







本文是 tf.keras 系列教程的第七篇。介绍了 Keras function API 可以实现的功能。
Keras function API 是一种创建模型的方法,该模型比 tf.keras.Sequential API 更灵活。function API 可以处理具有非线性拓扑的模型,具有共享层的模型以及具有多个输入或输出的模型。深度学习模型通常是层的有向无环图(Directed Acyclic Graph, DAG)的主要思想。因此,功能性API是一种构建层图的方法。
文章目录
代码环境:
python version: 3.7.6
tensorflow version: 2.1.0
导入必要的包:
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
tf.keras.backend.clear_session() # 重置keras的状态
1. 概要
考虑以下模型:
(input: 784-dimensional vectors)
↧
[Dense (64 units, relu activation)]
↧
[Dense (64 units, relu activation)]
↧
[Dense (10 units, softmax activation)]
↧
(output: logits of a probability distribution over 10 classes)
这是一个三层网络。要使用功能性API(function API)构建此模型,需要先创建一个输入节点:
inputs = keras.Input(shape=(784,))
数据的形状设置为784维向量。shape 只需指定每个样本的shape即可,不需要考虑batch_size的大小。如果输入的是shape为(32, 32, 3)的图像,则可以使用:
img_inputs = keras.Input(shape=(32, 32, 3))
inputs 返回输入的shape和数据类型dtype:
inputs.shape # TensorShape([None, 784])
inputs.dtype # tf.float32
通过在 inputs 对象上调用一个layer,可以在图层图中创建一个新节点:
dense = layers.Dense(64, activation='relu')
x = dense(inputs)
“图层调用”操作就像从“输入”到创建的该图层绘制箭头。将输入“传递”到Dense层,然后得到x。在层图中添加更多层:
x = layers.Dense(64, activation='relu')(x)
outputs = layers.Dense(10)(x)
此时,通过在层图中指定模型的输入和输出来创建模型:
model = keras.Model(inputs=inputs, outputs=outputs, name='mnist_model')
查看模型摘要信息:
model.summary()
输出:
Model: "mnist_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 784)] 0
_________________________________________________________________
dense (Dense) (None, 64) 50240
_________________________________________________________________
dense_1 (Dense) (None, 64) 4160
_________________________________________________________________
dense_2 (Dense) (None, 10) 650
=================================================================
Total params: 55,050
Trainable params: 55,050
Non-trainable params: 0
_________________________________________________________________
绘制模型图层:
keras.utils.plot_model(model, 'my_first_model.png',dpi=150)
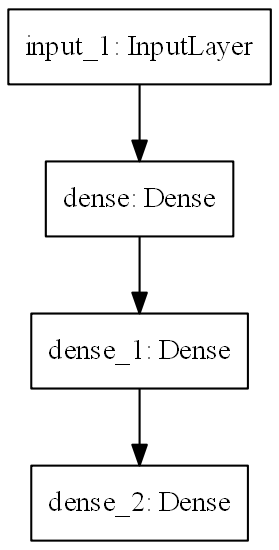
绘图时,通过设置可选参数,显示模型的输入输出尺寸以及每层的名称:
keras.utils.plot_model(model, 'my_first_model_with_shape_info.png', show_layer_names=True, show_shapes=True, dpi=150)

该图和代码几乎相同。在代码版本中,连接箭头由调用操作代替。
2. 模型训练,评估和推断
使用功能性API构建的模型,其训练,评估和推断的工作方式与顺序模型Sequential完全相同。
在这里,加载MNIST图像数据,将其整形为矢量(784),将模型拟合到数据上(同时设置验证集的比例为0.2,并监视其准确率指标),然后在测试数据上评估模型:
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train.reshape(60000, 784).astype('float32') / 255
x_test = x_test.reshape(10000, 784).astype('float32') / 255
model.compile(loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.RMSprop(),
metrics=['accuracy'])
history = model.fit(x_train, y_train,
batch_size=64,
epochs=5,
validation_split=0.2)
test_scores = model.evaluate(x_test, y_test, verbose=2)
print('Test loss:', test_scores[0])
print('Test accuracy:', test_scores[1])
输出:
Train on 48000 samples, validate on 12000 samples
Epoch 1/5
48000/48000 [==============================] - 4s 93us/sample - loss: 0.3414 - accuracy: 0.9040 - val_loss: 0.1884 - val_accuracy: 0.9439
Epoch 2/5
48000/48000 [==============================] - 3s 67us/sample - loss: 0.1616 - accuracy: 0.9513 - val_loss: 0.1532 - val_accuracy: 0.9578
Epoch 3/5
48000/48000 [==============================] - 3s 65us/sample - loss: 0.1197 - accuracy: 0.9648 - val_loss: 0.1253 - val_accuracy: 0.9640
