







文章目录
单通道Conv2D(通俗意义上的卷积)运算示意图。
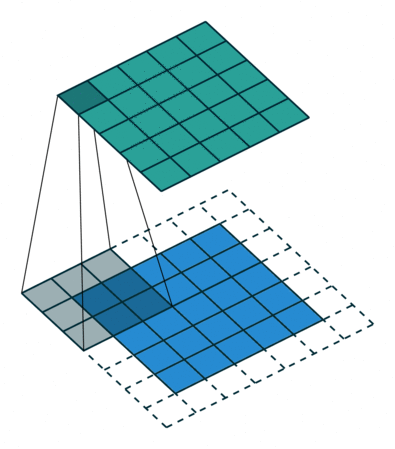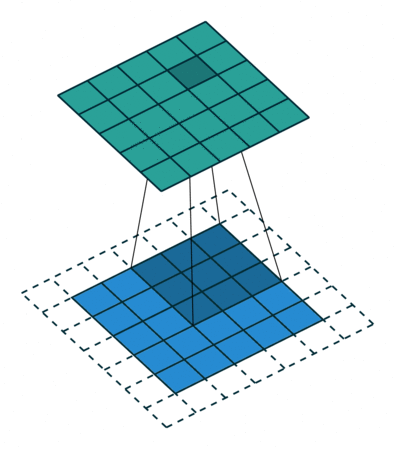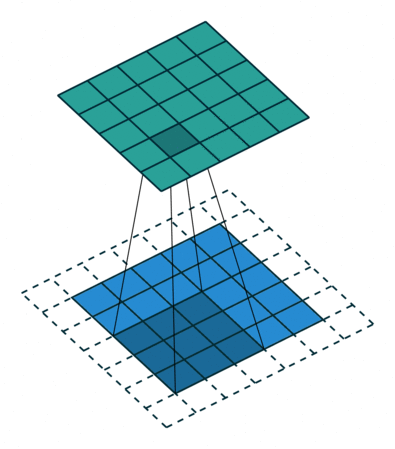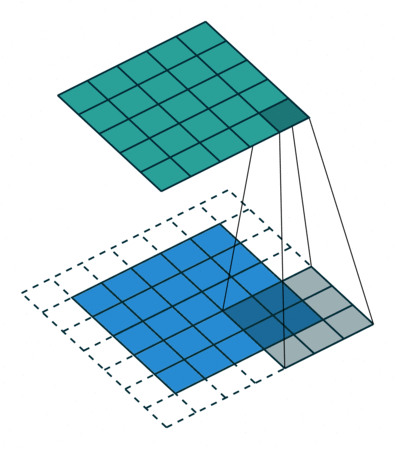
- 卷积运算:卷积核在输入信号(图像)上滑动,相应位置上进行乘加。
- 卷积核:又称为滤波器,过滤器,可认为是某种特征。
- 卷积过程类似于用一个模版去图像上寻找与它相似的区域,与卷积核模式越相似,激活值越高,从而实现特征提取。下图为AlexNet卷积核可视化,可以看出,卷积核学习到的是 边缘,条纹,色彩这些特征。

- 卷积维度:一般情况下 ,卷积核在几个维度上滑动就是几维卷积。
Conv1D/2D/3D的区别
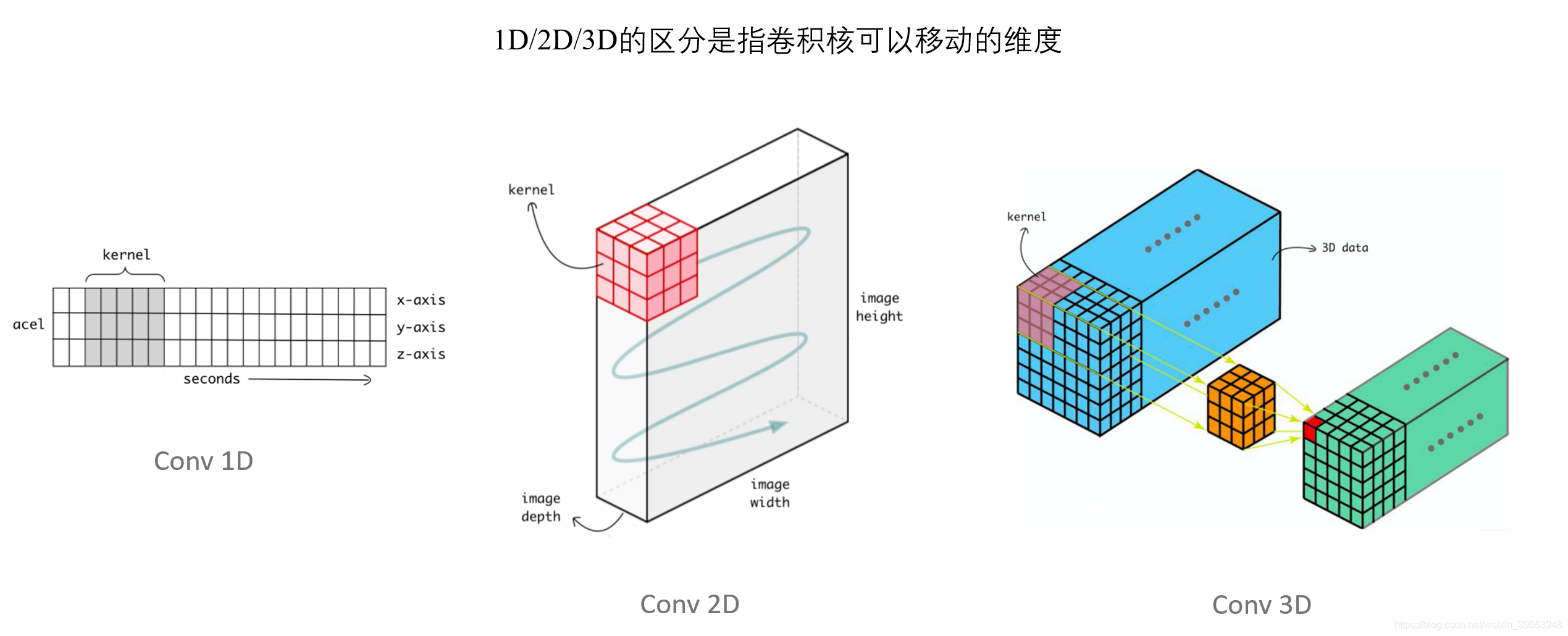
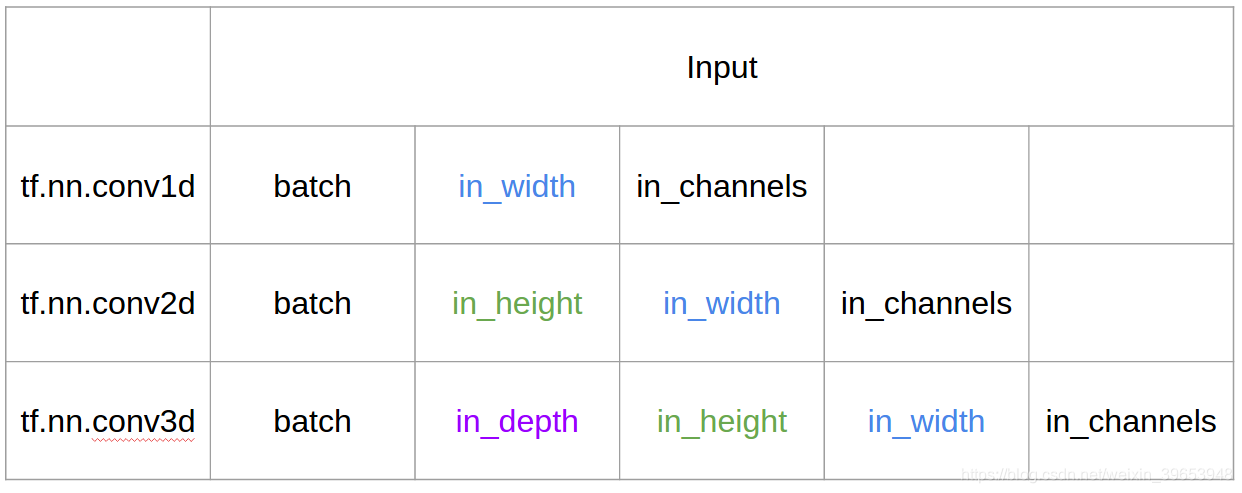
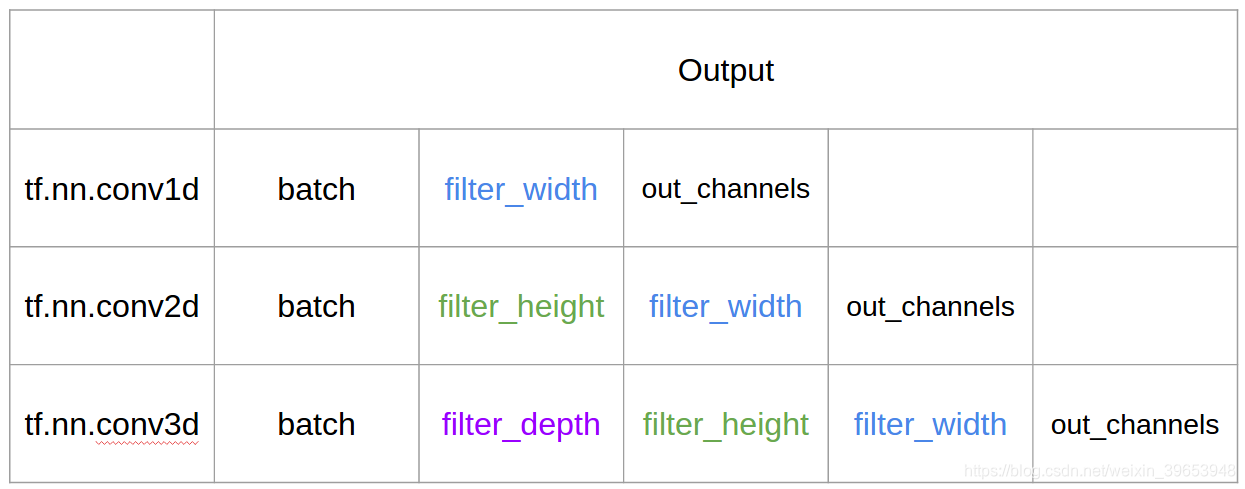
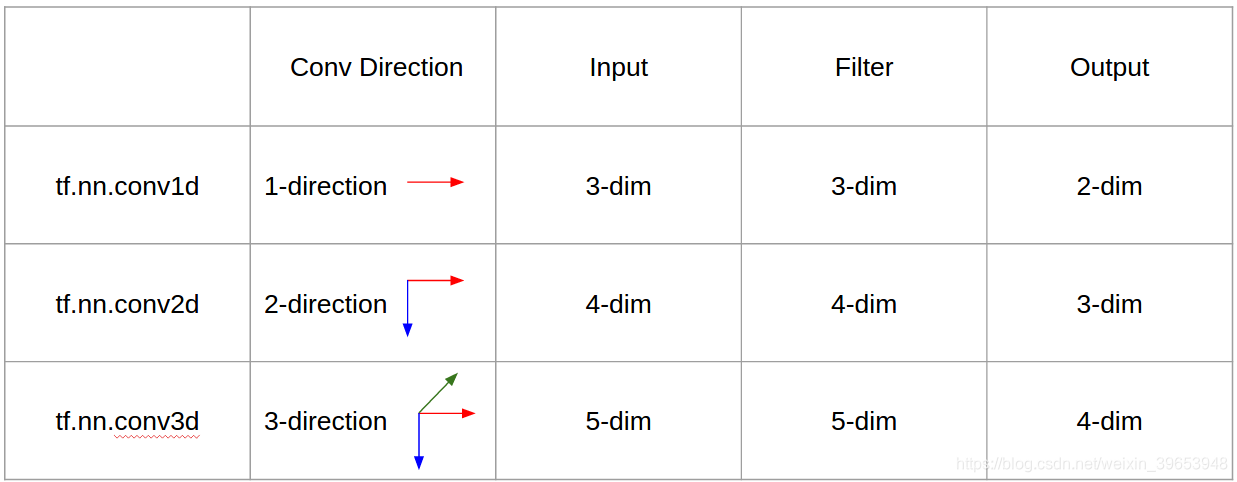
1. Conv1D
官方文档:LINK
torch.nn.Conv1d(in_channels: int,
out_channels: int,
kernel_size: Union[int, Tuple[int]],
stride: Union[int, Tuple[int]] = 1,
padding: Union[int, Tuple[int]] = 0,
dilation: Union[int, Tuple[int]] = 1,
groups: int = 1,
bias: bool = True,
padding_mode: str = 'zeros')
参数说明:
in_channels (int)– 输入通道数;out_channels (int)– :输出通道数,等价于卷积核个数;kernel_size (int or tuple)– 卷积核大小;stride (int or tuple, optional)– 卷积步长,默认为 1;padding (int or tuple, optional)– Zero-padding,默认为 0;padding_mode (string, optional)– ‘zeros’, ‘reflect’, ‘replicate’ or ‘circular’. Default: ‘zeros’;dilation (int or tuple, optional)– 空洞卷积尺寸,默认为 1;groups (int, optional)– 分组卷积设置,Number of blocked connections from input channels to output channels. Default: 1;bias (bool, optional)– If True, adds a learnable bias to the output. Default: True。
Conv1D原理示意图。图自:LINK
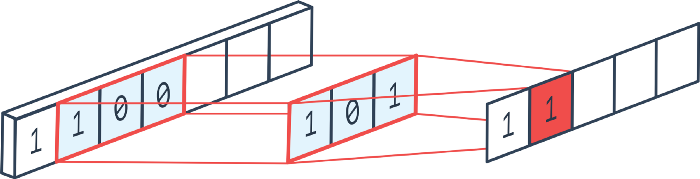
