






1.k-means 聚类算法思想
kmeans算法又名k均值算法,K-means算法中的k表示的是聚类为k个簇,means代表取每一个聚类中数据值的均值作为该簇的中心,或者称为质心,即用每一个的类的质心对该簇进行描述。
其算法思想大致为:先从样本集中随机选取 k个样本作为簇中心,并计算所有样本与这 k个“簇中心”的距离,对于每一个样本,将其划分到与其距离最近的“簇中心”所在的簇中,对于新的簇计算各个簇的新的“簇中心”。
根据以上描述,我们大致可以猜测到实现kmeans算法的主要四点:
(1)簇个数 k 的选择
(2)各个样本点到“簇中心”的距离
(3)根据新划分的簇,更新“簇中心”
(4)重复上述2、3过程,直至"簇中心"没有移动
优缺点:
- 优点:容易实现
- 缺点:可能收敛到局部最小值,在大规模数据上收敛较慢
下图是来自西瓜书的k均值算法的思想

K是我们事先给定的聚类数, C i C_{i} Ci代表样例i与k个类中距离最近的那个类, C i C_{i} Ci的值是1到k中的一个。质心 μ i \boldsymbol{\mu}_{i} μi代表我们对属于同一个类的样本中心点的猜测,拿星团模型来解释就是要将所有的星星聚成k个星团,首先随机选取k个宇宙中的点(或者k个星星)作为k个星团的质心,然后第一步对于每一个星星计算其到k个质心中每一个的距离,然后选取距离最近的那个星团作为 C i C_{i} Ci,这样经过第一步每一个星星都有了所属的星团;第二步对于每一个星团,重新计算它的质心(对里面所有的星星坐标求平均)。重复迭代第一步和第二步直到质心不变或者变化很小。
给定样本集 D = { x 1 , x 2 , … , x m } D=\left\{\boldsymbol{x}_{1}, \boldsymbol{x}_{2}, \ldots, \boldsymbol{x}_{m}\right\} D={x1,x2,…,xm},“k 均值” *(k-*means )算法针对聚类所得簇划分 C = { C 1 , C 2 , … , C k } \mathcal{C}=\left\{C_{1}, C_{2}, \ldots, C_{k}\right\} C={C1,C2,…,Ck}最小化平方误差
E
=
∑
i
=
1
k
∑
x
∈
C
i
∥
x
−
μ
i
∥
2
2
E=\sum_{i=1}^{k} \sum_{\boldsymbol{x} \in C_{i}}\left\|\boldsymbol{x}-\boldsymbol{\mu}_{i}\right\|_{2}^{2}
E=i=1∑kx∈Ci∑∥x−μi∥22
其中
μ
i
=
1
∣
C
i
∣
∑
x
∈
C
i
x
\boldsymbol{\mu}_{i}=\frac{1}{\left|C_{i}\right|} \sum_{\boldsymbol{x} \in C_{i}} \boldsymbol{x}
μi=∣Ci∣1∑x∈Cix是簇的均值向量.直观来看上式在一定程度上刻画了簇内样本围绕簇均值向量的紧密程度值越小,则簇内样本相似度越高.
关于K-means聚类算法的一些需要注意的点:
- k 值的选择:一般来说,我们会根据对数据的先验经验选择一个合适的 k 值,如果没有什么先验知识,则可以通过交叉验证选择一个合适的 k 值。
- k 个初始化的质心的选择:由于它是启发式方法,k个初始化的质心的位置选择对最后的聚类结果和运行时间都有很大的影响,因此需要选择合适的 k 个质心,最好这些质心不能太近。(在初始点选择这方面做了优化后,就是 **K-means++**算法)。
2.代码实现
2.1引入相关库
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
2.2生成数据集
# make_blobs:生成聚类的数据集
# n_samples:生成的样本点个数,n_features:样本特征数,centers:样本中心数
# cluster_std:聚类标准差,shuffle:是否打乱数据,random_state:随机种子
X, y = make_blobs(n_samples=150, n_features=2,centers=3, cluster_std=0.5,shuffle=True, random_state=0)
# 散点图
# c:点的颜色,marker:点的形状,edgecolor:点边缘的形状,s:点的大小
plt.scatter(X[:, 0], X[:, 1],c='white', marker='o',edgecolor='black', s=50)
plt.show()
下图是以散点图显示的三簇数据集

2.3定义、训练、预测模型
# 定义模型
# n_clusters:要形成的簇数,即k均值的k,init:初始化方式,tot:Frobenius 范数收敛的阈值
model = KMeans(n_clusters=3, init='random',n_init=10, max_iter=300, tol=1e-04, random_state=0)
# 训练加预测
y_pred = model.fit_predict(X)
# 画出预测的三个簇类
plt.scatter(
X[y_pred == 0, 0], X[y_pred == 0, 1],
s=50, c='lightgreen',
marker='s', edgecolor='black',
label='cluster 1'
)
plt.scatter(
X[y_pred == 1, 0], X[y_pred == 1, 1],
s=50, c='orange',
marker='o', edgecolor='black',
label='cluster 2'
)
plt.scatter(
X[y_pred == 2, 0], X[y_pred == 2, 1],
s=50, c='lightblue',
marker='v', edgecolor='black',
label='cluster 3'
)
# 画出聚类中心
plt.scatter(
model.cluster_centers_[:, 0], model.cluster_centers_[:, 1],
s=250, marker='*',
c='red', edgecolor='black',
label='centroids'
)
plt.legend(scatterpoints=1)
plt.grid()
plt.show()
结果展示