Epoch 4/5
48000/48000 [==============================] - 3s 65us/sample - loss: 0.0947 - accuracy: 0.9715 - val_loss: 0.1185 - val_accuracy: 0.9668
Epoch 5/5
48000/48000 [==============================] - 3s 64us/sample - loss: 0.0801 - accuracy: 0.9762 - val_loss: 0.1061 - val_accuracy: 0.9704
10000/10000 - 1s - loss: 0.0919 - accuracy: 0.9745
Test loss: 0.091879672590876
Test accuracy: 0.9745
3. 保存并序列化模型
使用功能性API构建的模型,保存模型和序列化的方法与顺序模型Sequential进行保存的方式相同。保存功能模型的标准方法是调用 model.save() 将整个模型保存为单个文件。之后可以从该文件重新创建相同的模型。保存的文件包括:
- 模型架构
- 模型权重值(在训练过程中获悉)
- 模型训练配置(compile)
- 优化器及其状态(如果有的话)(从上次中断的地方重新开始训练)
model.save('path_to_my_model')
del model
# 从文件重新创建完全相同的模型:
model = keras.models.load_model('path_to_my_model')

4. 使用同一层图定义多个模型
在功能性API中,通过在层图中指定模型的输入和输出来创建模型。这意味着可以使用单个层图来生成多个模型。
下面的示例中,使用相同的图层来实例化两个模型:一个encoder将图像输入转换为16维向量的编码器模型,以及一个autoencoder用于训练的端到端模型(解码器模型)。
encoder_input = keras.Input(shape=(28, 28, 1), name='img')
x = layers.Conv2D(16, 3, activation='relu')(encoder_input)
x = layers.Conv2D(32, 3, activation='relu')(x)
x = layers.MaxPooling2D(3)(x)
x = layers.Conv2D(32, 3, activation='relu')(x)
x = layers.Conv2D(16, 3, activation='relu')(x)
encoder_output = layers.GlobalMaxPooling2D()(x)
encoder = keras.Model(encoder_input, encoder_output, name='encoder')
encoder.summary()
x = layers.Reshape((4, 4, 1))(encoder_output)
x = layers.Conv2DTranspose(16, 3, activation='relu')(x)
x = layers.Conv2DTranspose(32, 3, activation='relu')(x)
x = layers.UpSampling2D(3)(x)
x = layers.Conv2DTranspose(16, 3, activation='relu')(x)
decoder_output = layers.Conv2DTranspose(1, 3, activation='relu')(x)
autoencoder = keras.Model(encoder_input, decoder_output, name='autoencoder')
autoencoder.summary()
输出:
Model: "encoder"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
img (InputLayer) [(None, 28, 28, 1)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 26, 26, 16) 160
_________________________________________________________________
conv2d_1 (Conv2D) (None, 24, 24, 32) 4640
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 8, 8, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 6, 6, 32) 9248
_________________________________________________________________
conv2d_3 (Conv2D) (None, 4, 4, 16) 4624
_________________________________________________________________
global_max_pooling2d (Global (None, 16) 0
=================================================================
Total params: 18,672
Trainable params: 18,672
Non-trainable params: 0
_________________________________________________________________
Model: "autoencoder"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
img (InputLayer) [(None, 28, 28, 1)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 26, 26, 16) 160
_________________________________________________________________
conv2d_1 (Conv2D) (None, 24, 24, 32) 4640
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 8, 8, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 6, 6, 32) 9248
_________________________________________________________________
conv2d_3 (Conv2D) (None, 4, 4, 16) 4624
_________________________________________________________________
global_max_pooling2d (Global (None, 16) 0
_________________________________________________________________
reshape (Reshape) (None, 4, 4, 1) 0