1D输入上的1D卷积示意图。图自:LINK

2D输入上的1D卷积示意图。图自:LINK
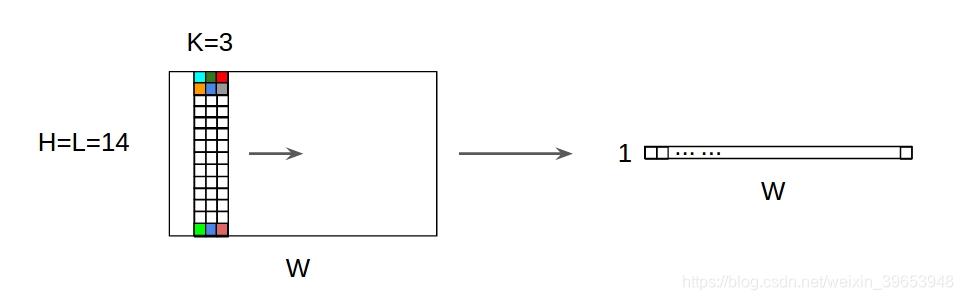
说明:
- 对于一个卷积核(kernel),不管是1D输入还是2D输入,其输出都是1D矩阵;
- 卷积核的高度必须与输入特征图的高度相匹配;即
input = [W,L], filter = [k,L] output = [W]; - 对于多个卷积核的情况,其经过Conv1D之后,输出堆叠为2D矩阵,如果卷积核的个数为N,则输出的尺寸为
1D x N - 1D卷积常用在时间序列数据的建模上。
尺寸计算:

注意:
- 其中, N N N 表示卷积核个数; C i n C_{in} Cin 表示输入通道数; L i n L_{in} Lin 表示输入的长度;
-
C
i
n
C_{in}
Cin 必须与 Conv1D 中设置的
in_channels (int)相等。 -
C
o
u
t
C_{out}
Cout = Conv1D 中设置的
out_channels。
实例:
import torch
m = torch.nn.Conv1d(64, 32, 4, stride=2)# Conv1d(64, 32, kernel_size=(4,), stride=(2,))
input = torch.randn(3, 64, 128) # torch.Size([3, 64, 128])
output = m(input) # torch.Size([3, 32, 63])
L o u t = ⌊ 128 + 2 × 0 − 1 × ( 4 − 1 ) − 1 ⌋ 2 + 1 = 63 L{out} = \frac{\lfloor 128+2 \times 0 - 1 \times(4-1) - 1 \rfloor}{2} + 1= 63 Lout=2⌊128+2×0−1×(4−1)−1⌋+1=63
2. Conv2D
官方文档:LINK
torch.nn.Conv2d(in_channels: int,
out_channels: int,
kernel_size: Union[int, Tuple[int, int]],
stride: Union[int, Tuple[int, int]] = 1,
padding: Union[int, Tuple[int, int]] = 0,
dilation: Union[int, Tuple[int, int]] = 1,
groups: int = 1,
bias: bool = True,
padding_mode: str = 'zeros')
参数说明:
in_channels (int)– 输入通道数;out_channels (int)– :输出通道数,等价于卷积核个数;kernel_size (int or tuple)– 卷积核大小;stride (int or tuple, optional)– 卷积步长,默认为 1;padding (int or tuple, optional)– Zero-padding,默认为 0;padding_mode (string, optional)– ‘zeros’, ‘reflect’, ‘replicate’ or ‘circular’. Default: ‘zeros’;dilation (int or tuple, optional)– 空洞卷积尺寸,默认为 1;groups (int, optional)– 分组卷积设置,Number of blocked connections from input channels to output channels. Default: 1;bias (bool, optional)– If True, adds a learnable bias to the output. Default: True。
