







点击进入专栏:
《人工智能专栏》 Python与Python | 机器学习 | 深度学习 | 目标检测 | YOLOv5及其改进 | YOLOv8及其改进 | 关键知识点 | 各种工具教程
文章目录
- 简介各种卷积
- 深入浅出可分离卷积
- 可分离卷积及普通卷积与分组卷积对比
- 一文看尽深度学习中的8种卷积(附源码整理和论文解读)
-
- 引言
- 1. 原始卷积(Vanilla Convolution)
- 2. 组卷积(Group convolution)
- 3. 转置卷积(Transposed Convolution)
- 4. 1×1 Convolution
- 5. 空洞卷积(Atrous convolution)
- 6. 深度可分离卷积(Depthwise Separable Convolution)
- 7. 可变形卷积(Deformable convolution)
- 8. 空间可分离卷积(Spatially Separable Convolution)
- 5. 动态卷积(Dynamic Convolution)
- 1. 机器学习
- 2. 深度学习与目标检测
- 3. YOLOv5
- 4. YOLOv5改进
- 5. YOLOv8及其改进
- 6. Python与PyTorch
- 7. 工具
- 8. 小知识点
- 9. 杂记
简介各种卷积
1 卷积介绍
1.1 什么是卷积
卷积(convolution),是一种运算,你可以类比于加,减,乘,除,矩阵的点乘与叉乘等等,它有自己的运算规则,卷积的符号是星号*。表达式为:
连续卷积表达式:
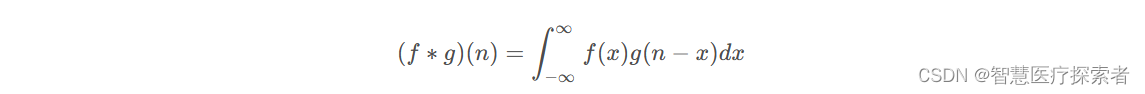
离散卷积表达式为:
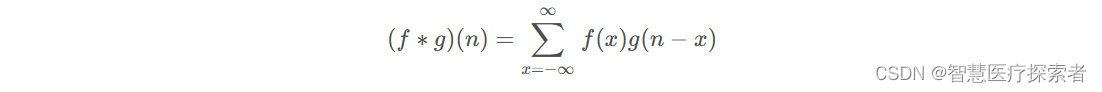
从参数上来看,x + (n-x) = n,可以类比为x + y = n,也就是说f, g的参数满足规律y = -x + n,即g的参数是f的参数先翻转再平移n。把g从右边褶到左边去,也就是卷积的卷的由来。然后在这个位置对两个函数的对应点相乘,然后相加,这个过程是卷积的积的过程。
因此卷积的过程可以理解为:翻转,滑动,叠加。其中翻转指的是g,滑动指的是n值在不断改变。最终将他们相乘相加。
1.2 卷积的意义
在泛函分析中,卷积、旋积或褶积是通过两个函数f和g生成第三个函数的一种数学运算,其本质是一种特殊的积分变换,表征函数f与g经过翻转和平移的重叠部分函数值乘积对重叠长度的积分。

如果将参加卷积的一个函数看作区间的指示函数,卷积还可以被看作是“滑动平均”的推广。卷积的意义如下:
- 模拟生物视觉:卷积操作模拟了人眼对图像进行观察、辨认的过程,因此卷积在图像处理领域应用广泛。它可以帮助我们理解人类视觉系统如何工作,并且为我们提供了一种有效的处理图像和语音的方法。
- 提升算法性能:卷积神经网络(CNN)是目前深度学习中最重要的模型之一,其基本结构就是卷积层,卷积操作在图像识别、语音识别和自然语言处理等领域提升了算法的性能。这使得卷积成为了现代机器学习和人工智能的重要组成部分。
- 数据压缩:卷积可以通过降维和滤波等操作减小数据的尺寸,从而实现数据的压缩。这对于处理大规模数据、实现数据存储和传输非常有用。
1.3 图像的卷积处理
对图像的blur操作,即降噪平滑操作,就是使用的卷积运算,最终的效果取决于卷积核的设置。以单通道卷积为例。
均值卷积核,就是认为目标像素点的值是周围值的平均数,即周围各点对它的影响是一样的,此处卷积核以3X3为例。

高斯滤波认为各个像素点距离核中心的距离不一样,导致颜色的贡献程度不一样,因此给不同的点不同的权重。取图像中的部分像素点

我们把这个矩阵看成f(x,y)函数,下标为参数,像素点的值为函数结果,那么要求f(1,1)处的卷积运算结果,因为现在是二维函数了,因此对应的卷积表达式为:

对应到本例u=1, v=1

我们来构建g(1-x, 1-y)函数,暂定为3X3的矩阵,我们知道目标点f(1,1)要对应g(0,0),如果将g(0,0)设置在核的中心,那么根据下标展开之后我们就可以构建出g

有了g函数之后,就可以执行运算了,注意运算的时候 f 和 g 的参数要符合卷积公式,即

其实这样就够了,但是便于理解和说明,我们将矩阵先沿着X轴翻转,再沿Y轴翻转,中心点在 g(0,0) 处,得到

虽然翻转了,但是运算公式没有变化,只是从观察上更好一一对应,也更方便计算。

注意,将卷积核盖在目标像素点上面,将对应的像素点相乘相加,这种运算应该叫互相关运算(cross-correlation),通过将g进行翻转,使得卷积运算变成了互相关运算,将翻转之后的矩阵称为卷积核,并且在设计卷积核的时候就是参照互相关运算来的,而不会去关心真正的卷积运算。因此在实际应用中通常是直接去构建这个最终的矩阵。
在后续的计算中,将结果赋值给f(1,1),然后向右平移一格,达到边界后向下平移一格继续从左边开始卷积。整个过程中最外一层无法被算到,解决的方法是将原图像向外扩大一圈像素点并设置为0。通过设置不同的卷积核来达到不同的结果,这是机器视觉的基础操作。
2 pytorch中的卷积
CNN是深度学习的重中之重,而conv1D,conv2D,和conv3D又是CNN的核心,所以理解conv的工作原理就变得尤为重要,卷积中几个核心概念如下:
- 卷积运算:卷积核在输入信号(图像)上滑动,相应位置上进行乘加。
- 卷积核:又称为滤波器,过滤器,可认为是某种特征。
- 卷积过程类似于用一个模版去图像上寻找与它相似的区域,与卷积核模式越相似,激活值越高,从而实现特征提取。
- 卷积维度:一般情况下 ,卷积核在几个维度上滑动就是几维卷积。

2.1 一维卷积nn.Conv1d
一维卷积nn.Conv1d主要用于文本数据,只对宽度进行卷积,对高度不卷积。通常,输入大小为word_embedding_dim * max_length,其中,word_embedding_dim为词向量的维度,max_length为句子的最大长度。卷积核窗口在句子长度的方向上滑动,进行卷积操作。
2.1.1 函数原型
torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
参数说明:
- in_channels (int) – 输入通道数;在文本应用中,即为词向量的维度;
- out_channels (int) – :输出通道数,等价于卷积核个数;
- kernel_size (int or tuple) – 卷积核大小;卷积核的第二个维度由
in_channels决定,所以实际上卷积核的大小为kernel_size * in_channels - stride (int or tuple, optional) – 卷积步长,默认为 1;
- padding (int or tuple, optional) – Zero-padding,默认为 0;对输入的每一条边,补充0的层数;
- padding_mode (string, optional) – ‘zeros’, ‘reflect’, ‘replicate’ or ‘circular’. Default: ‘zeros’;
- dilation (int or tuple, optional) – 空洞卷积尺寸,默认为 1;
- groups (int, optional) – 分组卷积设置,Number of blocked connections from input channels to output channels. Default: 1;
- bias (bool, optional) – If True, adds a learnable bias to the output. Default: True。
2.1.2 原理示意图

1D输入上的1D卷积示意图:

2D输入上的1D卷积示意图

说明:
- 对于一个卷积核(kernel),不管是1D输入还是2D输入,其输出都是1D矩阵;
- 卷积核的高度必须与输入特征图的高度相匹配;即 input = [W,L], filter = [k,L] output = [W];
- 对于多个卷积核的情况,其经过Conv1D之后,输出堆叠为2D矩阵,如果卷积核的个数为N,则输出的尺寸为 1D x N
- 1D卷积常用在时间序列数据的建模上。
尺寸计算:

注意:
- 其中, N表示卷积核个数;
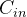 表示输入通道数;
表示输入通道数;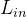 表示输入的长度;
表示输入的长度; 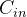 必须与 Conv1D 中设置的 in_channels (int) 相等。
必须与 Conv1D 中设置的 in_channels (int) 相等。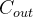 = Conv1D 中设置的 out_channels。
= Conv1D 中设置的 out_channels。
2.1.3 示例代码
输入:批大小为32,句子的最大长度为35,词向量维度为256
目标:句子分类,共2类
import torch
import torch.nn as nn
conv1 = nn.Conv1d(in_channels=256, out_channels=100, kernel_size=2)
input = torch.randn(32, 35, 256)
input  已下架不支持订阅
已下架不支持订阅
















 2086
2086











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