_________________________________________________________________
conv2d_transpose (Conv2DTran (None, 6, 6, 16) 160
_________________________________________________________________
conv2d_transpose_1 (Conv2DTr (None, 8, 8, 32) 4640
_________________________________________________________________
up_sampling2d (UpSampling2D) (None, 24, 24, 32) 0
_________________________________________________________________
conv2d_transpose_2 (Conv2DTr (None, 26, 26, 16) 4624
_________________________________________________________________
conv2d_transpose_3 (Conv2DTr (None, 28, 28, 1) 145
=================================================================
Total params: 28,241
Trainable params: 28,241
Non-trainable params: 0
_________________________________________________________________
此处,解码架构与编码架构严格对称,因此输出形状与输入形状(28、28、1)相同。
Conv2D层的反面是Conv2DTranspose层,MaxPooling2D层的反面是UpSampling2D层。
5. 模型嵌套调用
模型也可以在任意层的输入或输出上调用,就像调用层一样。通过调用模型,不仅可以重用模型的体系结构,还可以重用其权重。下例是自动编码器示例的另一种处理方式,该示例创建一个编码器模型,一个解码器模型,并将它们链接到两个调用中以获得自动编码器模型:
encoder_input = keras.Input(shape=(28, 28, 1), name='original_img')
x = layers.Conv2D(16, 3, activation='relu')(encoder_input)
x = layers.Conv2D(32, 3, activation='relu')(x)
x = layers.MaxPooling2D(3)(x)
x = layers.Conv2D(32, 3, activation='relu')(x)
x = layers.Conv2D(16, 3, activation='relu')(x)
encoder_output = layers.GlobalMaxPooling2D()(x)
encoder = keras.Model(encoder_input, encoder_output, name='encoder')
encoder.summary()
decoder_input = keras.Input(shape=(16,), name='encoded_img')
x = layers.Reshape((4, 4, 1))(decoder_input)
x = layers.Conv2DTranspose(16, 3, activation='relu')(x)
x = layers.Conv2DTranspose(32, 3, activation='relu')(x)
x = layers.UpSampling2D(3)(x)
x = layers.Conv2DTranspose(16, 3, activation='relu')(x)
decoder_output = layers.Conv2DTranspose(1, 3, activation='relu')(x)
decoder = keras.Model(decoder_input, decoder_output, name='decoder')
decoder.summary()
autoencoder_input = keras.Input(shape=(28, 28, 1), name='img')
encoded_img = encoder(autoencoder_input)
decoded_img = decoder(encoded_img)
autoencoder = keras.Model(autoencoder_input, decoded_img, name='autoencoder')
autoencoder.summary()
输出:
Model: "encoder"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
original_img (InputLayer) [(None, 28, 28, 1)] 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 26, 26, 16) 160
_________________________________________________________________
conv2d_5 (Conv2D) (None, 24, 24, 32) 4640
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 8, 8, 32) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 6, 6, 32) 9248
_________________________________________________________________
conv2d_7 (Conv2D) (None, 4, 4, 16) 4624
_________________________________________________________________
global_max_pooling2d_1 (Glob (None, 16) 0
=================================================================
Total params: 18,672
Trainable params: 18,672
Non-trainable params: 0
_________________________________________________________________
Model: "decoder"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
encoded_img (InputLayer) [(None, 16)] 0
_________________________________________________________________
reshape_1 (Reshape) (None, 4, 4, 1) 0
_________________________________________________________________
conv2d_transpose_4 (Conv2DTr (None, 6, 6, 16) 160