一般来说,针对数据集,我们会有一个大致的先验k值,但在没有先验信息时,就需要自己尝试不同的 k 值了。这时,我们引入一个 **惯性指标(inertia)** 来帮助我们选择 k 值。
2.4惯性指标(inertia)
K-Means的惯性指标计算方式是:每个样本与最接近的质心的均方距离的总和。
下面使用 不同的 k 值来训练看该惯性指标如何变化:
# 计算inertia随着k变化的情况
distortions = []
for i in range(1, 10):
model = KMeans(
n_clusters=i, init='random',
n_init=10, max_iter=300,
tol=1e-04, random_state=0
)
model.fit(X)
distortions.append(model.inertia_)
# 画图可以看出k越大inertia越小,追求k越大对应用无益处
plt.plot(range(1, 10), distortions, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('Distortion')
plt.show()
```

一般地,惯性指数越小模型越好,但伴随K值的增大,惯性下降的速度变的很慢,因此我们选择“肘部”的K值,作为最优的K值选择。
3.K-means算法补充
3.1对初始化敏感
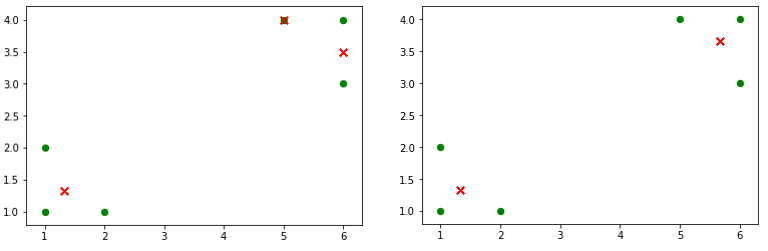
初始质点k给定的不同,可能会产生不同的聚类结果。如下图所示,右边是k=2的结果,这个就正好,而左图是k=3的结果,可以看到右上角得这两个簇应该是可以合并成一个簇的。
改进:
对k的选择可以先用一些算法分析数据的分布,如重心和密度等,然后选择合适的k
3.2会收敛到局部最小
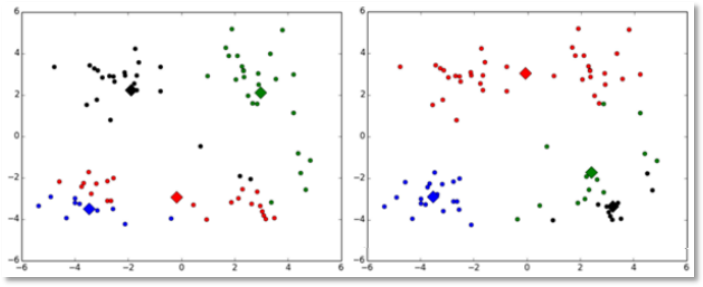
对k个初始质心的选择比较敏感,容易陷入局部最小值。例如,我们上面的算法运行的时候,有可能会得到不同的结果,如下面这两种情况。K-means也是收敛了,只是收敛到了局部最小值:
改进:
有人提出了另一个成为二分k均值(bisecting k-means)算法,它对初始的k个质心的选择就不太敏感
3.3对非球状的数据分布存在局限性
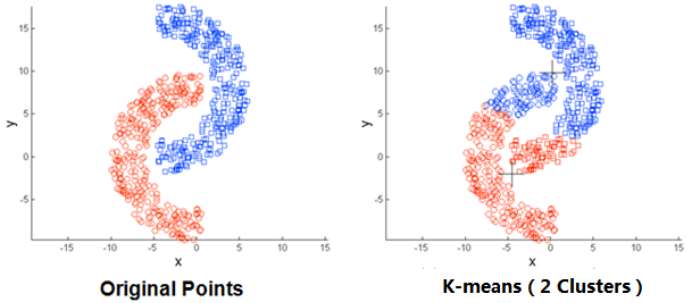
3.4数据集比较大的时候,收敛会比较慢
4.小结
- 聚类是一种无监督的学习方法。聚类区别于分类,即事先不知道要寻找的内容,没有预先设定好的目标变量。
- 聚类将数据点归到多个簇中,其中相似的数据点归为同一簇,而不相似的点归为不同的簇。相似度的计算方法有很多,具体的应用选择合适的相似度计算方法
- K-means聚类算法,是一种广泛使用的聚类算法,其中k是需要指定的参数,即需要创建的簇的数目,K-means算法中的k个簇的质心可以通过随机的方式获得,但是这些点需要位于数据范围内。在算法中,计算每个点到质心得距离,选择距离最小的质心对应的簇作为该数据点的划分,然后再基于该分配过程后更新簇的质心。重复上述过程,直至各个簇的质心不再变化为止。
- K-means算法虽然有效,但是容易受到初始簇质心的情况而影响,有可能陷入局部最优解。为了解决这个问题,可以使用另外一种称为二分K-means的聚类算法。二分K-means算法首先将所有数据点分为一个簇;然后使用K-means(k=2)对其进行划分;下一次迭代时,选择使得SSE下降程度最大的簇进行划分;重复该过程,直至簇的个数达到指定的数目为止。实验表明,二分K-means算法的聚类效果要好于普通的K-means聚类算法。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









