





雷锋网 AI 科技评论按:在 CVPR 2019 CLIC 图像压缩挑战赛中,图鸭科技所提出的算法 TucodecSSIM 夺得了 MS-SSIM 和 MOS 两项指标的冠军,算法 TucodecPSNR 夺得了 PSNR 指标的冠军,算法 TucodecPSNR40dB 则夺得高码点图像压缩 Transparent Track 的冠军。以下为图鸭科技提供的技术解读。
摘要:
近年来随着人工智能技术的发展,基于深度学习的图像压缩技术已取得了飞速的发展。一个典型的基于深度学习的图像压缩框架包括:自编码网络结构设计、量化、码率估计和率-失真优化等几个模块。本文将主要介绍图鸭科技在 CVPR 2019 CLIC 图像压缩挑战赛上的相关技术方案,针对于比赛所设置的低码点和高码点压缩两个赛道,我们基于变分自编码网络设计了可进行端到端优化的图像压缩方案。该方案包括一个非线性编码网络、软量化模块、一个非线性解码网络和一个熵估计模块。我们技术方案的特色之处总结如下:
1. 提出了基于全局特征分析的 non-lcao 注意力模块,并融合进编码网络和解码网络,以实现提升自适应码字分配性能的目的。
2. 设计了一种基于自适应聚类的软量化方法以降低量化损失。
3. 提出了能融合超先验子网络和基于 pixel cnn++的上下文模型的码率估计模块。
得益于优良的网络结构和算法设计,我们所提出的算法 TucodecSSIM 夺得了 MS-SSIM 和 MOS 两项指标的冠军,算法 TucodecPSNR 夺得了 PSNR 指标的冠军,算法 TucodecPSNR40dB 则夺得高码点图像压缩指标的冠军。接下来将具体介绍我们的算法方案:
方法介绍:
(1) 编码网络和解码网络
我们的主干压缩自编码网络使用了如图 1 所示的非对称结构,它包括卷积、非线性单元和残差 non-local 注意力卷积等模块。值得注意的是,通过使用残差 non-local 注意力模块来对特征的全局关联性进行捕捉和建模,图像中的纹理、边界等复杂部分能得到更好的重建。在 kodak 标准数据集上的实验表明,通过在编码和解码网络结构中融合 non-local 注意力模块,能在 PSNR 指标熵带来 0.6db 的提升。
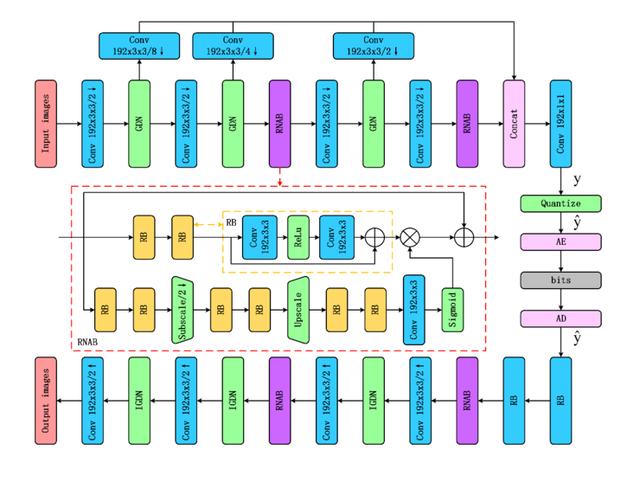
图 1 编码和解码网络结构示意图
(2) 量化
在现在的大部分方案中,取整量化
是一种常用的方式。我们通过实验测评发现,这种直接将浮点数映射到整数的量化方式会极大的降低重建精度(PSNR 指标至少降低 0.5db, MS-SSIM 指标降低至少 1.5db)。为了降低量化带来的精度损失,我们设计了一种基于自适应聚类的软量化方案,具体介绍如下:
给定可学习的中心点
,可使用最近邻分配的方式来计算量化值:
但式 (1) 的量化方式是不可导,因此将使用如下所定义的软分配方式进行替换,以保证在训练过程中能进行端到端的优化:
在用 tensorflow 进行实现时,可以用如下的代码对参数进行量化:
(3) 先验概率和码率估计
