







我们先来看一段代码,这段代码似乎触发了Python的bug:
>>> ? = 1>>> f = 2>>> print(?)运行效果如下图所示:
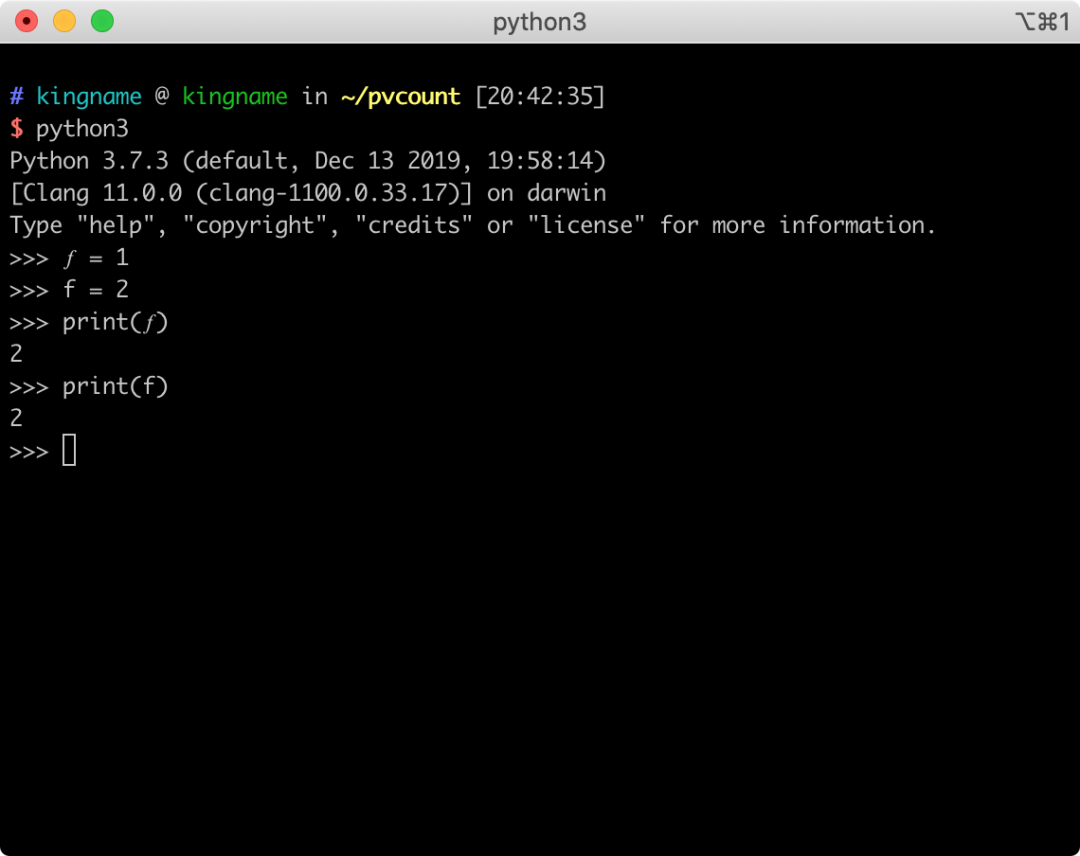
我们知道,Python 的变量名是可以使用 Unicode 字符的,也就是非英文字母也可以当做变量名,例如:
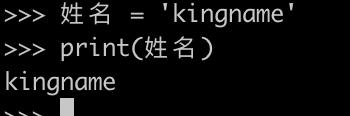
如果大家仔细观察,就会发现上面的?和英文字母f不是同一个字符。

那为什么当我们给f赋值为2以后,原来?的值也改变了呢?这是因为,Python 会把所有的变量名转换为它的 NFKC 等价形式。
从Python的官方文档2.3. Identifiers and keywords[1]中,我们可以看到:
All identifiers are converted into the normal form NFKC while parsing; comparison of identifiers is based on NFKC.
”
转换的原理可以参阅维基百科:Unicode equivalence - Wikipedia[2]。
Python已经自带了一个转换的模块,叫做unicodedata,通过它,我们可以把非标准的Unicode字符转成标准的Unicode字符,例如:
>>> import unicodedata>>> unicodedata.normalize('NFKC', '?')'f'>>> unicodedata.normalize('NFKC', '?') == 'f'True可以看到,手写字符?通过 NFKC 标准转换以后,就是普通的字母f,所以在 Python 里面,如果作为变量名,这两个字符是一样的。
除了英文字符外,中文字符也可以转换。大家应该还记得我之前讲康熙字符那篇文章:康熙部首导致的字典查询异常我们可以使用相同的方式,把康熙部首里面的⽐转换为标准的汉字比:
>>> unicodedata.normalize('NFKC', '⽐') == '比'True这样一来,如果你需要做一个服务,它接收用户的输入,但你又不想让用户输入这种长得像中文或者英文,但是却又不是的怪异字符,你就可以使用 NFKC 把它转换为标准的字符。例如,把中文逗号转成英文逗号,把中文分号转成英文分号,把中文冒号转成英文冒号等等:
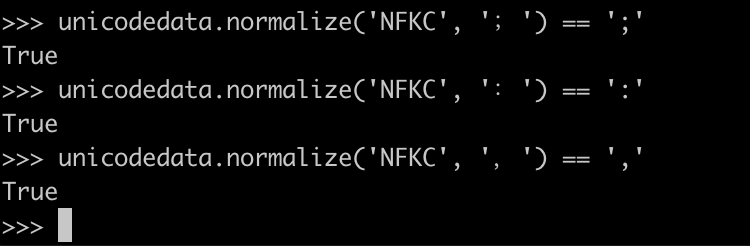
参考资料
[1]2.3. Identifiers and keywords: https://docs.python.org/3/reference/lexical_analysis.html#identifiers
[2]Unicode equivalence - Wikipedia: https://en.wikipedia.org/wiki/Unicode_equivalence#Normalization
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









