






前言
理解GPT-4V,
成为GPT-4V,
超越GPT-4V。
这不是一个段子,而是大模型极客内心的涌动。
2023年是一个重要的年份。
是前进的一年,
是提速的一年,
大语言模型的历史意义,已属非凡。
但我今天想讲的,不止大语言模型。
有风掠过田野,图文模型迅猛成长,取得实质性进展。
模型就像机器人,
快要看懂世界了。
还取了花哨的英文名。
英文名后,应有“模型”二字,下文均做省略。
可以将图文模型的能力,上升为多模态模型的能力。
不过,多位受访专家均不建议使用多模态一词;
我采用建议,在文中统称,图文模型(或者视觉语言模型,Visual Language Model)模型。
我们正在通往原生多模态的路上,
图文模型是一个很好的开始,
这份盘点目录想尽力呈现一条科研人员苦思力索的探索之路。

第一集,2023全年时间线
1. 2021年1月,美国OpenAI 公司出道即巅峰推出CLIP;
2. 2022年1月,美国Salesforce公司出手得卢推出BLIP。
3. 2022年4月,美国谷歌公司DeepMind拱手而取Flamingo;
4. 2023年1月,美国BLIP系列的第二个模型问世
BLIP-2;
5. 2023年2月,美国微软公司出手KOSMOS-1,
6. 2023年5月,美国Salesforce公司两将出阵
InstructBLIP,BLIP-Diffusion,拉起年中高潮;
7. 2023年6月,美国微软公司再出大牌KOSMOS-2;
8. 2023年8月,国产派阿里巴巴一鸣惊人推出
Qwen-VL;
9. 2023年9月,美国OpenAI晴天霹雳推出
GPT-4Vision;
10. 2023年9月,国产派腾讯在图文模型上低调进展;
11. 2023年10月,美国UCSC推出MiniGPT-5;
12. 2023年10月,美国威斯康星大学,微软研究院和哥伦比亚大学研究人员三方合力推出LLaVA-1.5;
13. 2023年11月,国产派智谱AI团队及锋而试推出CogVLM;
14. 2023年11月,美国微软上兵伐谋推出Florence-2;
15. 2023年12 月, 美国谷歌将门有将推出Gemini;
第二集,CLIP出道即巅峰
故事开始,得从图文模型在搞什么讲起。
它的出发点很直接,人类世界的信息有图亦有文,模型也应该识图亦识字。
认识图文模型,一定要认识CLIP。

