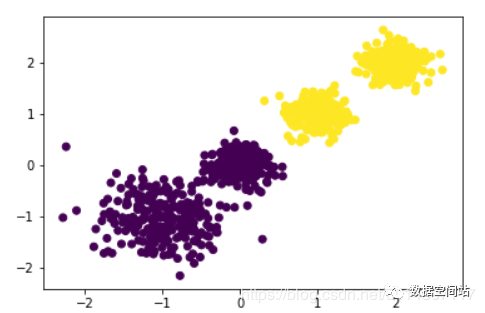
#尝试分为三类KMeansCluster3 = KMeans(n_clusters=3, random_state=666)y3 = KMeansCluster3.fit_predict(data)plt.scatter(data[:, 0], data[:, 1], marker='o',c=y3)plt.show()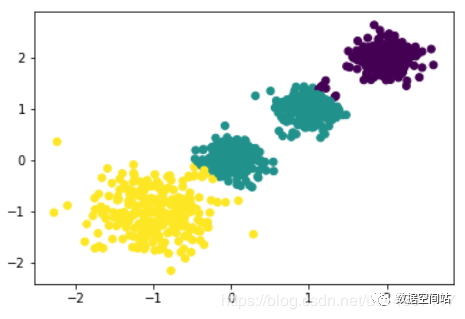
我们继续划分为四类,结果如下图:
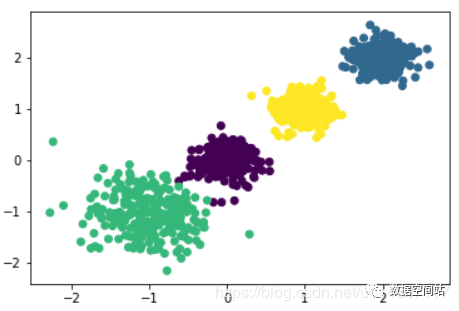
当我们继续划分为5类的时候,就会发现如下图的情况:
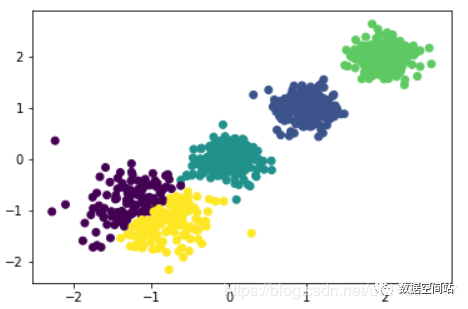
明显发生了过拟合的情况,所以问题来了,当我们可以可视化聚类结果的时候,比如上面这个例子,我们可以知道K=4的时候,是最合适的。但是当不能可视化聚类结果的时候,我们如何知道K选择到什么地步聚类效果是最好的?所以我们需要和以前的算法意义,评估聚类效果。
聚类效果的评估
不像监督学习的分类问题和回归问题,我们的无监督聚类没有样本输出,也就没有比较直接的聚类评估方法。但是我们可以从簇内的稠密程度和簇间的离散程度来评估聚类的效果。常见的方法有轮廓系数Silhouette Coefficient和Calinski-Harabasz Index(CH)。这里使用CH法来评估。
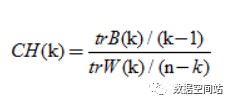
其中m为训练集样本数,k为类别数。Bk为类别之间的协方差矩阵,Wk为类别内部数据的协方差矩阵。tr为矩阵的迹。通过公式可以得出CH越大代表着类自身越紧密,类与类之间越分散,即更优的聚类结果。我们可以求解上面几次聚类结果的CH值
from sklearn import metrics# 求解CH值y2_score = metrics.calinski_harabaz_score(data, y2) y3_score = metrics.calinski_harabaz_score(data, y3) y4_score = metrics.calinski_harabaz_score(data, y4) y5_score = metrics.calinski_harabaz_score(data, y5) disY = [y2_score,y3_score,y4_score,y5_score]#绘制图像plt.plot([2,3,4,5], disY , 'bx-')plt.show()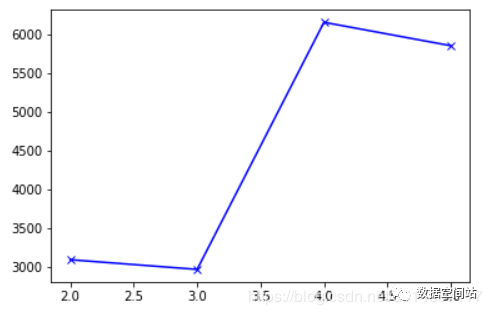
我们发现K=4时,CH值是最大的,即聚类效果是最好的。
KMeans存在的几个问题
初始重心选择
上面的例子中,初始重心是随机选取的,但是数据量特别大时,随机选取的可能会造成迭代多次。所以初始重心该如何选取,因为不是一类的,所以重心应该是离得越远越好。于是可以采用Kmeans++算法:假设已经选取了n个初始中心(0