Conv2D原理示意图。图自:LINK
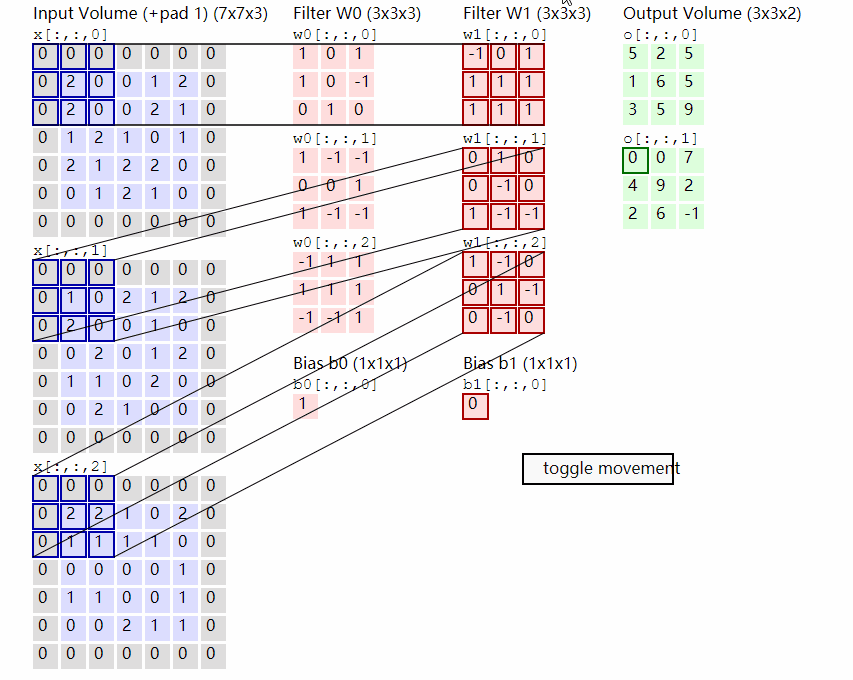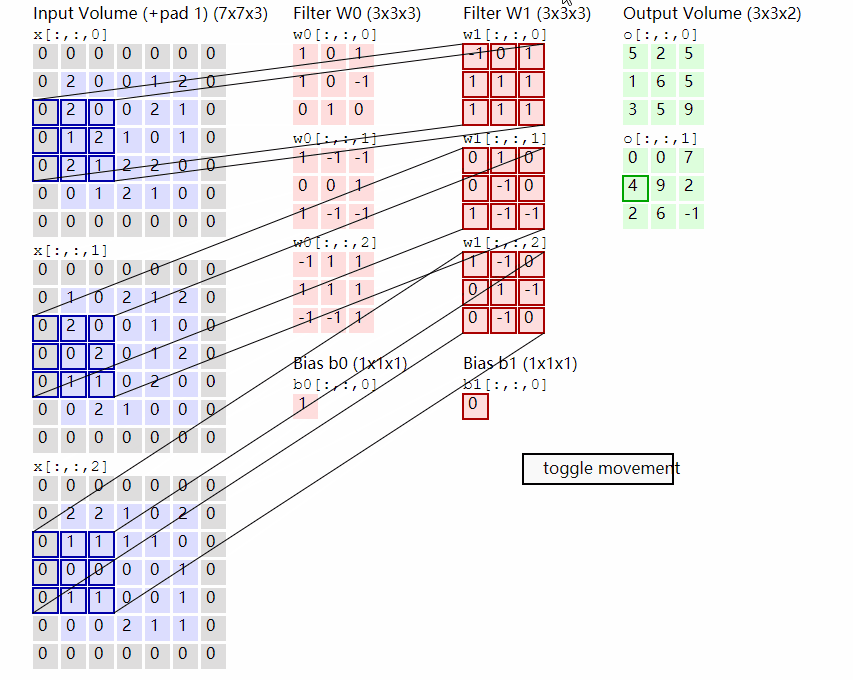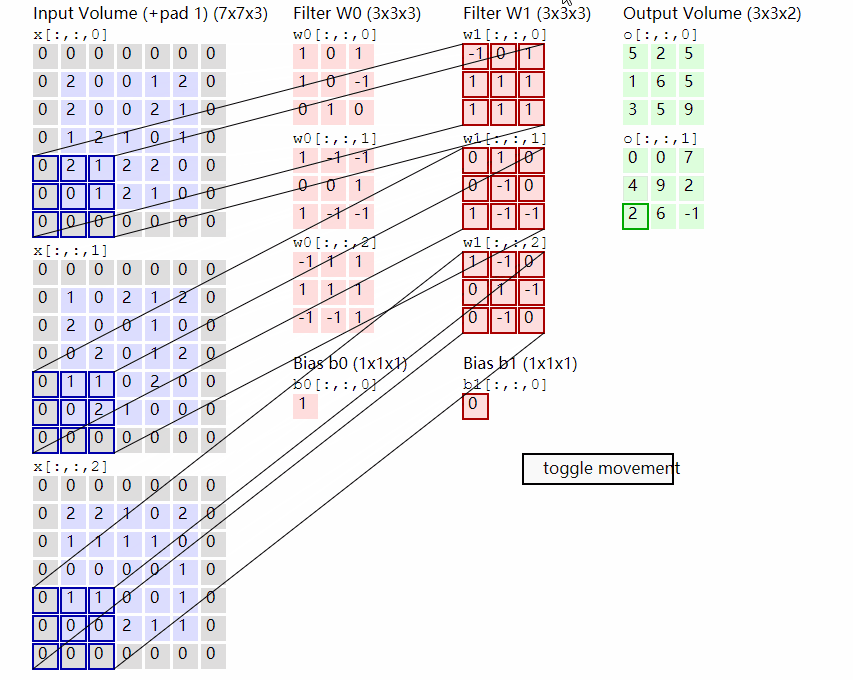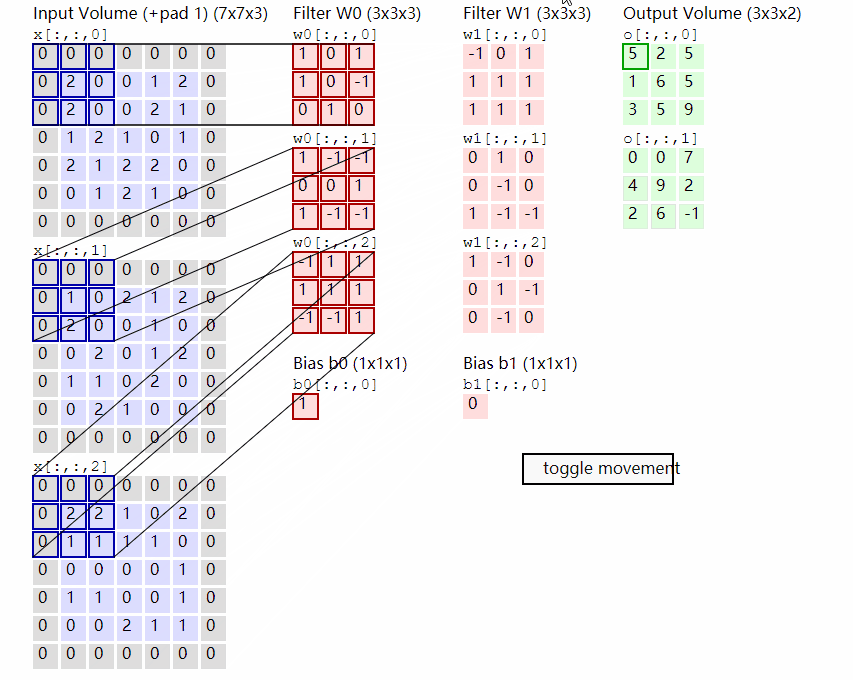
输出计算:

3. Conv3D
官方文档:LINK
torch.nn.Conv3d(in_channels: int,
out_channels: int,
kernel_size: Union[int, Tuple[int, int, int]],
stride: Union[int, Tuple[int, int, int]] = 1,
padding: Union[int, Tuple[int, int, int]] = 0,
dilation: Union[int, Tuple[int, int, int]] = 1,
groups: int = 1,
bias: bool = True,
padding_mode: str = 'zeros')
参数说明:同上。
Conv3D示意图。
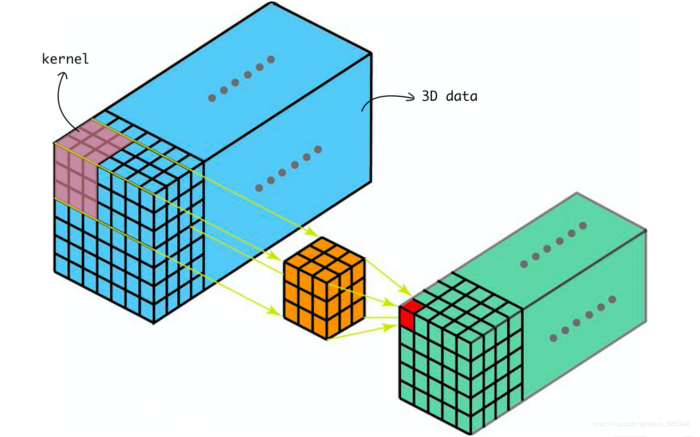
Conv3D示意图。图自:LINK
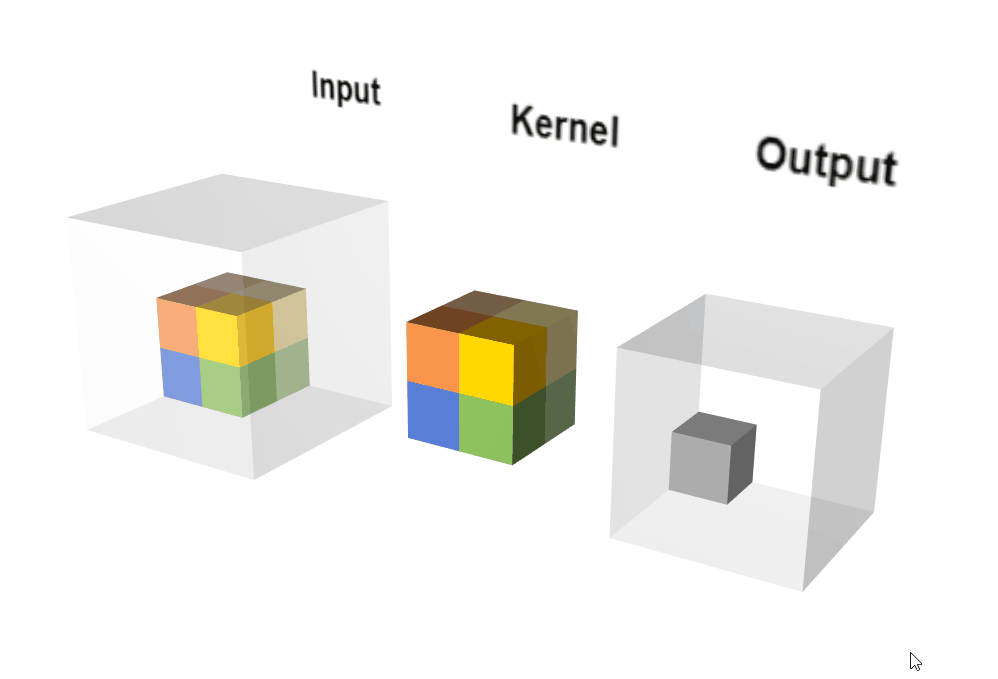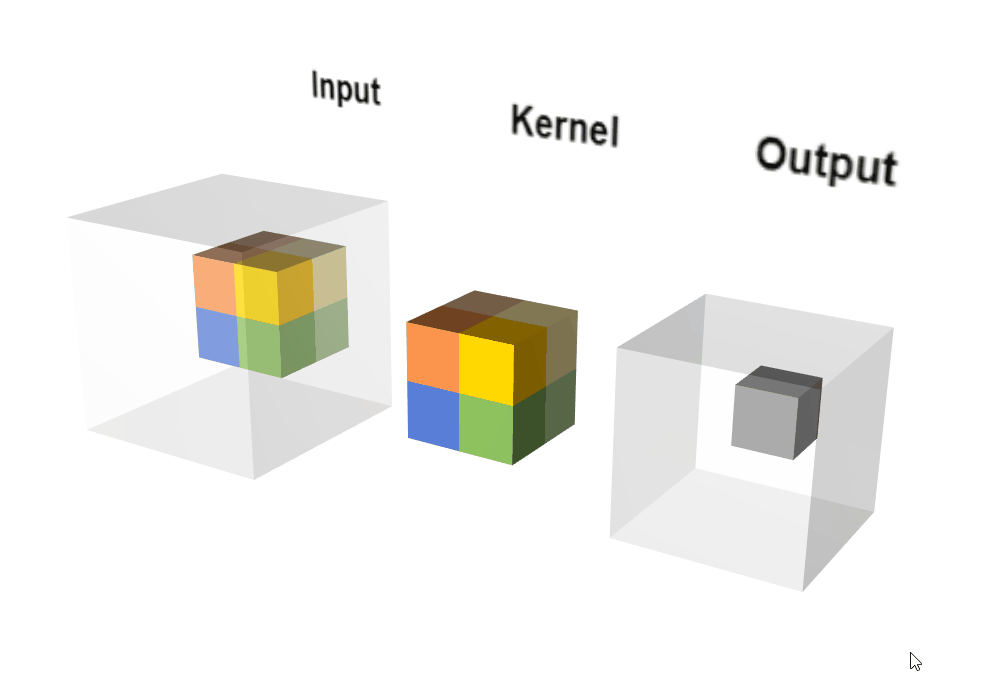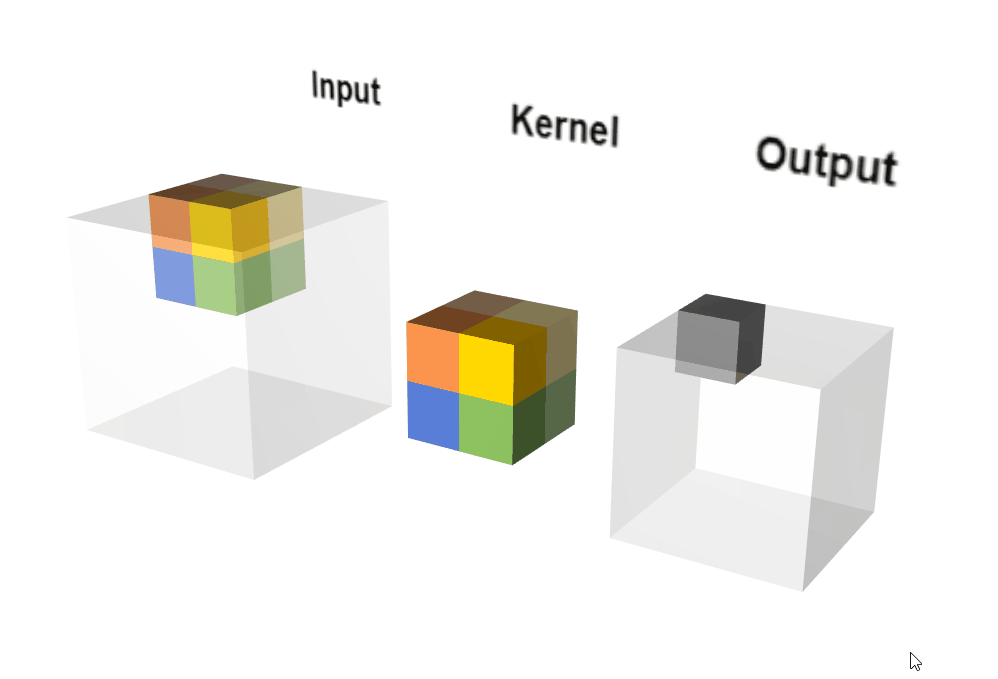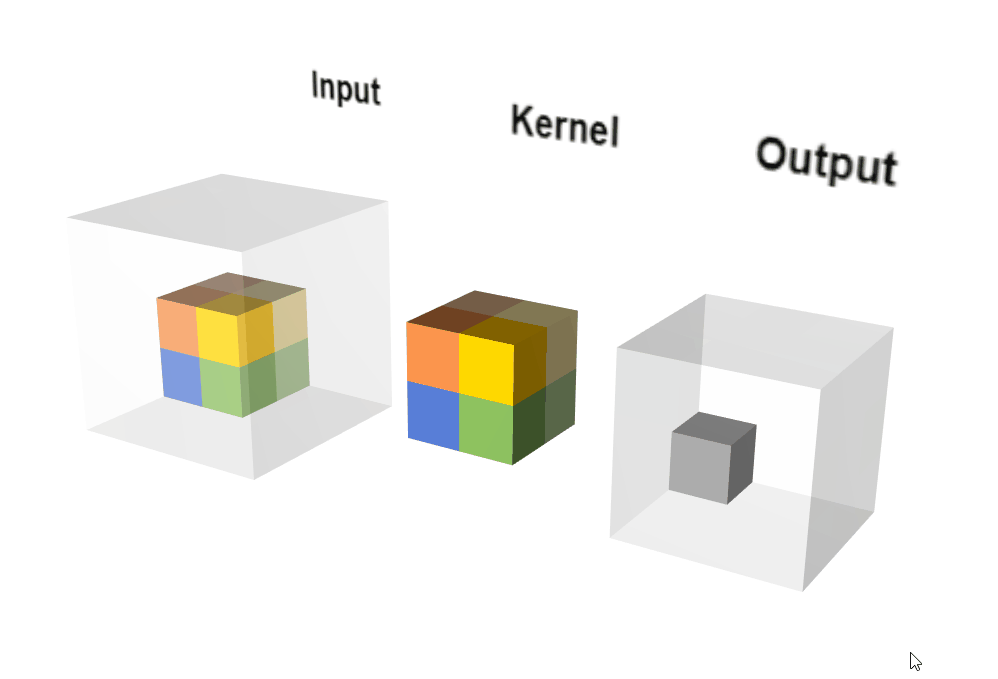
说明:
- 3D 卷积常用于医学影像图像分割以及视频中的动作检测。
- 【Paper】3D Convolutional Neural Network for Brain Tumor Segmentation
输出计算:

4. 空洞卷积
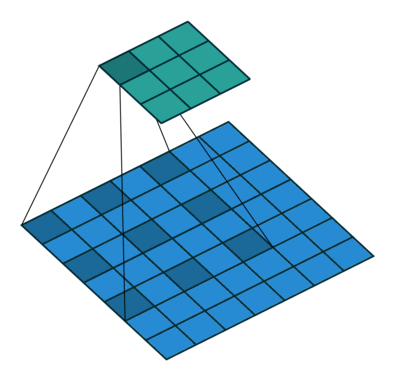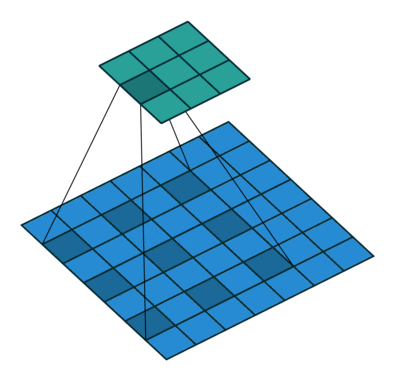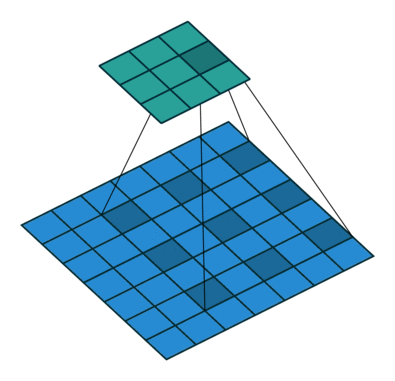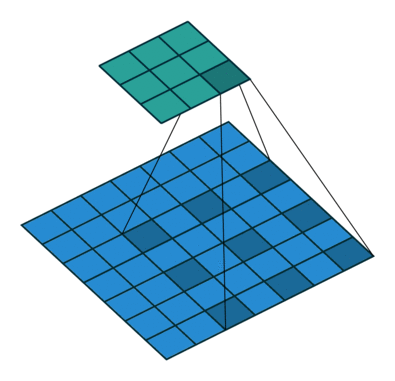
空洞卷积诞生于图像分割领域,比如FCN网络,首先像传统的CNN一样,先卷积后池化,经过池化层之后,图像尺寸降低,感受野增大,但是因为图像分割需要实现像素级的输出,所以要将经过池化之后的较小的特征图通过转置卷积(反卷积)降采样到与原始图像相同的尺寸。之前的池化操作使得原特征图中的每个像素都具有较大的感受野,因此FCN中的两个关键:一是通过池化层增大感受野,二是通过转置卷积增大图像尺寸。在先减小后增大的过程中,肯定会丢失信息,那么能否不同池化层也可以使得网络具有较大的感受野呢?空洞卷积应运而生。