时至2024年元月,我们依然不得不谈2021年问世的CLIP。论文虽已“陈年”,但它仍有旺盛的生命力。
CLIP属于美国OpenAI团队。它在图文方向上进展颇大,凭借技术实力和无私开源,蜚声技术圈,一举奠定了领域基石。国内外很多研究团队都以CLIP为基础发展自己的技术创新点。
我在CLIP身上,看到的亮点是:图文对齐。
这就好比,两个价值观截然不同的人,非要他们俩的想法一致。
对齐之后,怎么用呢?
比如,想在图片上面找信息,想找什么就输入文字。
在学术论文里,这种“输入文字找图”的能力叫做“图文检索任务”。
所以,有人说图文模型,好比给大语言模型安装上了能看图的“眼睛”。
在没有CLIP的日子里,“图文检索任务”这个任务有点麻烦,需先加上标签。再把图片里的内容转化成文本标签(Tagging),才能检索。
多了一道工序不说,且标签体系需要提前定义好,后面对标签进行任何增删改都很麻烦。
CLIP把“以文搜文”的“招式”,发扬到“以文搜图”上,
训练数据是一对一对的“文本-图像”,“一张图”和“一段文本描述”。
也就是,用“图像-文本配对数据集”进行训练。
口头表述的时候,喜欢叫“图文Pair”。
视觉模型的能力在语言模型上焕发出来了。
诚然,谁让这个能力焕发,谁就立功了。
CLIP真香,在图像识别的时候融入了语言模型这一额外信息,可以有效地捕捉图像和文本之间的联系。
比如,它能够理解某张图片中的动物是一只狗,并且和描述这张图片中文字里的“狗”准确对应。
除了GPT-4和Gemini这种浑身上下都是秘密的模型之外,目前已知的大部分的图文模型,很多都以CLIP作为基础。
比如,后继者Flamingo和LLaVA直接使用CLIP作为图像编码器。
而DALL-E则用CLIP来筛选生成的图像,等等。
可以说,这类跟随者延续了图文对比学习训练的视觉特征的发展路线。
其实路线不止一条,另外一条路就是视觉表征学习的代表作品,何恺明的MAE。
谈到CLIP和MAE,中国科学院大学博士生陈志扬是这样总结的:
“在图文模型背景下讨论CLIP和MAE,我们讨论的是两种截然不同的提取视觉特征的方式。CLIP提取的视觉特征是经过图文两模态对比学习训练而得到的,目前被大部分研究团队所采用;而MAE是掩码图像恢复训练,进而提取视觉特征的路线,当前采用者较少。”
当然,那些令人羡慕的,有足够的算力的团队,可以不使用CLIP现有的参数,从头开始训练模型。
如果使用CLIP的开源模型参数,可以将其现有参数作为初始化参数来训练自己的模型。这可以帮助模型在后续训练中收敛更快、更稳定。
虽然快了一步,但是,对于使用中文的地区来说,这样做会有劣势。
因为CLIP的开源模型参数只针对英文训练得比较充分,它没有训练过其它类型的语言。
比如,一张截图里面有很多的中文的字。若使用CLIP做题,就会不及格。因为CLIP所使用的数据都是英文,它只擅长理解图中的英文。
乐观地讲,人工智能的江湖这么大,中文的问题,日后自然会有人来解决。
CLIP打下一个极好的基础,人们常常借CLIP的优势,提高自己的模型性能。
在这点上,没有必要过分强调从零开始才是自研,很多工作就是站在前人的基础上。
第三集,CLIP的法宝
既然这么强大,CLIP是什么结构呢?
我们先了解一下图文模型的基本结构,
通常由三个关键模块组成:
图像编码器、文本编码器和融合来自两个编码器信息的模块。
编码器和解码器往往配对使用,
编码器负责提取输入数据的特征,解码器负责根据这些特征生成输出数据。
再看CLIP的模型结构,相对简洁。
有两个主要的模型组件,一个负责图(Image encoder),一个负责文(Text encoder),一目了然。虽然CLIP有两个编码器,但它没有解码器。
一图一文理解能力Buff叠满,要不然怎么能说它理解能力强呢。
单独再补一笔,CLIP结构里负责图的那个编码器有多强。
它能单独拎出来用。
相当于,从大兵器上拆出个小兵器来用。
下一步,当然是想让图和文尽可能地对齐(或者说融合)。
用什么方法对齐呢?
答案:对比学习。
虽不是首创,但CLIP把对比学习玩得很明白。
是时候记住CLIP论文的中英文全称了:
一种基于对比的文本-图像对的预训练模型(Contrastive Vision-Language Pre-training,简称CLIP)。
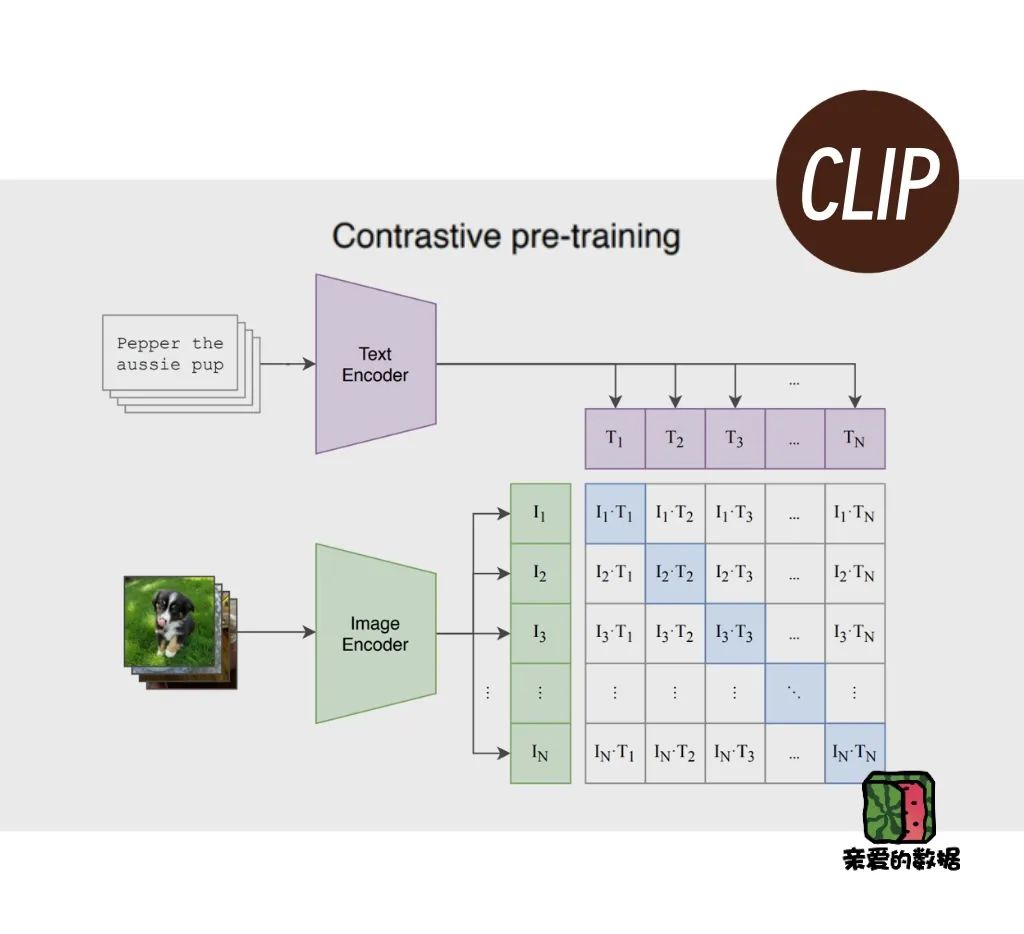
对比学习作为一种自监督学习方法,它通过将相似的样本映射到同一个空间,而将不相似的样本映射到不同的空间,来学习样本之间的关系。
简单回答就是一种找相似的思路。
正确的图片和文字组合尽可能地“相似”,而错误的组合尽可能地“不相似”,这也就有了相似度得分。CLIP的训练目标是最大化正确配对的相似度得分,同时最小化错误配对的相似度得分。
有了相似度,就不再追求精确。
这样事情的本质变成了,判断哪些文字更可能的与图片匹配。
以这种“找相似”方式把图像和文本的融合训练得很好,打开了新的天地。
有人拿CLIP直接当现成的组件来用,有人学习CLIP的方法,
美国Meta(原脸书)公司的Data2vec模型马上就把“对比学习”发扬光大了一把。
并且模态从图文,扩展到了图文音。
将图像、文本和语音编码成向量表示,然后将它们映射到同一个空间。
如果这三种模态数据是匹配的,则它们的向量表示应该足够接近。
可惜,后面不勇猛了。
对比学习是一种有效的多模态学习方法,它能够帮助模型学习不同模态数据之间的关系。Data2vec使用了CLIP提出的对比学习方法,是CLIP众多跟随者中的一位。
有专家观点是:
“CLIP最大的亮点就是它能够将不同模式、文本和图像的数据映射到共享向量空间。这种共享的多模态向量空间使文本到图像和图像到文本的任务变得更加容易。”
在跟随者眼中,CLIP是一个法宝。
惊喜更甚之处,把它的编码器单拎出来,又是一件法宝。
拿它不仅可以识别图像,还可以结合大语言模型,生成与图像相关的回答,甚至搜索与文字描述相符的图像。
这奠定了CLIP对于后世的意义:法宝型组件。
既现成,又好用。
写这篇的时候,突然间想起来2021年3月去杭州阿里巴巴达摩院找杨红霞,她推荐我仔细看看CLIP论文,并评价进展大,可惜那时没有引起足够重视。
而今看来,借用一个专业的点评:
“CLIP是一个不容低估的里程碑式的工作,能作为一个扎实好用的基础组件,翻开了多模态的新篇章。”
几年前,我看不出来CLIP高明,只能说明当时水平不行。
无法确定GPT-4V是否也使用了CLIP结构,我推测也许OpenAI有一个内部版的CLIP。
第四集,谷歌:出手就可圈可点
Salesforce是全球最著名的SaaS公司,谁知道它家搞起大模型毫不示弱。
早在2022年1月,他们团队就推出了BLIP模型。
无庸多言,用成果征服业界。
谁又能想到,后续好不落俗,惊艳连连,更是在2023年集萃成BLIP系列。
当BLIP上场,官网上的说法是世界上第一个开源多模态聊天机器人的多模态基础模型的可扩展预训练。
这句子长到让人都不会断句了。
业界评价:多模态启发性工作。
论文一作是来自Salesforce AI Research的李俊男博士。
再回顾2022年4月,也就是3个月后,谷歌DeepMind团队推出的Flamingo凭借其出色表现使得一些人将其视为多模式领域的GPT-3时刻。
2022年的年度节奏总体上温和,和2023年的强劲形成强烈反差。
Flamingo开创了一种新的算法思想,图文交错(Interleaved)。