_________________________________________________________________
conv2d_transpose_5 (Conv2DTr (None, 8, 8, 32) 4640
_________________________________________________________________
up_sampling2d_1 (UpSampling2 (None, 24, 24, 32) 0
_________________________________________________________________
conv2d_transpose_6 (Conv2DTr (None, 26, 26, 16) 4624
_________________________________________________________________
conv2d_transpose_7 (Conv2DTr (None, 28, 28, 1) 145
=================================================================
Total params: 9,569
Trainable params: 9,569
Non-trainable params: 0
_________________________________________________________________
Model: "autoencoder"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
img (InputLayer) [(None, 28, 28, 1)] 0
_________________________________________________________________
encoder (Model) (None, 16) 18672
_________________________________________________________________
decoder (Model) (None, 28, 28, 1) 9569
=================================================================
Total params: 28,241
Trainable params: 28,241
Non-trainable params: 0
_________________________________________________________________
由上例可知,模型可以嵌套:模型可以包含子模型(因为模型就像层一样)。模型嵌套的一个常见用例是集合。下例是将一组模型合并为一个平均预测模型的方法:
def get_model():
inputs = keras.Input(shape=(128,))
outputs = layers.Dense(1)(inputs)
return keras.Model(inputs, outputs)
model1 = get_model()
model2 = get_model()
model3 = get_model()
inputs = keras.Input(shape=(128,))
y1 = model1(inputs)
y2 = model2(inputs)
y3 = model3(inputs)
outputs = layers.average([y1, y2, y3]) #以所有形状相同的张量列表作为输入,并返回单个张量(形状也相同)
ensemble_model = keras.Model(inputs=inputs, outputs=outputs)
ensemble_model.summary()
输出:
Model: "model_3"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_6 (InputLayer) [(None, 128)] 0
__________________________________________________________________________________________________
model (Model) (None, 1) 129 input_6[0][0]
__________________________________________________________________________________________________
model_1 (Model) (None, 1) 129 input_6[0][0]
__________________________________________________________________________________________________
model_2 (Model) (None, 1) 129 input_6[0][0]
__________________________________________________________________________________________________
average (Average) (None, 1) 0 model[1][0]
model_1[1][0]
model_2[1][0]
==================================================================================================
Total params: 387
Trainable params: 387
Non-trainable params: 0
6. 复杂的网络拓扑结构模型
6.1 多输入、多输出模型
功能性API使操作多个输入和输出变得容易。SequentialAPI 无法处理此问题。
假设要构建一个按优先级对自定义发行票证排序并将其路由到正确部门的系统,则该模型将具有三个输入:
- 票证的标题(文本输入)
- 票证的文本正文(文本输入)
- 用户添加的标签(分类输入)
此模型将具有两个输出:
- 0和1之间的优先级分数(标量sigmoid输出)
- 应处理票证的部门(部门范围内的softmax输出)
可以使用功能性API构建此模型:
num_tags = 12 # 问题标签的数量
num_words = 10000 # 预处理文本数据时获得的词汇量
num_departments = 4 # 预测部门数
title_input = keras.Input(shape=(None,), name='title') # 可变长度的整数序列
body_input = keras.Input(shape=(None,), name='body') # 可变长度的整数序列
tags_input = keras.Input(shape=(num_tags,), name='tags') # 大小为num_tags的二进制向量
# 将标题中的每个单词嵌入到64维向量中
title_features = layers.Embedding(num_words, 64)(title_input)
# 将文本中的每个单词嵌入到64维向量中
body_features = layers.Embedding(num_words, 64)(body_input)