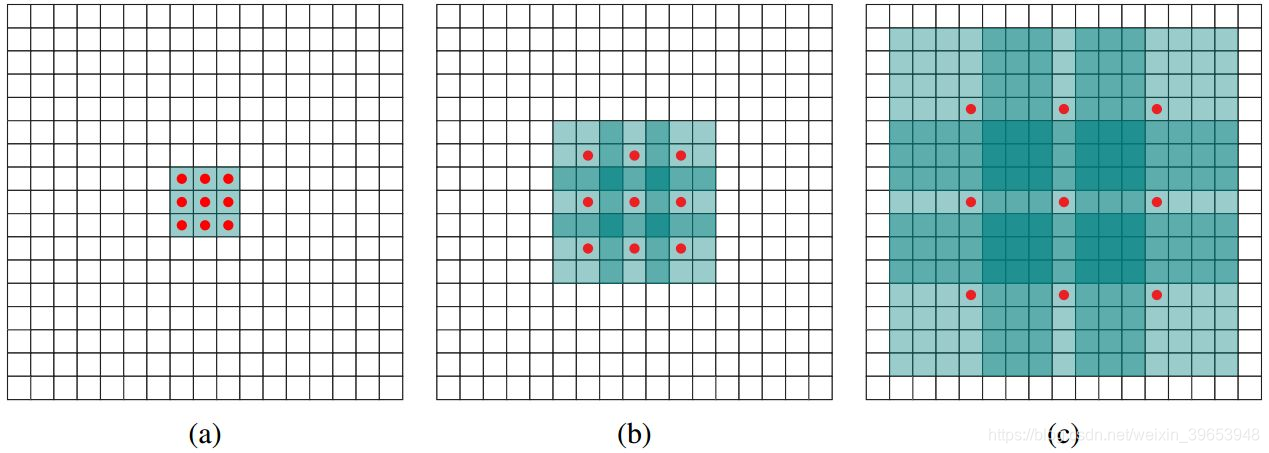
(a)图对应3x3的1-dilated conv,和普通的卷积操作一样;(b)图对应3x3的2-dilated conv,实际的卷积 kernel size 还是 3x3,但是空洞为1,也就是对于一个7x7的图像patch,只有9个红色的点和3x3的kernel发生卷积操作,其余的点略过。也可以理解为kernel的size为7x7,但是只有图中的9个点的权重不为0,其余都为0。 可以看到虽然kernel size只有3x3,但是这个卷积的感受野已经增大到了7x7(如果考虑到这个2-dilated conv的前一层是一个1-dilated conv的话,那么每个红点就是1-dilated的卷积输出,所以感受野为3x3,所以1-dilated和2-dilated合起来就能达到7x7的conv);(c)图是4-dilated conv操作,同理跟在两个1-dilated和2-dilated conv的后面,能达到15x15的感受野。对比传统的conv操作,3层3x3的卷积加起来,stride为1的话,只能达到(kernel-1)*layer+1=7的感受野,也就是和层数layer成线性关系,而dilated conv的感受野是指数级的增长。- dilated的好处是不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。在图像需要全局信息或者语音文本需要较长的sequence信息依赖的问题中,都能很好的应用dilated conv,比如图像分割[3]、语音合成WaveNet[2]、机器翻译ByteNet[1]中。
关于空洞卷积的理解可参考:如何理解空洞卷积(dilated convolution)?作者:谭旭
5. 转置卷积
卷积是使输出大小变小的过程。 因此,而反卷积(deconvolution)可以进行向上采样以增大输出大小。但是,反卷积并代表卷积的逆过程。因此它也被称为向上卷积或转置卷积(transposed convolution)。 当使用分数步幅时,也称为分数步幅卷积(fractional stride convolution)。
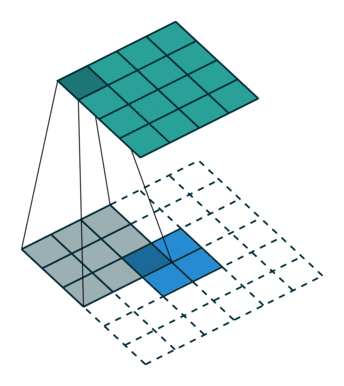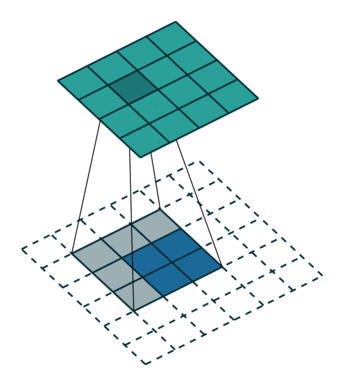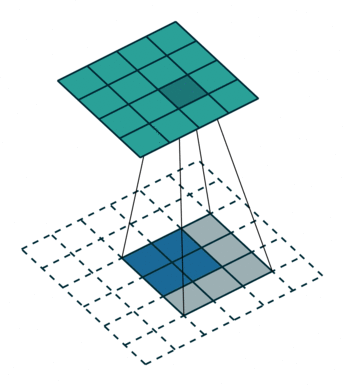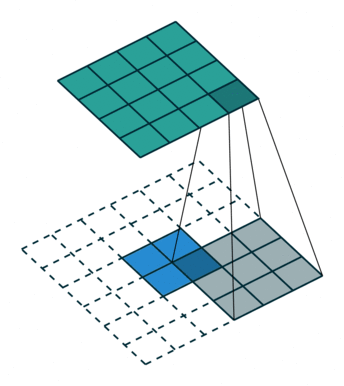
正常卷积:
- 假设图像尺寸为 4×4,卷积核为 3×3,padding=0,stride=1;
- 图像: I 𝟏 𝟔 ∗ 𝟏 I_{𝟏𝟔∗𝟏} I16∗1;卷积核: K 𝟒 ∗ 𝟏 𝟔 K_{𝟒∗𝟏𝟔} K4∗16;输出: O 𝟒 ∗ 𝟏 = K 𝟒 ∗ 𝟏 𝟔 ∗ I 𝟏 𝟔 ∗ 𝟏 O_{𝟒∗𝟏}=K_{𝟒∗𝟏𝟔}∗I_{𝟏𝟔∗𝟏} O4∗1=K4∗16∗I16∗1
转置卷积:
- 假设图像尺寸为 2×2 ,卷积核为 3×3,padding=0,stride=1;
- 图像: I 𝟒 ∗ 𝟏 I_{𝟒∗𝟏} I4∗1;卷积核: K 𝟏 𝟔 ∗ 4 K_{𝟏𝟔∗4} K16∗4;输出: O 16 ∗ 𝟏 = K 𝟏 𝟔 ∗ 𝟒 ∗ I 𝟒 ∗ 𝟏 O_{16∗𝟏}=K_{𝟏𝟔∗𝟒}∗I_{𝟒∗𝟏} O16∗1=K16∗4∗I4∗1