如何理解图文交错呢?
比如说,我们上网浏览互联网,网页中的文字和图片交替出现。无论是给文字配图,还是图有相关文字解释。
如此说来,交替数据是“天然”数据,网页排版原本就是这样。世界上有海量网页,这类数据要用好,自然而然会发展出专门用好交替数据的技术。
阿里云通义实验室算法专家厚行(花名)博士这样介绍图文交错数据:
“这类数据来源于网页,按照网页阅读逻辑来排版。有了图文交错数据,我们可以将任意网页、海量书籍和PDF都当作训练预料。Flamingo对我们团队的启发是,由模型去自主学习数据中图片和文字关联的模式。”
图和文字可以强关联,也可以弱关联,文字和图片之间的距离甚至可以很远。比如,一篇文章的头图,可以是和文章结尾遥相呼应。学习过交替数据的模型,讲好比从头到尾的看完了网页。当Flamingo出现,意味着模型学习,从图文配对型的数据,推广到了图文交错型数据上。
武汉人工智能研究院算法架构师易东博士告诉我:
“(训练模型的数据)最好就是人类日常使用的自然数据。比如,爬了一段文字,文末有个视频,视频的位置保持原有状态,不要人为调整。因为模型需要学习人类是如何安排图文顺序和位置关系。”
就在早期的时候,训练大语言模型只需要纯文本数据。彼时,那些处理不了的多种类型的数据,比如,网页里可能会有图片、视频、音乐,那些数据会被删除,也是一种浪费。
谷歌Flamingo开创了用这种图文交错的数据来训练模型的里程碑,它的图像处理部分从头开始训练。同样使用对比学习,但训练数据量比CLIP用的多5倍,还多了一种新类型的数据,视频和文本配对数据。
我们常见的大语言模型使用了下一个词预测(Next token prediction)技术,但Flamingo 进行了创新,它同时考虑了文字和图片,预测的依据不仅包括文本,还加上了视觉信息。
为了更好地结合文字和图像,Flamingo引入了一些更高级的技术:Perceiver Resample。尔后,后辈之中有人推出了一个同类型的组件Q-Former。
这一把,虽然谷歌Perceiver Resample抢了头筹,不过日后Q-Former更出名。
话说回来,在图文交错的数据中摸索技巧十分必要。
阿里云通义实验室算法专家厚行对此也十分留意,他谈到了Flamingo所采用的技巧:
“在泛化性上,用精心筛选过的交错的图文对来进行模型训练,不如将图文对和网页图文交错数据混起来做训练的效果好。”
谷歌Flamingo使用图文交错的数据进行训练,可以帮助模型更好地理解图像和文本之间的关系,从而提高在少样本学习中的表现。
CLIP和Flamingo是两位先行者,
CLIP只能进行图像和文本检索和理解,而 Flamingo模型可以生成文本响应,多出来的能力是因为Flamingo在CLIP的基础上添加了一个语言模型。
虽然Flamingo并不开源,但喜欢它的人多,开源社区积极复现了Flamingo的开源版本,可见其受欢迎程度。
闭源无法拥有,开源天长地久。
CLIP,BLIP,Flamingo这一小波高潮,气拔山兮,为2023年打下了坚实基础。
写到这里可能会有人说,明明在聊2023年,为什么总在追忆往昔。
前者蓄够力,后者才猛进。
第五集,BLIP-2的葵花点穴手
在谷歌Flamingo之后,Salesforce家的BLIP又搞了第二轮大动作。
也就是BLIP系列中著名的第二个模型,2023年的1月,BLIP-2引爆了全场。
或者说打破了沉沉死气,图文模型的气氛一下热烈起来。
后续的动作更是说明BLIP-2开创了一代风气,
InstructBLIP,BLIP-Diffusion,X-InstructBLIP接连问世。
看来,BLIP系列很擅长自我突破。

