





Date:2020-11-23
作者:三弟
来源:GRNet网络:3D网格进行点云卷积,实现点云补全
Gridding Residual Network for Dense Point Cloud Completion
主页:https://haozhexie.com/project/grnet
在点云分割方面,有一些方法尝试通过更通用的卷积操作来捕捉点云的空间关系。但是之前的方法都是基于一个强烈的假设,即输出点与输入点的三维坐标的相同,因此不能用于三维点云补全。
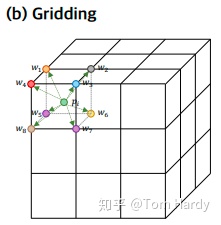
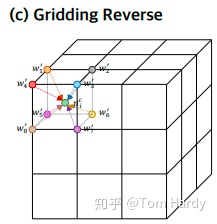
为了解决上述问题,我们引入3D网格作为中间的表征来规范化无序点云,从而明确地保留了点云的结构和背景。因此,我们提出了一种新的点云完成的网格化残差网络(GRNet)。除了3D CNN和MLP,我们设计了三个可微层。Gridding, Gridding Reverse, 和三次特征采样。在Gridding中,对于点云中的每个点,该点所在的三维网格单元的八个顶点先使用插值函数进行加权,该函数明确地测量了几何学上的点云的关系。然后引入了3D网格作为中间表示来规整无序点云,它明确地保留了点云的结构和局部关系。接下来,Gridding Reverse将输出的三维网格转换为粗点云,将每个三维网格单元替换为一个新点,其坐标为三维网格单元八个顶点的加权和。接下来的三次特征采样通过将该点所在的三维网格单元对应的八个顶点的特征进行串联,提取粗点云中每个点的特征。粗点云和特征送入到MLP,得到最终补全的点云。本文的贡献如下。
- 我们创新性地引入了3D网格作为中间表征来规范化无序点云,明确地保留了点云的结构和背景下的点云。
- 我们提出了一种新型的用于点云完成的网格化剩余网络(GRNet)。我们设计了三个可区分的层。Gridding, Gridding Reverse, and Cubic Feature Sampling, as well as a new Gridding Loss.
- 在ShapeNet、 Completion3D和KITTI基准上进行了广泛的实验,结果表明,所提出的GRNet与最先进的方法相比表现良好。
网格残差网络
GRNet 在以粗糙到精细的方式从不完整的点云中恢复完整的点云。 它由五个部分组成,分别是网格化、3D卷积神经网络、反向网格化、立方特征采样和多层感知器,如图1所示。


网格化

3D卷积神经网络

逆网格化

三次特征采样

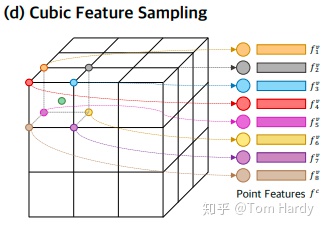
在 GRNet 中,三次特征采样通过 3DCNN 前三个转置卷积层,从特征图中提取点特征。为了减少特征的冗余并生成固定数量的点,我们从粗糙点云 中随机采样2,048个点。所以,它会生成大小为2048×1792的特征图。
多层感知器

网格损失


实验
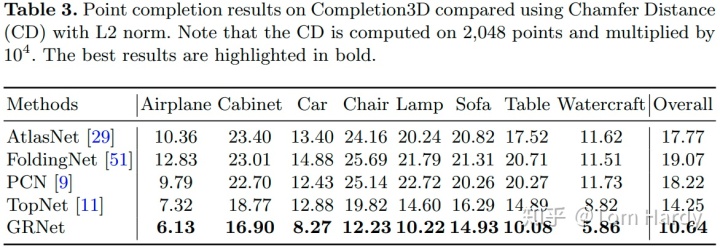
作者在 ShapeNet、Completion3D 和 KITTI 三个数据及分别进行了实验,并且与 PCN 等方法进行了比较。在度量指标上,作者认为只用 Chamfer 距离不能客观的评价补全的点云,事实上 Chamfer 距离在数值上及时较低,预测的点云可能并没有一个很好的分布,因此作者同时考虑了用 F-Score 作为量化指标。
量化指标