# 将标题中嵌入单词的序列减少为单个128维向量
title_features = layers.LSTM(128)(title_features)
# 将body内嵌入词的序列化为单个32维向量
body_features = layers.LSTM(32)(body_features)
# 通过concatenate(级联)将所有可用功能合并到单个向量中
# 它以张量列表作为输入,除了级联轴外,它们均具有相同的形状,并返回单个张量,即所有输入的级联。
x = layers.concatenate([title_features, body_features, tags_input])
# 通过特征使用逻辑回归以进行优先级预测
priority_pred = layers.Dense(1, name='priority')(x)
# 通过特征对部分进行分类
department_pred = layers.Dense(num_departments, name='department')(x)
# 实例化预测优先级和部门的端到端模型
model = keras.Model(inputs=[title_input, body_input, tags_input],
outputs=[priority_pred, department_pred])
绘制模型:
keras.utils.plot_model(model, 'multi_input_and_output_model.png', show_shapes=True, dpi=150)

编译此模型时,可以为每个输出分配不同的损失,也可以为每个损失分配不同的权重,以调整它们对总训练损失的贡献。
model.compile(optimizer=keras.optimizers.RMSprop(1e-3),
loss=[keras.losses.BinaryCrossentropy(from_logits=True),
keras.losses.CategoricalCrossentropy(from_logits=True)],
loss_weights=[1., 0.2])
由于输出层具有不同的名称,因此还可以使用字典的方式分配损失:
model.compile(optimizer=keras.optimizers.RMSprop(1e-3),
loss={'priority':keras.losses.BinaryCrossentropy(from_logits=True),
'department': keras.losses.CategoricalCrossentropy(from_logits=True)},
loss_weights=[1., 0.2])
通过传递输入和期望输出的NumPy数组列表来训练模型:
# 构造虚拟输入数据
title_data = np.random.randint(num_words, size=(1280, 10))
body_data = np.random.randint(num_words, size=(1280, 100))
tags_data = np.random.randint(2, size=(1280, num_tags)).astype('float32')
# 构造期望输出数据
priority_targets = np.random.random(size=(1280, 1))
dept_targets = np.random.randint(2, size=(1280, num_departments))
# 训练
model.fit({'title': title_data, 'body': body_data, 'tags': tags_data},
{'priority': priority_targets, 'department': dept_targets},
epochs=2,
batch_size=32)
6.2 ResNet 模型(非线性模型)
功能性API 除了具有多个输入和输出的模型之外,还使操作非线性连接拓扑变得更加容易,这些模型的层不是顺序连接,因此使用SequentialAPI无法处理。
为CIFAR10建立一个简单的ResNet模型来演示这一点:
inputs = keras.Input(shape=(32, 32, 3), name='img')
x = layers.Conv2D(32, 3, activation='relu')(inputs)
x = layers.Conv2D(64, 3, activation='relu')(x)
block_1_output = layers.MaxPooling2D(3)(x)
x = layers.Conv2D(64, 3, activation='relu', padding='same')(block_1_output)
x = layers.Conv2D(64, 3, activation='relu', padding='same')(x)
block_2_output = layers.add([x, block_1_output]) # 输入张量列表,返回输入的总和。
x = layers.Conv2D(64, 3, activation='relu', padding='same')(block_2_output)
x = layers.Conv2D(64, 3, activation='relu', padding='same')(x)
block_3_output = layers.add([x, block_2_output])
x = layers.Conv2D(64, 3, activation='relu')(block_3_output)
x = layers.GlobalAveragePooling2D()(x)
x = layers.Dense(256, activation='relu')(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(10)(x)
model = keras.Model(inputs, outputs, name='toy_resnet')
model.summary()
绘制网络结构:
keras.utils.plot_model(model, 'mini_resnet.png', show_shapes=True, dpi=150)

训练:
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
model.compile(optimizer=keras.optimizers.RMSprop(1e-3),
loss=keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['acc'])
model.fit(x_train, y_train,
batch_size=64,
epochs=1,
validation_split=0.2)
7. 共享层
功能API的另一个很好的用途是使用共享层(share layers)的模型。共享层是在同一模型中多次重复使用的层实例。它们学习与层图中的多个路径相对应的特征。
共享层通常用于编码相似空间中的输入(例如,两个具有相似词汇的不同文本)。它们使得能够在这些不同的输入之间共享信息,并且使得有可能在更少的数据上训练这种模型。如果在输入之一中看到给定的单词,这将有利于处理通过共享层的所有输入。