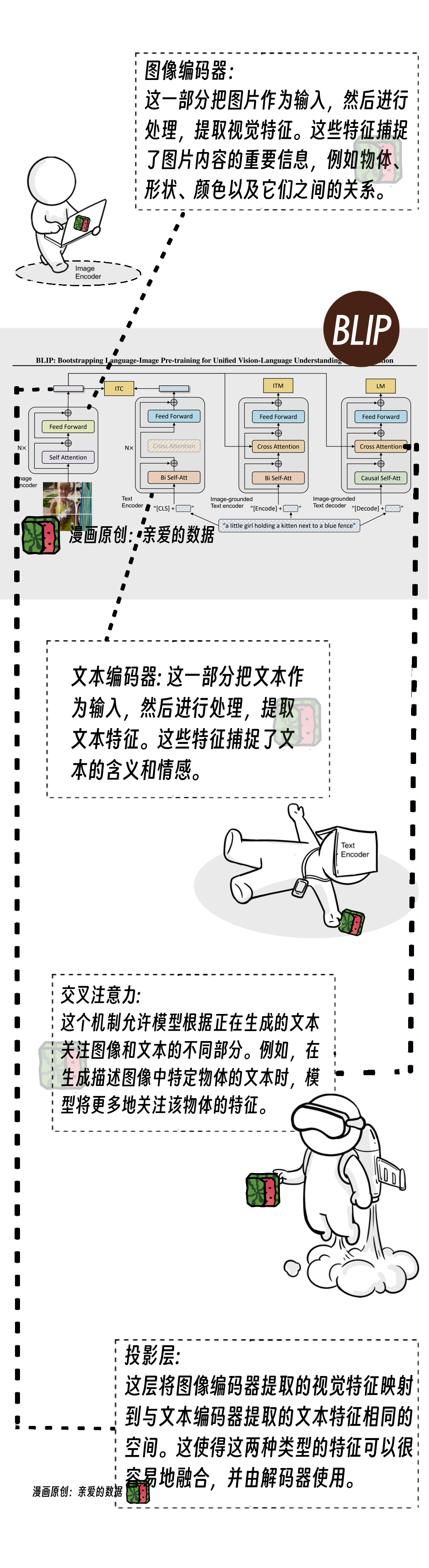
本质上讲,BLIP-2是对CLIP的“魔法”改进,也延续了部分BLIP第一版的算法思路。
好玩之处是,BLIP-2的这两个组件被冻结了。
冻结难道不是一个魔法功能吗?英文论文里的“咒语”居然就是“Frozen”。放在中国武林大会上,那就是葵花点穴手了。
一般来说,冻结是用于冻结训练好的网络模型参数,也就是参数保持不变。
有时候,“不变”比“变”好。
既然冻结是BLIP-2特色,那就把视觉编码器和语言模型都始终保持冻结。
冻结的原因之一可能是担心越训练,效果越倒退。
既然冻结了两个模块,这样整个结构中唯一可以训练的模块就显得尤其重要,名叫Q-Former。
这就是第三集里讲的图文模型的基本结构有三个关键模块,其中最后一块。
这个模块好比是一个“插座”,两个用电器的功率不能调整了,那就得调这个“插座”的用电功率了。
“插座”的思路,新一代图文对齐神器的思路。
有些算法团队内部管它叫做适配器(Adapter)。
厚行博士对此也高度赞扬:
“VIT可以用一个已经训练好的,LLM也可以用一个已经训练好的,只去搭建并训练中间的过渡层就可以了。适配器这个想法非常好,它就像插座,想把一个视觉模型插在语言模型上。”
Q-Former看名字就像是一个Transformer的“亲戚”,答案的确是。
“插座”内部:有一个旧设计,一个新设计。
旧设计是Q-Former有三个损失函数,这一做法是延续了第一版BLIP的做法。
新设计是Q-Former由两个子模块组成,精巧之处在于,这两个子模块共享相同的自注意力层。
看来BLIP-2作者们真的是苦思力索,若被评为“年中风流人物”,也实至名归。
武汉人工智能研究院,王金桥院长对此的评价也是:
“已是主流”。
插座思想,虽然BLIP-2不是首创,但是它的“插座”Q-Former超级好用。
首创是Flamingo里提出的“Perceiver Resampler”。
好想法同期出现。
对于Q-Former的学术价值和工程意义,武汉人工智能研究院算法架构师易东博士称赞道:
“基于视觉特征和语言特征的图文对齐模型是一种方法,Perceiver Resampler和Q-Former都是杰出代表。它们都采用了多注意力机制来融合图像和文本的特征。Perceiver Resampler使用了感知器(Perceiver)模型,能够有效地学习图像和文本的多尺度特征。Q-Former使用了动态注意力机制,能够根据图像和文本的不同语义关系,灵活地调整注意力权重。”
学术观点就是要多角度思考,激荡新思。
对于Q-Former,阿里云通义实验室算法专家厚行也给了我另外一种视角。他认为:
“BLIP-2它之所以成功,并不是它有Q-Former。Q-Former的作用被夸大了。个人认为带来最强增益的这个能力组件并不是Q-Former,而是跟LLM联动得很好,采用了一个很强的LLM作为它的一个基础;以及采用了一个比较合适的训练范式。我们团队发现Q-Former的网络结构是什么并不重要,甚至把Q-Former替换成一个很简单的网络结构,很多或者其他网络结构,都能有效(work)。而不需要设计一个复杂的损失函数,采用Next token prediction自回归的损失函数就行。”
有一些博士朋友告诉我,他们经常把BLIP-2这篇论文拿出来翻看 ,可见这篇论文在这一时期的重要性。
另有一位博士朋友的观点也比较有意思,
他发现BLIP-2有一个很神奇的地方:
“它的数据里面是没有任何VQA数据。但是,它却能在训练完之后,有很好的零样本学习VQA能力。首先,它所有用的数据都是图文对,都是图文对类型的数据。训练完成后,对它用人类自然语言提问,它就能给你回答。这个能力是冻结的大语言模型所带来的。”
厚行博士强调:
“重点在于,它成功地把视觉这个表征过渡到了大语言模型上面。大语言模型就把视觉表征当成了一个它可理解的东西,能够以自然语言去回答问题。”
另外,Q-Former还有一个骨灰级棘手的难点值得注意,请准备好扶额叹气。
Q-Former有三个损失函数,专业级小伙伴对这三个家伙的名字耳熟能详脱口而出,而谭老师我,就不在这里献丑了。
武汉人工智能研究院算法架构师易东博士对此的解读是:
“一般来说,一个模型最终对应一个目标(函数)。作者的算法思想是在一个损失函数(来自CLIP)的基础上,加了两个损失函数。这样等于BLIP有三个损失函数。也可能是因为不清楚那种形式最好,所以用了多个目标函数。目标函数用于评估图文两个模型组件的输出是否对齐了。”
易东博士停顿了一下,继续谈道:
“难点在于,这三个损失函数联合起来一起训练,会导致程序设计上的难度加大。一会冻结这个,一会冻结那个。”
世事不难我辈何用,对齐是BLIP系列贯穿始终的一大特色。BLIP-2在2023年中这个时期,独出机杼,潇洒风流了一把。
第六集:BLIP系列,众擎易举
2023年上半年,很多工作都在做同一件事,把算法大结构中的语言模型部分,换成大模型,性能普遍都会有提升。
BLIP-2把整个结构中的小语言模型(Bert)换成了一个大语言模型,这是很自然的进展。
小模型换成大模型之后,它在文本这一侧的性能比之前要好,图像侧没有变。
所以,只能说它整体模型性能略有增强。
好消息是,BLIP这个系列并没有止步不前,很快迎来了第三个,第四个兄弟。
BLIP若是走在大马路上,都能散发出一种昂扬的气质。
5月份是BLIP系列最发力的月份。
一口气发了两个模型,Instruct-BLIP(5月11日发布)和BLIP-Diffusion(5月24日发布)。
我估计很有可能Salesforce公司内部是同步开展的两个项目,一个做图文理解,一个做图片生成。
Instruct-BLIP作为这个系列中的第三篇,将GPT系列里的指令微调这个训练方法,引入到图文模型中,模型有了指令理解能力,这样就可以用来做图文问答。
给一张图,再给一个问题。
比如,给美景赋诗一首。
给一张“和女友海边沙滩浪漫约会”的照片,
此时此景,学疏才浅的你并不能为照片吟诗作赋一首,
那就把任务交给InstructBLIP吧。
对于InstructBLIP来说,BLIP-2是现成的基础模型,指令微调也是大语言模型已有的方法。
表面看上,这几件“顺便拿过来”的工作,但是人家搞了个应用,搞了一个视觉问答的应用。
而且,之前在图文问答里,没有人这么做过。
易东博士认为:
“可以直观地理解,BLIP-2是把图像翻译成了文本。在此之后,再来一个纯文本的问答。”
BLIP-Diffusion从名字上就能看出来是基础模型接上Stable Diffusion模型。
如此这般,当你输入是图片和文字,输出的可以是一张图片。
InstructBLIP没有改图能力,而BLIP-Diffusion有。
BLIP-Diffusion编辑图片,相当于实现零样本学习的DreamBooth算法。
怎么理解呢?
一般来说,DreamBooth没有那么易用,需要训练。
假如想对图片中的一个主体(假设是橘猫)进行编辑的话,比如,更换风格属性(比如,水墨风格,油画质感等属性)。
我们的任务是更换图片中的某个主体(橘猫),就需要橘猫的多张图片,训练之后,才能保持住图片里的橘猫。
再玩一些花样,比如,给橘猫换衣服。换的是衣服,不能把橘猫换成布偶猫。
方便之处在于,用一段话描述想如何修改,模型会按照指令去修改那张图片,生成一张新的图片。
BLIP-Diffusion,无需训练,有零样本(Zero Short)学习能力。
要我说,BLIP-Diffusion还是把图看懂了,知道怎么改图了,不是把图里的橘猫扣下这个玩法。
虽然易用性上去了,但是有专家告诉我:
“BLIP-Diffusion这个模型,把整个Stable Diffusion接到了InstructBLIP的后端,并且,接得不是很好。”
为什么?
因为InstructBLIP的结构里面,原本就有一个大语言模型组件,
而Stable Diffusion也有一个文本编码器(Text encode)。
InstructBLIP没有把这两个合并,或者做更细腻得处理,而是生硬地把这两个组件给接起来了。等于有两个重复的组件用来做同一件事。
诚然,Stable Diffusion如何“完美接入”本就是一个挑战,Instruct BLIP给后人留下了改进的空间。
同一系列,前后工作,拾阶而上,耳目一新。
BLIP-2很强,BLIP系列如此的优秀,众擎易举,推动图文对齐的方法向上一步。
CLIP,BLIP,GLIP这种名字以字母P(“预训练”的英文Pretraining)结尾,一不小心押韵。
有了GLIP的时候,模型能还做定位(Grounding)任务,也就是输出一个框子;
对图片中的物体定位的时候,先预测到比如图片中狗的位置,再把图像中的狗框起来。
精彩如此纷呈,而年度进度条只走了大约一半。
第七集,微软出手,中国队也出手
2023年下半年,Kosmos-2是个不能错过的亮点。
微软连招一出,东临碣石以观沧海的感觉有了。
此一招,Kosmos-2,超过了BLIP-2。

彼一招,和两所美国两所高校的研究人员合作,推出了LLaVA-1.5。

比较起来,BLIP系列只做了图像一个模态,而Kosmos不限于图文两个模态了。
显然,Kosmos的目标是往多模态那个方向前进。
因为Kosmos一开始并没有开源(2023年2月),所以追随者少。
但是,有了Kosmos-2,Kosmos-2.5,Kosmos-G,人气高涨起来。
一方面,Kosmos-2,解锁了视觉定位能力,将视觉语言模型结合了定位任务,比如,你问图中的橘猫在哪?
模型能拿一个框子把橘猫框出来。
或者反过来,画了一个框,模型告诉我,框子里面是一只橘猫,
两种方式都可以。
另外,还附送一款新颖的数据集(Grounded)。
此前,Stable Diffusion跟大语言模型的配合像是隔着一条马里亚纳海沟,呼唤一种“完全无缝”的方式连起来,这成了一个待解决的难点。
Kosmos-G看上去像一位填沟高手,提出一种可行的方法。