5.1 ConvTranspose1d
官方文档:LINK
torch.nn.ConvTranspose1d(in_channels: int,
out_channels: int,
kernel_size: Union[int, Tuple[int]],
stride: Union[int, Tuple[int]] = 1,
padding: Union[int, Tuple[int]] = 0,
output_padding: Union[int, Tuple[int]] = 0,
groups: int = 1,
bias: bool = True,
dilation: Union[int, Tuple[int]] = 1,
padding_mode: str = 'zeros')
in_channels (int)– Number of channels in the input imageout_channels (int)– Number of channels produced by the convolutionkernel_size (int or tuple)– Size of the convolving kernelstride (int or tuple, optional)– Stride of the convolution. Default: 1padding (int or tuple, optional)–dilation * (kernel_size - 1) - paddingzero-padding will be added to both sides of the input. Default: 0output_padding (int or tuple, optional)– Additional size added to one side of the output shape. Default: 0groups (int, optional)– Number of blocked connections from input channels to output channels. Default: 1bias (bool, optional)– If True, adds a learnable bias to the output. Default: Truedilation (int or tuple, optional)– Spacing between kernel elements. Default: 1
输出计算:
- I n p u t : ( N , C i n , L i n ) Input: (N, C_{in}, L_{in}) Input:(N,Cin,Lin)
- O u t p u t : ( N , C o u t , L o u t ) Output: (N, C_{out}, L_{out}) Output:(N,Cout,Lout)
- L o u t = ( L i n − 1 ) × s t r i d e − 2 × p a d d i n g + d i l a t i o n × ( k e r n e l s i z e − 1 ) + o u t p u t p a d d i n g + 1 L_{out}=(L_{in}−1)×stride−2×padding+dilation×(kernelsize−1)+outputpadding+1 Lout=(Lin−1)×stride−2×padding+dilation×(kernelsize−1)+outputpadding+1