要在功能API中共享层,即多次调用同一层实例。下例是一个在两个不同的文本输入之间共享的嵌入层:
# 嵌入映射到128维向量的1000个单词
shared_embedding = layers.Embedding(1000, 128)
text_input_a = keras.Input(shape=(None,), dtype='int32')
text_input_b = keras.Input(shape=(None,), dtype='int32')
# 重用同一层来编码两个输入
encoded_input_a = shared_embedding(text_input_a)
encoded_input_b = shared_embedding(text_input_b)
8. 提取和重用层图中的节点
由于要处理的层图是静态数据结构,因此可以对其进行访问和检查。这就是将功能模型绘制为图像的方式。
这也意味着可以访问中间层(图中的“节点”)的激活并将它们在其他地方重用。这对于诸如特征提取之类的操作非常有用。
下例是一个在ImageNet上预训练权重的VGG19模型:
vgg19 = tf.keras.applications.VGG19()
通过查询图形数据结构获得模型的中间激活:
feat_extraction_model = keras.Model(inputs=vgg19.input, outputs=features_list)
img = np.random.random((1, 224, 224, 3)).astype('float32')
extracted_features = feat_extraction_model(img)
9. 使用自定义层扩展API
tf.keras 包括各种内置层,例如:
- 卷积层:Conv1D,Conv2D,Conv3D,Conv2DTranspose
- 池化层:MaxPooling1D,MaxPooling2D,MaxPooling3D,AveragePooling1D
- RNN层:GRU,LSTM,ConvLSTM2D
- BatchNormalization,Dropout,Embedding,等。
但是,如果找不到所需的内容,则可以通过创建自己的图层来扩展API。所有层将Layer类归类并实现:
- call 方法,指定由图层完成的计算。
- build方法,创建图层的权重(这只是一种样式约定,也可以在__init__中创建权重)。
以下是的tf.keras.layers.Dense 层的基本实现:
class CustomDense(layers.Layer):
def __init__(self, units=32):
super(CustomDense, self).__init__()
self.units = units
def build(self, input_shape):
self.w = self.add_weight(shape=(input_shape[-1], self.units),
initializer='random_normal',
trainable=True)
self.b = self.add_weight(shape=(self.units,),
initializer='random_normal',
trainable=True)
def call(self, inputs):
return tf.matmul(inputs, self.w) + self.b
inputs = keras.Input((4,))
outputs = CustomDense(10)(inputs)
model = keras.Model(inputs, outputs)
为了在自定义图层中支持序列化,需要定义一个get_config返回图层实例的构造函数参数的方法:
class CustomDense(layers.Layer):
def __init__(self, units=32):
super(CustomDense, self).__init__()
self.units = units
def build(self, input_shape):
self.w = self.add_weight(shape=(input_shape[-1], self.units),
initializer='random_normal',
trainable=True)
self.b = self.add_weight(shape=(self.units,),
initializer='random_normal',
trainable=True)
def call(self, inputs):
return tf.matmul(inputs, self.w) + self.b
def get_config(self):
return {'units': self.units}
inputs = keras.Input((4,))
outputs = CustomDense(10)(inputs)
model = keras.Model(inputs, outputs)
config = model.get_config()
new_model = keras.Model.from_config(config, custom_objects={'CustomDense': CustomDense})
10. function API 的相关问题
1.什么时候应该使用Keras功能API创建新模型,或者直接将其子Model类化?
通常,功能性API是更高级别的,更容易且更安全的API,并且具有许多子类化模型不支持的功能。
但是,当构建不容易表示为有向无环图的模型时,模型子类提供了更大的灵活性。例如,无法使用功能性API来实现Tree-RNN,而必须使用Model直接进行子类化。
2.定义时进行模型验证
在功能性API中,输入(shape和dtype)是预先创建的(使用Input)。每次调用图层时,该图层都会检查传递给它的规范是否符合其假设,如果不符合,它将引发有用的错误消息。
这样可以保证可以使用功能性API构建的任何模型都可以运行。除了与收敛有关的调试外,所有调试都在模型构建过程中静态发生,而不是在执行时发生。这类似于编译器中的类型检查。
3.功能模型是可绘制和可检查的
可以将模型绘制为图形,并且可以轻松访问此图形中的中间节点。例如,要提取并重用中间层的激活(如前面的示例所示):
features_list = [layer.output for layer in vgg19.layers]
feat_extraction_model = keras.Model(inputs=vgg19.input, outputs=features_list)
4.功能模型可以序列化或克隆
因为功能模型是数据结构而不是一段代码,所以它可以安全地序列化,并且可以保存为单个文件,从而可以重新创建完全相同的模型,而无需访问任何原始代码。
5.功能性API的弱点
(1)不支持动态架构
功能性API将模型视为层的DAG(有向无环图)。对于大多数深度学习架构而言,这是正确的,但并非全部适用。例如,递归网络或Tree RNN不遵循此假设,并且无法在功能性API中实现。
(2)需要从头开始编写
在编写高级体系结构时,可能想做超出DAG层范围的事情,必须使用模型子类在模型实例上编写多个自定义训练和推断方法。















 552
552











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