想让Stable Diffusion的生成能力和大语言模型对接的人还是很多的,Kosmos实现得很好,对接方式是适配器。
武汉人工智能研究院算法架构师易东博士这样称赞道:
“适配过程比较简单,Stable Diffusion有一个文本编码器可以提取特征。而大语言模型也能提取特征,直接用这个大语言模型的输出去逼近Stable Diffusion的文本编码器,再把大语言模型的输出跟Stable Diffusion的输入的两种特征对齐,让它们两个尽量地接近,这样就连起来了。”
“目前没有完美”,易东博士笑笑,他停顿了一下,接着说道:“现阶段好像也只能这么干,而且效果挺好”。
“关键是论文里代价比较小。Stable Diffusion看作一个插件,可以不动,把前面的给它对上。这样,Kosmos的训练步骤更简单了。”
我继续问易东博士:
“你认为Kosmos的优点在哪?”
他告诉我:
“算法结构简洁,我们拿BLIP做个比较,BLIP有三个损失函数,联合训练难度较高。Kosmos直接用一个生成模型实现文本和图像两类信息对齐。”
他又补充了一句:“不过,Kosmos对训练数据的要求很高,需要交替数据。”
Kosmos的算法思想令模型结构简洁,直接在GPT的基础上,把负责多模态的“关键组件”加入进去,直接学习用人类世界已有的一大类信息源的一些特征,理解“图文并茂”。
比如,Kosmos的必备学习词表(也就是词典),也和纯文本训练出来的语言模型有所不同,每个部分分别对应于文本,图片,视频,音乐。
交替模态的数据集,其信息之间的关系也交织。
输入部分采用交替数据,它可以很自然地按照GPT的方式训练,也就是通过将不同模态转换为词元(Token)的特征向量,也就是在特征层面对齐。
有专家认为,输出的部分,也就是负责生成的部分,还是没法以一个很自然的方式处理。
目前只能还是分两阶段处理。
在第一阶段用负责理解的模型,先把交替数据的搞定。
Kosmos 有一系列的工作,比如,Kosmos-G这个模型,输入是人工指定的,输出的话,它有一个额外的东西要决定在这个地方该输出什么。
好事接连发生,MiniGPT-5的论文比Kosmos-G的文章也晚不了几天。
我暗自推想,有可能Kosmos-G(10月4日)发布了,逼着MiniGPT-5立马亮牌。
只要竞争一进入白热化,类似的思想都在研究人员的头脑中狂奔。
那些相对同期的进展,可能看到别人发了,赶紧把自己的也拿出来。
这种情况下,发布顺序不是那么重要,而是扎实的工作更重要。
只不过,这些隐秘之处的竞争,很难被观察到。
MiniGPT-5的输出是图文交错的形式,这个改进让模型不仅用文字回答了问题,还可以配图。相当于,把问题的意图给揉进去,有了意图,就相当于多了一个层信息:
知道啥时候该输出文本,啥时候输出该配上图。
同时,MiniGPT-5引入了一个叫Voken的新玩意。
论文上说:“为了解决跨模型域的差异,我们引入了生成性词元(Generative Vokens),它们就像是一座桥梁,连接了语言和视觉世界,让大语言模型能够理解和处理图像信息。”
一般来说,文本的词元都叫Token;
如果模型生成的是Token,就输出文本。如果它生成的是Voken,就输出视觉信息。
Voken就是特殊的Token。
好事连三,同期还有一篇同行论文也让人有目共赏。
商汤的定位任务论文Shikra。
Kosmos-2和Shikra各有千秋,甚至Shikra还更厉害一些
一位专家级研究员朋友甚至告诉我:“Shikra对他的启发比Kosmos-2还大,探索了到底这个定位任务中定位出的哪个位置,到底怎么去表示。”
厚行博士是这样给我解释商汤这篇论文的贡献的:
商汤团队用文本表示这个定位的位置。比如,把这个图上的左上角认为是(0,0),图上的右下角(1000,1000),图上的任意一个点都可以表示成0到1000的一个数组。也就是说一个点的坐标不仅仅可以用特殊词元(Special token)来去表示,而且也可以用纯文本来表示。
Shikra的方法和Kosmos-2的训练集对阿里巴巴Qwen-VL都有启发。
看来,是时候找商汤研究员来聊聊Shikra了,谭老师我说干就干。我向商汤研究员提出的第一个问题是:“Shikra 的灵感怎么来的?”
商汤业务经常面对的复杂视觉场景理解任务,这类任务已经有不错的图像理解能力,但是,这和人们沟通交互的方式仍有差距,其中最大的差别在于“用手指向”的能力,即指示(Referring,对于提问者)和定位(Grounding,对于回答者)的能力。因此,我们这项工作就希望能把指示(Referring)和 定位(Grounding )的能力引入,而且是以最简洁的方式。
我们发现,过去主要的一些引入定位能力的工作要么需要额外增加特殊词典,要么需要引入坐标编码器,或者一些其他更加定制化的设计,这些设计均在一定程度上破坏了大语言模型的统一性和简洁性。
因此,从指示和定位的表达方式上来考虑。
一般而言,大家都是通过点、框的方式来表示感兴趣的目标、区域,这些点或者框会通过数字坐标来表示,而数字坐标在书写过程中天然就是文本形态的字符,这些字符已经存在于任何一个大语言模型的词典中了,为什么不可以让大语言模型直接用文本的方式直接输出坐标呢?这样的话,完全不需要对现有的词典做任何改动,也不需要引入其他任何多余的定制模块。
当时的想法非常简单直接,实验下来也确实有效(work)。当然我们也与另外一种比较主流的做法,即引入额外词典来表示位置坐标的方法,进行了简单对比,实验表明,我们的设计既简单也更有效。
可以说,简单、直接,是Shikra设计的最大优点。

第二个问题是:“听说Shikra应用范围很广?”
“Shikra提出的定位训练方式成为业界多模态大模型标准化做法之一,后续被阿里的Qwen-VL、苹果的Ferret、IDEA的Ziya-VL、微软LLaVA-1.5,智谱CogVLM等多模态大模型参考采纳;启发自动驾驶,遥感,操作系统,3D理解,数据生成等领域的多项研究;据业界反馈,也被应用到广告解析,智能裁剪,辅助标注等真实落地场景中。”
第八集,王者GPT-4的预告
无需多言,年度多模态的王者是GPT-4V(ision)。
王者GPT-4来了,带着它的商业机密和技术机密来了。
GPT-4没有论文,那些OpenAI官网上的介绍,只言片语间,被公认为是GPT-4V(ision)的预告。
九个月后,OpenAI实现了GPT-4当初图文进展部分的预告。也有人认为,人家OpenAI只是把早都做好的模型(GPT-4V)释放出来了而已。