数据集
ShapeNet:最初在 ShapeNet 数据集是 PCN 的工作,由来自8个类别的30,974个3D模型组成。真实值在网格表面上均匀采样 16,384个点。部分点云是通过反投影2.5D深度映射到3D。
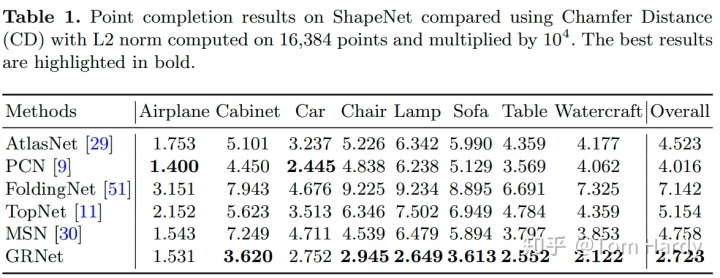
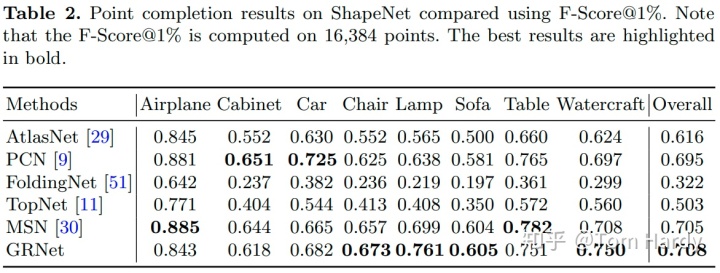
Completion3D:Completion3D 实验机[11]由28,974个和800个样本分别进行训练和验证。与 PCN 方法的ShapeNet 数据集不同的是,真实点云上只有2,048个点。
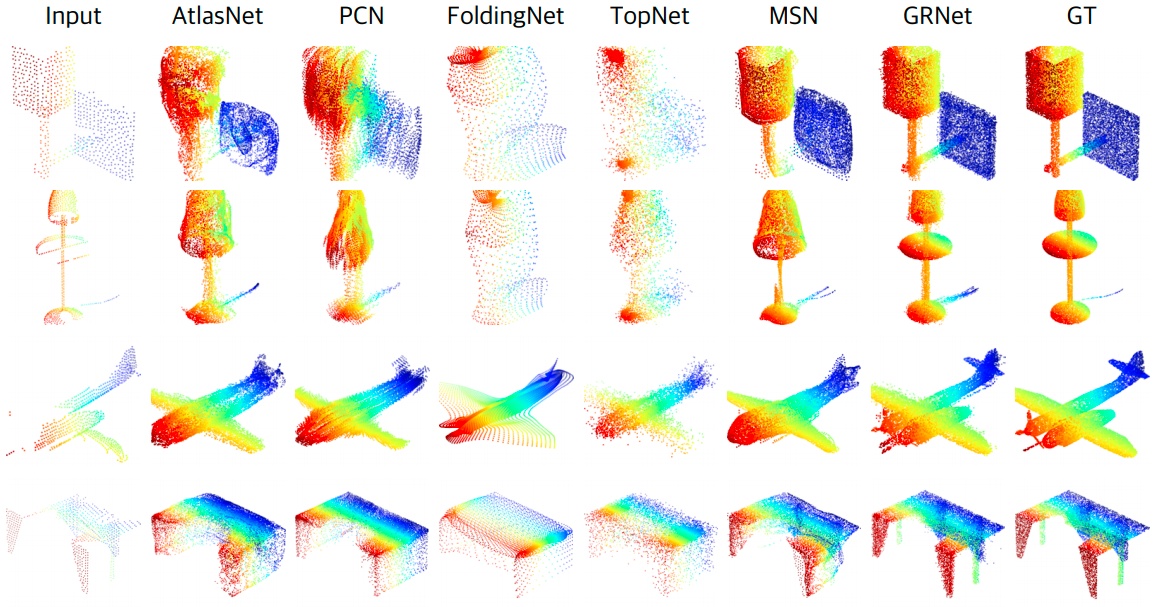
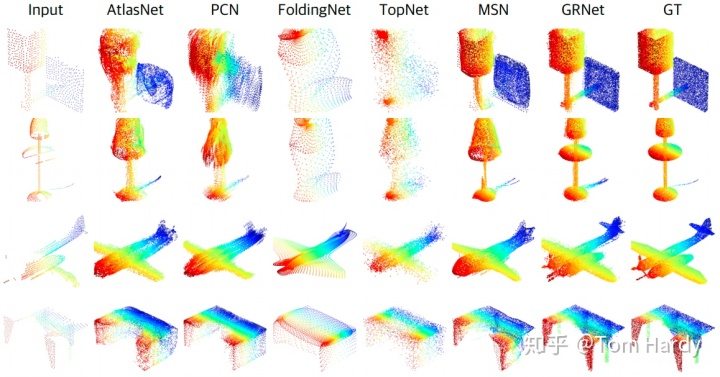
在 ShapeNet 上可视化结果,最左边是输入,最右侧是 Groud Truth,倒数第二列是本文 GRNet 的结果。
KITTI:KITTI 数据集由现实世界的 Velodyne LiDAR扫描序列组成,也是从 PCN 中获得。对于每一帧,汽车是根据3D边界框提取的,从而获得 2,401个局部点云。KITTI中的局部点云非常稀疏,并且不有完整的点云作为真实值。在 KITTI 雷达扫描的可视化结果。

更多干货
欢迎加入【3D视觉工坊】交流群,方向涉及3D视觉、计算机视觉、深度学习、vSLAM、激光SLAM、立体视觉、自动驾驶、点云处理、三维重建、多视图几何、结构光、多传感器融合、VR/AR、学术交流、求职交流等。工坊致力于干货输出,为3D领域贡献自己的力量!欢迎大家一起交流成长~
添加小助手微信:CV_LAB,备注学校/公司+姓名+研究方向即可加入工坊一起学习进步。















 4294
4294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