5.2 ConvTranspose2d
官方文档:LINK
torch.nn.ConvTranspose2d(in_channels: int,
out_channels: int,
kernel_size: Union[int, Tuple[int, int]],
stride: Union[int, Tuple[int, int]] = 1,
padding: Union[int, Tuple[int, int]] = 0,
output_padding: Union[int, Tuple[int, int]] = 0,
groups: int = 1,
bias: bool = True,
dilation: int = 1,
padding_mode: str = 'zeros')
输出计算:
- I n p u t : ( N , C i n , H i n , W i n ) Input: (N, C_{in}, H_{in}, W_{in}) Input:(N,Cin,Hin,Win)
- O u t p u t : ( N , C o u t , H o u t , W o u t ) Output: (N, C_{out}, H_{out}, W_{out}) Output:(N,Cout,Hout,Wout)
- H o u t = ( H i n − 1 ) × s t r i d e [ 0 ] − 2 × p a d d i n g [ 0 ] + d i l a t i o n [ 0 ] × ( k e r n e l s i z e [ 0 ] − 1 ) + o u t p u t p a d d i n g [ 0 ] + 1 H_{out} =(H_{in} −1)×stride[0]−2×padding[0]+dilation[0]×(kernelsize[0]−1)+outputpadding[0]+1 Hout=(Hin−1)×stride[0]−2×padding[0]+dilation[0]×(kernelsize[0]−1)+outputpadding[0]+1
- W o u t = ( W i n − 1 ) × s t r i d e [ 1 ] − 2 × p a d d i n g [ 1 ] + d i l a t i o n [ 1 ] × ( k e r n e l s i z e [ 1 ] − 1 ) + o u t p u t p a d d i n g [ 1 ] + 1 W_{out} =(W_{in} −1)×stride[1]−2×padding[1]+dilation[1]×(kernelsize[1]−1)+outputpadding[1]+1 Wout=(Win−1)×stride[1]−2×padding[1]+dilation[1]×(kernelsize[1]−1)+outputpadding[1]+1
5.3 ConvTranspose3d
官方文档:LINK
torch.nn.ConvTranspose3d(in_channels: int,