很多人都吐槽论文没有干货,更像是秀肌肉。
江湖有传言(部分来自美国社交软件),GPT-4就是MOE,所以GPT-4V也是。
第九集,国产派的阿里巴巴通义千问
第二集的遗留问题,在第九集由阿里巴巴通义千问(Qwen-VL)出手了。
这个在8月份开源的模型,社区反馈很好,不少开发者向我推荐,并对其赞不绝口。
实际上,在这个炎热的8月份,阿里云通义千问团队进行了两次开源,
一次是7B参数规模的语言模型;另一次是参数规模是9B的视觉语言模型(VL)。
语言模型更受人关注,掩盖了一部分视觉语言模型的光芒。
很多光芒,都需要时间才能被看到。
Qwen-VL的中文理解能力,尤其对于图片里面中文的理解公认比较好。
在这个良好的基础上,他们的工作没有停止,仅仅在4个月后就推出了Qwen-Plus。
这时,有人称赞为:“这是在中文世界当中是唯一能去跟GPT-4V和Gemini掰手腕的一个模型。”
还是小声说一句,Qwen-Plus发布在12月(目前只开放了API),在时间上有后发优势。
从测试效果上来看,Qwen-VL-Plus最终在DocVQA评测数据集上已经超越了GPT-4V和Gemini-Ultra,达到全球SOTA(91.4%)。
2024年1月,Qwen-VL-Max发布,令人惊艳的是这个模型的表现,在多个评测数据集上和GPT-4V有来有回。
阿里云通义实验室算法专家厚行博士告诉我:
“团队在看到2023年3月14日的GPT-4释放出网页文章上看到,视觉部分的指标很猛。”
即使直至今日,世界上绝大多数的团队跟GPT-4这版的视觉指标有比较大的差距。
8月份,Qwen-VL(参数规模9B)发布,虽然已经比当时很多模型的指标要好很多了,团队对指标上的差距心知肚明。
他们在心里暗下了决心。
厚行博士对2023年OpenAI释放GPT-4成绩单的时刻记忆犹新,他谈到:
“最令我们震撼的就是DocVQA评测数据集,它用这个Pixel only的方式,也就是只读原始图像的方式,就能达到88.4分。而之前达到这一个水平的模型,全部经过了OCR Pipeline的方式,才能够达到这个水平。”
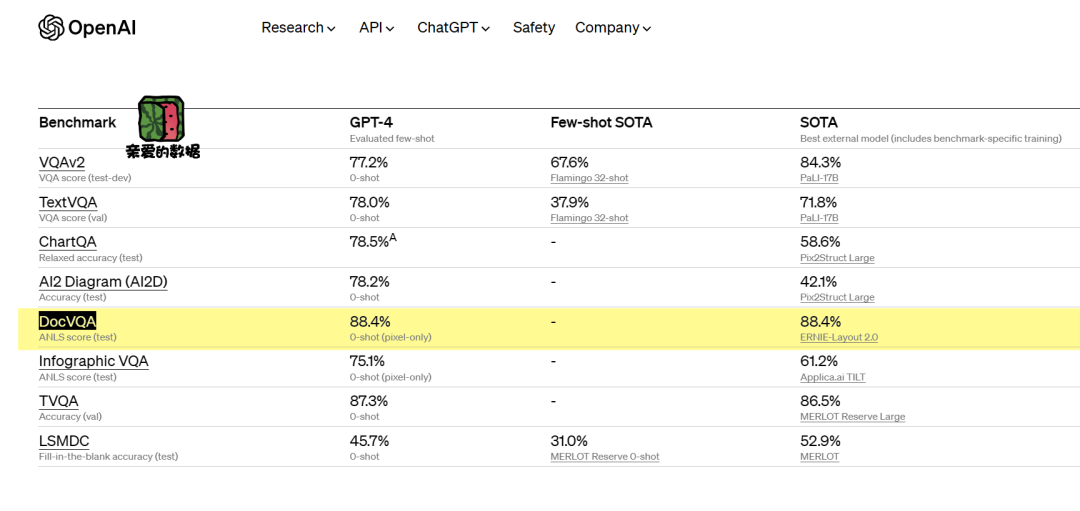
这个叫做DocVQA的评测数据集,引发了阿里团队的深思。
它到底代表什么呢?
Pixel only的中文直译就是仅仅输入图片像素。
做法就是直接输入图像,而不用对图像预先做一堆预处理工作。比如,先经过一个OCR工具(Pipeline)。
像素的背后,是分辨率,也是视觉模型眼睛的“视力”。
我们可以认为,Pixel only技术的实现,代表着这个模型一定是一个高分辨率模型。
如果这个模型的分辨率有所受限,对模型的输入来说,模型看到的永远是一个模糊的图片。但是,如果这个模型支持高清分辨率,带动很多其他模型效果指标都会提升。
厚行博士谈到:
“当时GPT-4V放出来的时候,我们知道它一定是一个高分辨率的模型,只是惊讶于这个指标居然能够做到88.4%。”
而GPT-4的方法有何不同?
答案是,GPT-4相当于端到端的就完成这件事情,而其他人还得嫁接一大堆工具,才能达到相同的效果。我用两条对于Qwen-VL的直白评价来结束这一集。
中国科学院大学博士生陈志扬的评价是:
“他们团队有的放矢地选择各类数据,十分清楚训练目标,知道要解决什么问题,并发力提高指标。”
武汉人工智能研究院研究员朱优松博士评价为:
“Qwen-VL(参数规模9B)在每个层次,每一个颗粒度的能力评级上,都非常强;各方面的数据,各个VAQ的数据都训练了,箭无虚发。模型的能力栈全面而丰富,可见准备得非常充分。因此,他们有这个胆量全部放出来,最终版的模型,最终版的参数,以及推理代码;在图文模型对中文的理解上,一马当先,中文第一,当之无愧。”
第十集,10月的LLaVA-1.5
锐进冲腾的10月,LLaVA-1.5扬鞭上场了。
此前LLaVA还有一版,但是直到LLaVA-1.5问世,这个系列的威力才真正显示出来。
从冲刺顶尖(SOTA)的角度,LLaVA-1.5可谓意气风发。
这么说吧,有专家认为,LLaVA-1.5的问世之前,按照往年的加速度推算,BLIP系列的优势很可能保持到年底。
现实很残酷,模型航瀚海。
LLaVA-1.5让BLIP系列中的一些“老资格”的模型彻底进了算法的历史档案馆。
开发者惊呼,LLaVA-1.5模型的性能比BLIP同期模型强太多了。
以前,这种过肩超越通常需要至少半年,甚至更长时间。
2023年不同于以往。
此时,距离InstructBLIP的问世时间(2023年6月)只有4个月。
后来者,竟如此居上。
站在那个时间点上,还是要说一句:“敬佩”。
不过,高兴一阵就可以了,因为反超随时可能发生。
两厢比较,BLIP-2结构笨重,LLaVA-1.5结构简洁。
LLaVA-1.5如何图文对齐?
其一,假如仅仅更新插座(Q-former)的算法思想,会陷入这样一个困局:允许变化的参数太少,学习能力受限。而LLaVA-1.5中大语言模型的参数可以微调,容量大,能力强。
其二,LLaVA-1.5用多层感知机(MLP)对齐,把Q-former的很笨重的结构换掉了。LLaVA-1.5的性能超过了只训练Q-former的BLIP-2。
其三,本质上,LLaVA-1.5扩展了边界。于是,我们可从其他模态中获得更大的信息量以增强文本这个模态的表现。
把其他模态的信息对齐到语言上,其能力也可以“出现”在其他模态上,比如声纳,雷达信号。
这样看上去,好玩的东西又多了。
2023年,我们站在一棵根基牢固的大树下,有很多低垂的果实可以摘。
细看LLaVA-1.5,它把视觉特征作为LLM的输入。
也就是说,LLaVA-1.5输入的是图,出来的是图片描述(也就是文字),本质上让大模型来做对齐,视觉编码器和文本描述对齐了。
那么,LLaVA-1.5由几个大的功能模块组成?
由三个大模块组成。
第一块,视觉编码器。
LLaVA-1.5的视觉编码器和CLIP有很大的关系,LLaVA-1.5是如何使用CLIP的呢?
我们都知道,CLIP的视觉编码器是VIT,而VIT是比较常用的视觉编码器。
LLaVA-1.5只取用了预训练好的CLIP里面视觉编码器部分的VIT(其中的一个版本ViT/336px)。
我们能清楚地看到,CLIP已经非常模块化了,能把里面的组件“拆到”别的地方用,越是能被这样用,越有资格被称为基础模型。
LLaVA-1.5也在拆CLIP的组件为自己所用。
由此可见,OpenAI公司发布的模型,被其他研究团队拿着放大镜看,看上了哪部分,就用上。
第二块,映射矩阵。
用MLP来解决把视觉的特征表达映射到语言的特征表达里面去这件事。
第三块,大语言模型。
他们选用美国伯克利大学团队一个知名组的现成语言模型Vicuna V1.5(参数规模13B)。大语言模型起到推理的作用,因为大语言模型是训练好的,希望用它把数据中最贴切的规律找到(拟合)出来。
说白了,大语言模型没有见过图片,所以不认识。
LLaVA-1.5就让大语言模型先认识图片,再根据从图片上认出的内容,回答问题。
如此以来,问答和图片上的内容更加匹配,从而得到更合适的答案。
这也是一种解决图片和文本两种类型信息(跨模态)对齐的方法。
LLaVA-1.5只有一个损失函数,而BLIP有三个损失函数。
BLIP冻结大语言模型。
而LLaVA-1.5冻结视觉模块,但是对语言模型进行了指令微调,因为调参范围受限,所以Q-Former参数容量太小了。
这里需要回顾一下旧知识点,谷歌DeepMind团队的Flamingo那篇论文里,曾对比过MLP和Q-Former的结构。
事实是Q-Former效果更好。
LLaVA -1.5没有用Q-Former,而是用简单结构做出了更好的效果,这说明仍然有很多技巧值得探索,且很重要。
这些技巧有可能像珍珠一样散落于数据,图像分辨率等等细节之处。
10月还有一个同期工作,也值得注意,但是Adept.ai团队(Transformer 论文作者)只给出了技术博客,没找到论文。
朱优松博士的评价是:“Fuyu-8B应该是第一个没有使用视觉编码器的图文大模型,进一步简化了模型结构,但猜测应该需要大量的计算进行预训练。”