为了进行码率估计,使用拉普拉斯分布对压缩特征的分布进行表示,分布的参数包括均值
和方差
。为了对分布的均值和方差进行端到端的计算,设计了如图 2 所示的网络结构:
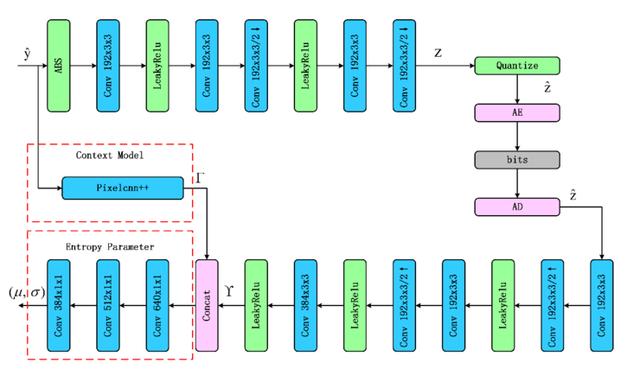
图 2. 码率估计模块示意图,该模块包括超参自编码网络、上下文网络和熵参数网络三部分。
码率估计模块由三个子网络构成:超参网络
,参数为
;上下文网络
,参数为
;熵参数网络
,参数是
。如图 2 所示,超参网络由超参编码网络、量化模块和超参解码网络组成。超参网络的量化特征也需要编码,使用非参的概率密度估计方式进行先验概率建模:
此外我们使用了 Pixelcnn++网络结构对特征的上下文关系进行捕捉和建模;最后使用卷积模块进行熵参数网络的构建,并将超参网络的输出和上下文网络的输出进行级联来作为熵参数网络的输入来计算相应的均值和方差。主干自编码网络压缩特征的分布可以表示为:
最后码率估计将由两部分组成:一部分是对主干自编码网络中压缩特征的估计码率,一部分是超参自编码网络压缩特征的估计码率:
(4) 后处理
在方案 TucodecPSNR 中,我们使用了改进的 266 算法作为基础,但低码率压缩算法重建图最显著的缺点是存在伪影,并且很多纹理细节会丢失。为了改进在低码率条件下重建图的质量,我们设计一个有效地后处理模块,后处理模块的具体细节如图 3 所示。
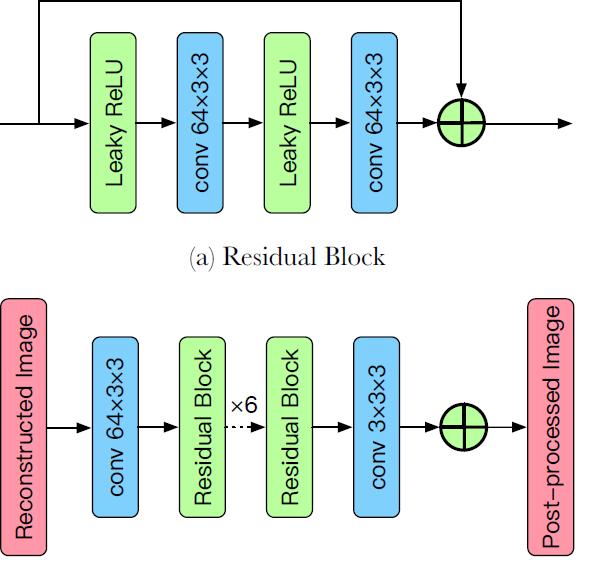
图 3 后处理算法结构示意图
(5) 实验结果
我们从 CLIC 2019 训练集和 flickr.com 上收集了 5000 张高清图片,并从中采集了百万张的图像块作为训练集。为对网络进行高效训练,我们使用 tensorflow 平台对相应网络结构进行实现。在方案 TucodecSSIM 中,进行网络训练使用的损失函数如下所示:
除上述损失函数外,也结合了对抗生成网络对压缩网络进行端到端的训练。为了满足比赛的 0.15bpp 的约束要求,我们训练了 5 个模型分别对应λ=0.2/0.3/0.4/0.5/0.6,最后使用动态规划算法进行码字分配。
在方案 TucodecPSNR40db 中,进行网络训练所使用的损失函数如下所示:
在模型训练完毕后,为了满足比赛的 PSNR 值不小于 40db 和 MS-SSIM 值不小于 0.993 的约束,共训练了 5 个模型,对应的 λ=4096/4800/5500/6500/8000。最后使用动态规划算法进行码字分配。在方案 TucodecPSNR 中,使用了我们改进的 H266 算法作为基础,并结合后处理网络进行性能的提升,我们给出了三个模型,分别对应 QP 36/37/38,并最后进行码字分配以满足 0.15bpp 约束的要求。所提出算法的测评指标如下表所示:
















 7749
7749











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









