










【ML】KMeans 实践(基于sklearn)
原理
下面做原理简要介绍:
- KMeans是一个非监督学习算法,对于关键的K值即我们希望将样本分为几类,一般情况下可以根据经验划分(根据不同的领域,领域专家可以给出建议),或者多次尝试找最好的值(手肘法,参考下文连接)。
- 选择好K值后,再从样本中随机的选取K个点作为初始化中心点。
- 然后依次计算剩余点与每个初始化中心点的距离(距离有很多种,比如欧式距离、曼哈顿距离),将每个点划分到最近的初始化中心点的分类中。
- 将归类后的点重新计算质心作为新的中心点(根据计算距离方式不同可以有不同的计算方式,比如:计算所在分类所有点各个维度的平均值作为新的中心点,举例:有两个维度x,y, 经过一轮计算一个分类下有3个点,分别为:{(x1,y1),(x2,y2),(x3,y3)},则新的中心点为:( (x1+x2+x3)/3, (y1+y2+y3)/3 ))
- 回到第三步(直到中心点稳定,不变/或者新点的距离和旧点距离小于一个阈值,或者迭代达到最大次数,则结束)
(其他更详细的参考:https://zhuanlan.zhihu.com/p/184686598)
读取数据
import numpy as np
import pandas as pd
data = pd.read_csv('/kaggle/input/xclara/xclara.csv')
data.head()
输出:
| V1 | V2 | |
|---|---|---|
| 0 | 2.072345 | -3.241693 |
| 1 | 17.936710 | 15.784810 |
| 2 | 1.083576 | 7.319176 |
| 3 | 11.120670 | 14.406780 |
| 4 | 23.711550 | 2.557729 |
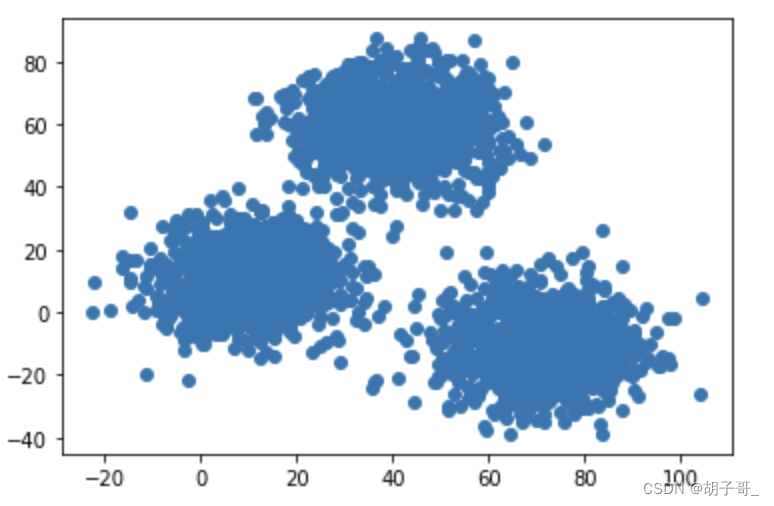
可视化数据(观察规律)
from matplotlib import pyplot as plt
V1 = data.loc[:,'V1']
V2 = data.loc[:,'V2']
plt.scatter(V1,V2)
训练
from sklearn.cluster import KMeans
KM = KMeans(n_clusters=3)
KM.fit(data)
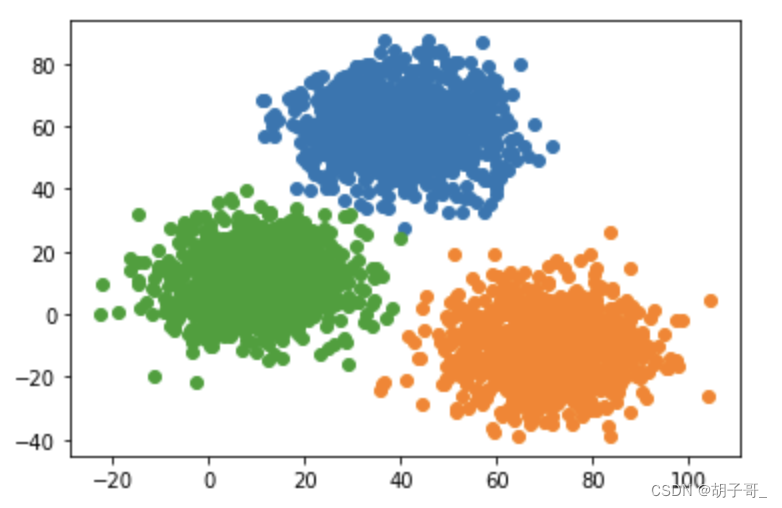
预测 + 可视化
predict = KM.predict(data)
plt.scatter(V1[predict==0],V2[predict==0])
plt.scatter(V1[predict==1],V2[predict==1])
plt.scatter(V1[predict==2],V2[predict==2])
plt.show()
















 629
629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