2023年有目共睹,几乎所有参与者都在殚智竭力揣摩训练技巧,思考模型结构,希望出神入化地用于修炼技法中。
哪怕花落山枯,也想较量出个新的世界。
第十一集,国产派腾讯
在图文理解路线上,腾讯有算法,也有数据方面的自研工作,包括但不限于以下工作。
其一,腾讯AI Lab的TEXTBIND。
这篇工作提出了TEXTBIND框架,旨在让大语言模型能够理解和执行人类给出的多轮交替式多模态指令。例如,一边看图片一边接受文字指令,并用文字或图片做出回应。论文关注的是图文模型训练过程中的数据质量,强调图文混排的多轮对话数据能训练更好的图文模型。不过,受现有数据条件的限制,图文混排数据是用GPT-4生成,这篇工作的主要贡献了一套图文对数据,提出一套用图文对生成多轮对话的数据流程。
其二,腾讯优图实验室提出多任务统一方向的工作。
他们将视觉开放词汇目标检测、开放词汇分割、图文视觉定位(Visual Grounding)多个任务统一到一个模型上。比如,Open-vocabulary任务,给出一个名词,不管这个名词属于什么类别的物品,模型都能从图片中找出来。
在具体找出来的方式上,以检测任务的形式去找,或以分割任务的形式去找,都可以做到。该工作相比微软的Florence-2,它更多偏向系统实现,模型结构上的变化是加入特定的解码器(Head)来做预测。
第十二集,国产派智谱AI的CogVLM
先说一个冷知识,大部分的大模型图文模型的图和文的结构比例是一比十。
简单说,视觉模型部分占1份,语言模型部分占10份。
从图和文的结构比例上讲,CogVLM-17B很有冲击力,他们将比例大胆地调整成了一比一。
观察CogVLM-17B,起初是常规操作,用视觉编码器提取视觉特征,用VIT先把图理解了,提取出了图像特征,后面接了较为轻便的适配器(MLP)。
惊艳之处,马上来了。
智谱AI团队在原来的语言模型基础上发展出了一个分支,相当于专门设计了一个额外的分支。他们团队管这个分支叫做“专家”。
也就是说,他们对语言模型进行了大改动。
思路是,语言模型分成两个部分。语言模型这部分专门负责文本,而分支那部分专门负责文本和视觉信息的融合。
语言模型有了分身(且结构一样),干活更利索了。
相当于把这个分支单独拎出来,负责和这个视觉编码器理解出来的特征,再做一个深层次地融合交流。也可以理解为,他们做了一个图文对齐的新型功能组件,用这个组件进一步对齐融合。
在工作过程中,有一份的文本模型,就有一份的图像模型。
这也是前面图文结构一比一的由来。
所以,模型规模比较大。
我个人推测,智谱团队的出发点有可能是观察之前的视觉模型规模太小,在和语言模型进行图文对齐的时候,限制了语言模型能力的发挥。好比语言模型派了100个人,视觉模型派了10个人。你众我寡,视觉团队接不住语言模型派的活。
值得一提的是,早在2023年5月,智谱AI和清华KEG开源了VisualGLM-6B,智谱AI团队有可能在这个基础把视觉模型部分的规模放大了。
这点可没有和研发团队确认,仅为我个人理解。
第十三集,国产派紫东太初
看到未来,就有未来。
11月份,紫东太初团队论文中提出,现阶段的图片描述(Caption)偏宏观性描述。虽然有一些VQA任务也涉及到细致的颗粒度,但是总体来说,图像数据没有深入到属性细颗粒度(颜色,质地,具体的位置,事物关系)。
提高理解的细颗粒度,专业人士有目共睹,关键在于怎么做,以及究竟细致到什么程度?
颗粒度过粗的话,模型只能停留在大致理解图像的水平,缺乏对图像的精细理解,导致局部或者细节理解不到位。
所以,模型会胡说八道,也会产生和图像不符合的文本输出(幻觉)。
解决对图的理解不到位的方法之一,就是对齐的层次就要从大到小,越来越细。
核心还是对齐,先对齐大层次,再对齐小细节。
有关这类问题的例子有很多:
比如,图片中有女明星,女明星是不是杨幂。
再比如,模型认识会议室,换成室内电影院就不认识了。
比如,描述一场会议的图,一群人在开会,参会人员的男女性别数量等细节信息模型说不清。
如何引导模型学习细颗粒度?
构建新型(细颗粒度)数据集,包括,图片上物体之间的关系,动作关系(骑车,坐车),空间关系(桌子椅子),图片中的物体细节。
不希望大幅改动图文模型的结构,加一个组件来引导现有模型能够理解更细节图像内容。对图片进行分割标注,精细分割出来重点内容并和文本对应,希望模型学习到分割标注上的知识量。强化细节理解能力,减少在细节上出错。
在未来研究方向上,朱优松博士谈道:
未来还会往更细节(粒度)方向发展,把图文理解力的准确性不断拔高。比如,模型能在图片中找到不太好找的东西。“不太好找”是这项技术的关键所在,也是容易出错之处。