K值选择
有时候我们并不知道数据集适合划分为多少类,所以也不知道K值该如何选取。此时可以计算多个K值对应的损失函数的值,选取在拐点的k值即可。由于折线像胳膊,拐点即肘部,又称为肘部法则。参考之前损失函数的定义,我们肯定希望每个点到聚类重心点的距离越小越好,所以此处的损失函数可以理解为:每个点到聚类重心的距离的平方和的均值 可以将每个K值对应的损失函数值求解出来,如下:
from scipy.spatial.distance import cdistK = range(1, 10)disJ = []for k in K: kmeans = KMeans(n_clusters=k) kmeans.fit(data) #理解为计算某个与其所属类聚中心的欧式距离 #最终是计算所有点与对应中心的距离的平方和的均值 disJ .append(sum(np.min(cdist(data, kmeans.cluster_centers_, 'euclidean'), axis=1)) / data.shape[0])plt.plot(K, disJ , 'bx-')plt.show()求解的图如下:
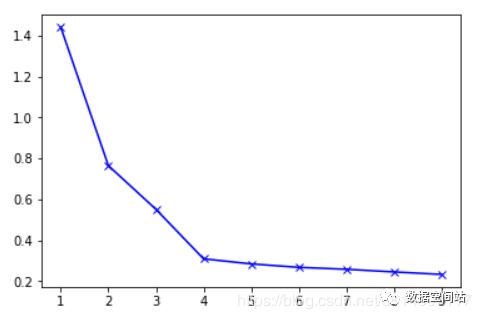
我们可以看到图中貌似有两个“肘部”,但是可以注意到在k=4之后,损失函数的值的变化越来越小,所以我们选择K=4。同时也符合我们上面根据评估效果得到的结论。
基于密度聚类(DBSCAN)
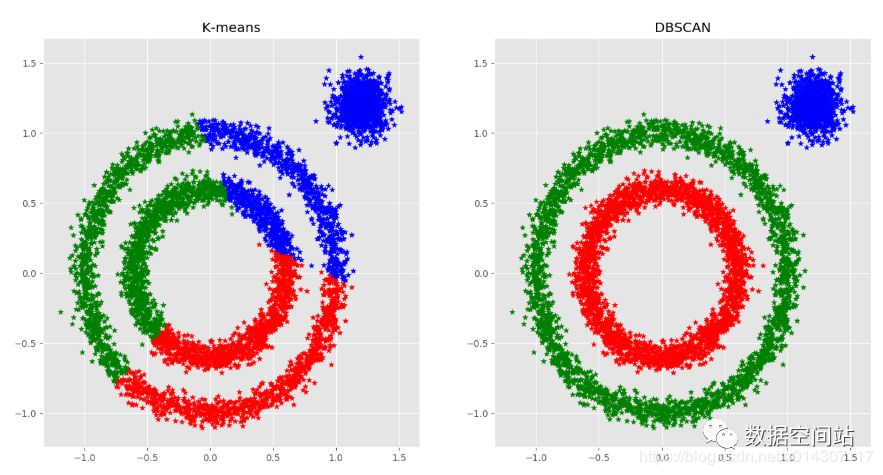
对于非球面形状的数据,Kmeans数据无法处理,比如下图:对于Kmeans来说,根据距离聚类,会聚成左图,显然结果不是我们想要的,此时便需要基于密度聚类,比如DBSCAN,如右图:
mini batch kmeans
当数据量比较大时,聚类收敛比较慢,可以使用mini batch kmeans。其具体做法是在原有的数据量上随机采样一批合适大小的数据,作为样本,对这些样本进行kmeans聚类。
References
[1] 用scikit-learn学习K-Means聚类: https://www.cnblogs.com/pinard/p/6169370.html
[2] 深入理解K-Means聚类算法: https://blog.csdn.net/taoyanqi8932/article/details/53727841[3] K-means算法介绍: https://www.bilibili.com/video/av37947862?p=61[4] K-means聚类算法的三种改进(K-means++,ISODATA,Kernel K-means)介绍与对比: https://www.cnblogs.com/yixuan-xu/p/6272208.html

















 4864
4864











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









