







前言
fps,是 frames per second 的简称,也就是我们常说的“帧率”。在游戏领域中,fps 作为衡量游戏性能的基础指标,对于游戏开发和手机 vendor 厂商都是非常重要的数据,而计算游戏的 fps 也成为日常测试的基本需求。目前市面上有很多工具都能够计算 fps,那么这些工具计算 fps 的方法是什么?原理是什么呢?本文将针对这些问题,深入源码进行分析,力求找到一个详尽的答案(源码分析基于 Android Q)
计算方法
目前绝大部分帧率统计软件,在网上能找到的各种统计 fps 的脚本,使用的信息来源有两种:一种是基于 dumpsys SurfaceFlinger --latency Layer-name(注意是 Layer 名字,不是包名,不是 Activity 名字,至于为什么,下面会解答);另一种是基于 dumpsys gfxinfo。其实这两种深究到原理基本上是一致的,本篇文章专注于分析第一种,市面上大部分帧率统计软件用的也是第一种,只不过部分软件为了避免被人反编译看到,将这个计算逻辑封装成 so 库,增加反编译的难度。然而经过验证,这些软件最后都是通过调用上面的命令来计算的 fps 的。
但是这个命令为什么能够计算 fps 呢?先来看这个命令的输出,以王者荣耀为例(王者荣耀这种游戏类的都是以 SurfaceView 作为控件,因此其 Layer 名字都以 SurfaceView - 打头):
> adb shell dumpsys SurfaceFlinger --latency "SurfaceView - com.tencent.tmgp.sgame/com.tencent.tmgp.sgame.SGameActivity#0"1666666659069638658663 59069678041684 5906965415829859069653090955 59069695022100 5906967089423659069671034444 59069711403455 5906968794986159069688421840 59069728057361 5906970441512159069705420850 59069744773350 5906972076783059069719818975 59069761378975 5906973741600759069736702673 59069778060955 5906975456866359069753361528 59069794716007 5906977076163259069768766371 59069811380486 59069787649600......输出的这一堆数字究竟是什么意思?首先,第一行的数字是当前的 VSYNC 间隔,单位是纳秒。例如现在的屏幕是 60Hz 的,因此就是 16.6ms,然后下面的一堆数字,总共有 127 行(为什么是 127 行,下面也会说明),每一行有 3 个数字,每个数字都是时间戳,单位是纳秒,具体的意义后文会说明。而在计算 fps 的时候,使用的是第二个时间戳。原因同样会在后文进行解答。
fence 简析
后面的原理分析涉及到 fence,但是 fence 囊括的内容众多,因此这里只是对 fence 做一个简单地描述。如果大家感兴趣,后面我会专门给 fence 写一篇详细的说明文章。
fence 是什么
首先得先说明一下 App 绘制的内容是怎么显示到屏幕的:
App 需要显示的内容要要绘制在 Buffer 里,而这个 Buffer 是从 BufferQueue 通过 dequeueBuffer() 申请的。申请到 Buffer 以后,App 将内容填充到 Buffer 以后,需要通过 queueBuffer() 将 Buffer 还回去交给 SurfaceFlinger 去进行合成和显示。然后,SurfaceFlinger 要开始合成的时候,需要调用 acquireBuffer() 从 BufferQueue 里面拿一个 Buffer 去合成,合成完以后通过 releaseBuffer() 将 Buffer 还给 BufferQueue,如下图:
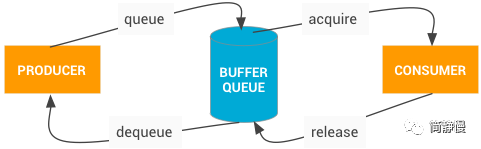
在上面的流程中,其实有一个问题,就是在 App 绘制完通过 queueBuffer() 将 Buffer 还回去的时候,此时仅仅只是 CPU 侧的完成,GPU 侧实际上并没有真正完成。因此如果此时拿这个 Buffer 去进行合成/显示的话,就会有问题(Buffer 可能还没有完全地绘制完)。
事实上,由于 CPU 和 GPU 之前是异步的,因此我们在代码里面执行一系列的 OpenGL 函数调用的时候,看上去函数已经返回了,实际上,只是把这个命令放在本地的 command buffer 里。具体什么时候这条 GL command 被真正执行完毕 CPU 是不知道的,除非使用 glFinish() 等待这些命令完全执行完,但是这样会带来很严重的性能问题,因为这样会使得 CPU 和 GPU 的并行性完全丧失,CPU 会在 GPU 完成之前一直处于空等的状态。因此,如果能够有一种机制,在不需要对 Buffer 进行读写 的时候,大家各干各的ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2100
2100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