另一篇论文,是紫东太初第一个工业质检图文模态论文,于2023年9月份公布,12月中学术顶会AAAI,论文成果同期应用于某工厂工业质检过程之中。
工业质检自动化的痛点长期存在,老办法是人为根据经验设定异常参数,但经验并不总是够用。
比如,工业质检的产品缺陷是随机的,凹陷,裂缝,标签印刷,而且,有些缺陷数据拍摄不到,或者有些是新上生产线的工业产品,连一张缺陷图片都没有。历史数据的积累为零。假如仅依靠老办法喂缺陷数据,只能找到同类缺陷。
痛点是老痛点,以前的做法受限于用分类和分割任务的方法,大模型是新思路,让大模型彻底理解产品有缺陷这件事,
这篇论文的算法结构是,两个编码器,一个负责文本,一个负责图像。
两个解码器,分别是图文解码器和图图解码器。
在两个解码器的后面,以适配器来接大语言模型。
猛一看,有些笨重,细看才能看出设计合理之处。
武汉人工智能研究院副研究员朱炳科博士告诉我:
“首先,模型用正常工业产品图片(样本)来训练。也就是让大模型认识工业产品。
而检测产品图片的时候,图片就有可能正常,也有可能异常,这是客观情况。
于是,将鱼龙混杂的产品图片输入给模型。
此时,模型中的图文解码器和图图解码器再来提取细节特征。
也就是说,模型在这个阶段就能区分正常和异常两种情况。模型学到的特征既有图文比对的特征,也有图图比对的特征。
大模型的想法很简单,我知道正常产品是什么样,只要来图和正常产品不一样,那就是异常产品图片。
下一步,再把两种特征都输入适配器中,再以适配器接入到大语言模型里。
此时,大语言模型能用对话(语言能力)向生产工人,描述产品异常的大致情况,比如,产品外观有裂痕。
这个过程中特别之处在于,图文解码除了输出特征外,还另外会对输入的图片打分,并输出分数,此处用分数来表示异常,分数比文字更直观。
工业异常检测若只用视觉编码器提取的特征,特征会非常粗糙,我们需要用一个图文解码器增强定位能力(对区域像素的异常情况打分),适配器再综合所有信息,提供给大语言模型(适配器是CNN结构,更能关注到视觉信息中的细节)。
模型对图像的理解深入细节,是很多场景都迸涌出很强的需求。万马奔腾的工厂生产线,需要这些能处理细节的技术来帮助生产。
第十四集,微软Florence-2
在2023年前11个月扎实进展的基础上,微软年底的论文凶猛势头丝毫不减。
微软云Azure AI研究团队提出的视觉基础模型Florence-2,剑指目标识别,底气十足。
研究人员用统一的架构处理各种视觉任务,甚至想用图文对话模型一举把目标识别等传统计算视觉任务全面兼并。
当你对视觉解码器有一个较为深刻的理解,才会认同这个想法:
视觉解码器当年存在大模型结构之中,也曾是一种妥协路线。
长年来,视觉任务分而治之,被统一掉是大势所趋。
有了统一,视觉解码器的结构自然也会随之消失。
学术上的这一天,终于来了。
我相信这个想法不止一支研究团队想到了,我也相信很多研究团队在这个方向上铩羽而归。因为实现难度非常之大,所以,当看见这个方向被突破的时候,不免内心感叹。
看见这些进展真心高兴。
他们的算法思路优秀在哪里呢?
首先,算法结构上,当这个目标被大语言模型解决了,视觉解码器也就不复存在了。
在定位方面,用大语言模型(自回归监督学习的预测方式)预测下一个坐标,先找类型(从标签上学习),再找位置(预测坐标)。比如,先认出这是一个纸盒子,然后再依次预测一个盒子的四个点。
商汤也在这个方向上也有所探索,就是前文提到的用文本(数组)来表示坐标,想当于找到了统一输出的“形式”。
Phrase Grounding意味着给“蓝色的矿泉水瓶”“三个女人”“穿着白色毛衣的女人”这样的词做定位。
武汉人工智能研究院研究员朱优松博士评价,
这是真正意义上统一,它统一了目标识别和分割这种传统计算视觉理解的任务,以及大模型的图文对话类的任务(图文描述,图文问答)。
“统一”是一个学术上的专业术语。这里用吞并来形容更合适。
虽然方法不开源,但是论文上已经实现了。
意料之内,又是意料之外。
11月份,BLIP系列又上新了,X-InstructBLIP。
就是这次,连Salesforce的联合创始人、董事长兼首席执行官贝尼奥夫(Marc Benioff)都在推特(X)上高度评价:
“推出X-InstructBLIP,由Salesforce公司AI团队提供的最佳开创性可扩展跨模态框架!它彻底改变了大语言模型与文本、图像、视频、声音和3D的互动方式。”
来自CEO的公开认可,这下全世界都看到了。
X-InstructBLIP结构大致沿用和保持了一直以来的做法,在大语言模型的输入侧接了其他模态的编码器,所有模态都和文本做对齐。而且无论哪种模态,都是万能的Q-former做对齐。
很多国产大模型也采用这个思路,目前看来,这已经是一个主流思路了。
BLIP系列的作者之一,李俊男博士默默转帖了CEO的表扬帖。

第十五集,Gemini出场,两雄俱立
Gemini全面模型的能力栈没有公布,只是释放部分表格,所以,整个社区一直有诟病的声音。也许有些人是失望的,但谷歌还算是在2023年最后一个月放出了大招,赶上了年终末班车。
2023全年主打一个高压节奏感,算法进展像连续射击的机关枪一样。看慢镜头回放,出膛的子弹又颗颗无虚发。
易东博士则感慨:
“仅仅一个季度过去之后,我们就发现BLIP系列的结构太复杂了,不用这么复杂的结构,也能跑出一个较好的效果,甚至比它更强的效果。”
人们正在解决图片和文本的“对齐”,新思想新思路从四面八方喷涌而出。
有一种关于多模态的说法很好玩:
把语言模态之外的其他模态比作是一种“外语(Foreign Language)”,其他的模态需要翻译。比如,将图像视为一种外语,通过语言指令将视觉任务与语言任务进行对齐。
这种“外语”的说法,在清华大学电子系代季峰老师团队的论文(VisionLLM)中也能看到。这种类比可以帮助我们更好地理解多模态人工智能大模型的工作原理。
这一年里,能称得上系列的,有BLIP系列,Kosmos系列,以及LLAVA系列。
好消息是,不是低质量内卷式竞争,既有算法思路上的创新,也有训练数据上的创新。
图文双模态的宽阔大门已经打开,算法在前进。
前几年,按年进化;2023年,周周迭代,月月精进。
武汉人工智能研究院王金桥院长谈道:
“大语言模型目前架构比较成熟稳定了,但是VLM前景无限,正处于迅猛发展之中。图文模型大部分是在解决如何将语言和图像对齐,而且都是用大语言模型来引导多模态。”
尾声
这篇一开始打算写完BLIP系列就交稿的文章,被花式出新的模型倒逼着越写越长,硬生生成了一篇年终盘点稿。
也好,沸腾也好,沉寂也罢,都要和2023年告别。
标题就叫做《富矿爆发前夜:图文大模型2023年回顾与盘点》吧。
世间充满巧合,图文之冠——GPT-4V(ision)有一篇微软公司撰写的报告,
标题是《LMM的黎明》。
前夜和黎明,总让人期待。
大语言模型,仅凭一己之力擎天架海,显著加速了通用人工智能的进展。
而全球AI科学家攻下图文融合这个山头的鏖战正在进行之中。
一旦图文融合找到极好的方法,局势就会改变。
愿将来,胜过往。
科技一往无前,冲向通用人工智能。
全文审核专家:



(完)

《我看见了风暴:人工智能基建革命》,
作者:谭婧















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