out_channels: int,
kernel_size: Union[int, Tuple[int, int, int]],
stride: Union[int, Tuple[int, int, int]] = 1,
padding: Union[int, Tuple[int, int, int]] = 0,
output_padding: Union[int, Tuple[int, int, int]] = 0,
groups: int = 1,
bias: bool = True,
dilation: Union[int, Tuple[int, int, int]] = 1,
padding_mode: str = 'zeros')
输出计算:
- I n p u t : ( N , C i n , D i n , H i n , W i n ) Input: (N, C_{in}, D_{in}, H_{in}, W_{in}) Input:(N,Cin,Din,Hin,Win)
- O u t p u t : ( N , C o u t , D o u t , H o u t , W o u t ) Output: (N, C_{out}, D_{out}, H_{out}, W_{out}) Output:(N,Cout,Dout,Hout,Wout)
- D o u t = ( D i n − 1 ) × s t r i d e [ 0 ] − 2 × p a d d i n g [ 0 ] + d i l a t i o n [ 0 ] × ( k e r n e l s i z e [ 0 ] − 1 ) + o u t p u t p a d d i n g [ 0 ] + 1 D_{out} =(D_{in} −1)×stride[0]−2×padding[0]+dilation[0]×(kernelsize[0]−1)+outputpadding[0]+1 Dout=(Din−1)×stride[0]−2×padding[0]+dilation[0]×(kernelsize[0]−1)+outputpadding[0]+1
- H o u t = ( H i n − 1 ) × s t r i d e [ 1 ] − 2 × p a d d i n g [ 1 ] + d i l a t i o n [ 1 ] × ( k e r n e l s i z e [ 1 ] − 1 ) + o u t p u t p a d d i n g [ 1 ] + 1 H_{out} =(H_{in} −1)×stride[1]−2×padding[1]+dilation[1]×(kernelsize[1]−1)+outputpadding[1]+1 Hout=(Hin−1)×stride[1]−2×padding[1]+dilation[1]×(kernelsize[1]−1)+outputpadding[1]+1
- W o u t = ( W i n − 1 ) × s t r i d e [ 2 ] − 2 × p a d d i n g [ 2 ] + d i l a t i o n [ 2 ] × ( k e r n e l s i z e [ 2 ] − 1 ) + o u t p u t p a d d i n g [ 2 ] + 1 W_{out}=(W_{in} −1)×stride[2]−2×padding[2]+dilation[2]×(kernelsize[2]−1)+outputpadding[2]+1 Wout=(Win−1)×stride[2]−2×padding[2]+dilation[2]×(kernelsize[2]−1)+outputpadding[2]+1
6. 深度可分离卷积
MobileNet中大量使用的了深度可分离卷积(Depth-wise Separable Convolutions),主要起到降低参数量,增加非线性,跨通道信息融合的作用。
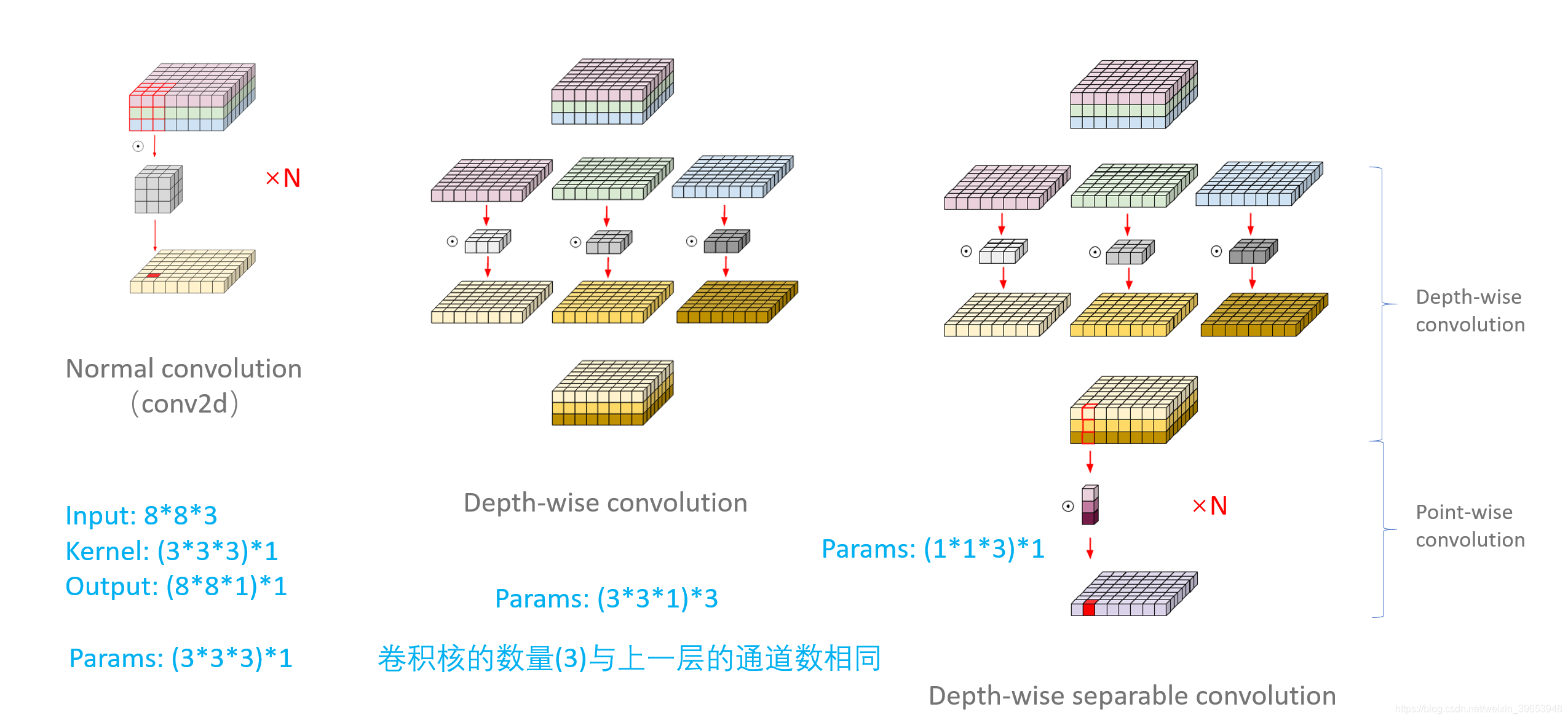
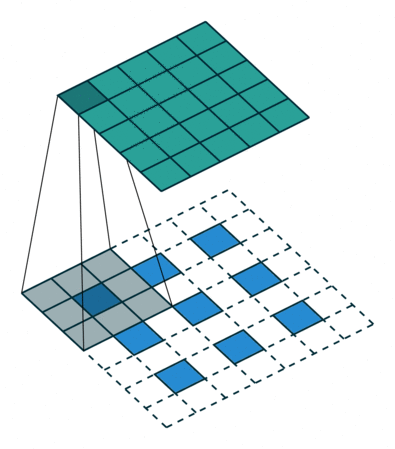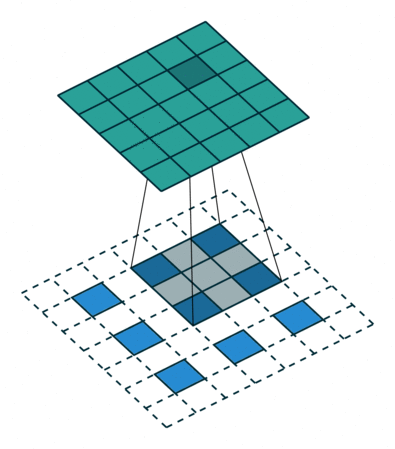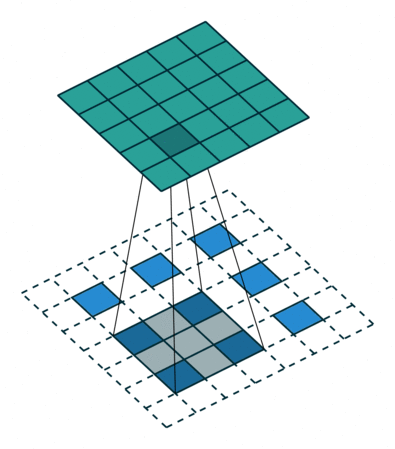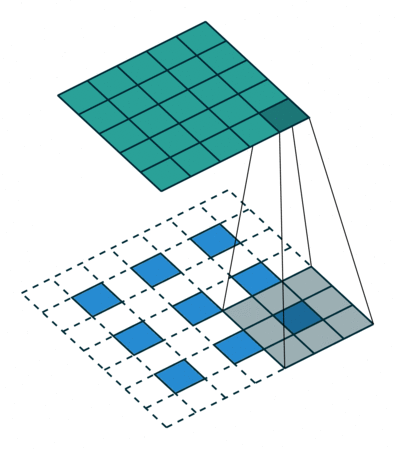
7. 其它卷积操作
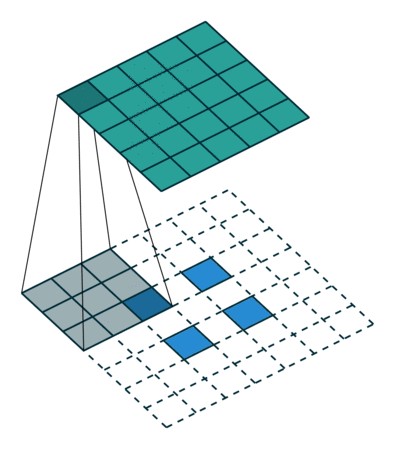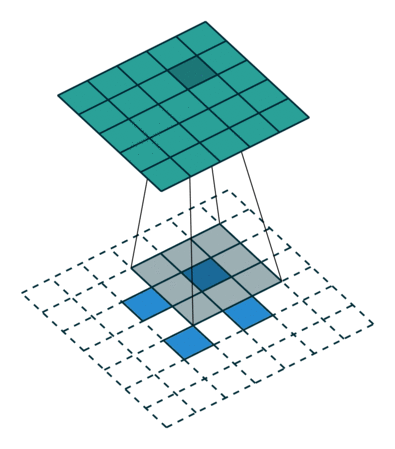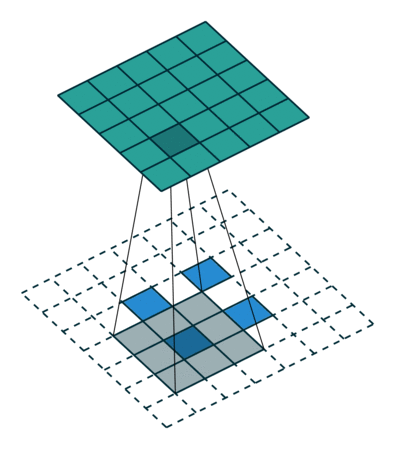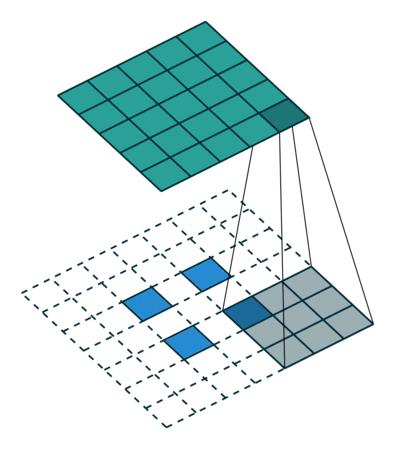
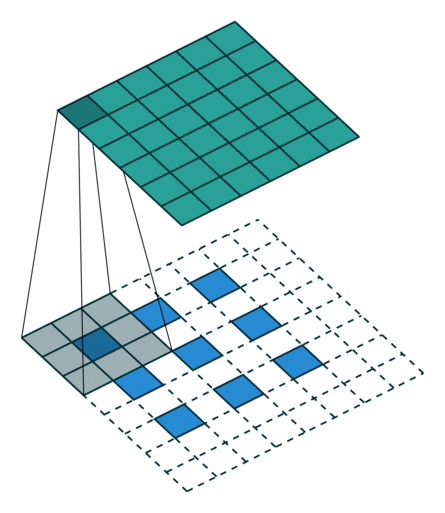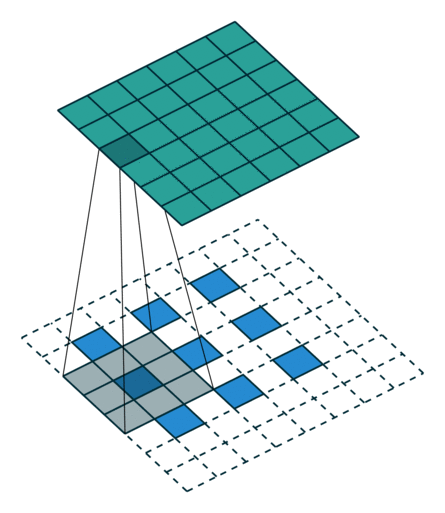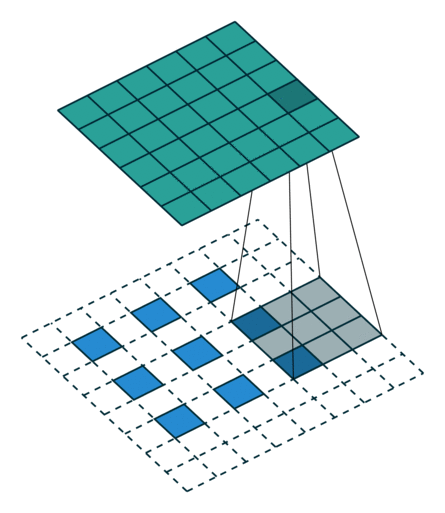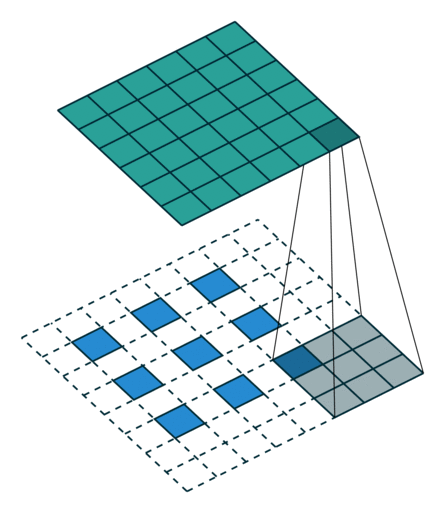
参考:
https://towardsdatascience.com/pytorch-basics-how-to-train-your-neural-net-intro-to-cnn-26a14c2ea29
https://medium.com/@xzz201920/conv1d-conv2d-and-conv3d-8a59182c4d6
https://stackoverflow.com/questions/42883547/intuitive-understanding-of-1d-2d-and-3d-convolutions-in-convolutional-neural-n
卷积可视化:https://github.com/vdumoulin/conv_arithmetic
https://thomelane.github.io/convolutions/3DConv.html
https://medium.com/apache-mxnet/1d-3d-convolutions-explained-with-ms-excel-5f88c0f35941
https://towardsdatascience.com/review-fcn-semantic-segmentation-eb8c9b50d2d1



















 1245
1245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











