






背景
基于计算机视觉、人机交互和深度学习等技术的应用,此前平安人寿重磅推出行业首款多模态合成的视频客服机器人,该视频机器人可实现逼真的语音播报、表情生成和拟人实时对话,目前已应用在保单视频回访中,能够为客户带来拟真视频形象交互、7×24小时在线自助、保单信息即时调阅的“真人服务”临场感。
本文聚焦AI视频机器人项目背后的图像技术,基于虚拟人像生成、文字到唇形生成、图像融合这一实现框架,对该项目中实时视频生成方面的探索与实践进行分享。
项目总体框架
AI视频机器人项目的总体框架如下图所示,此次着重分享与实时视频生成相关的三大模块,即虚拟人像生成,文字到唇形生成和图像融合。
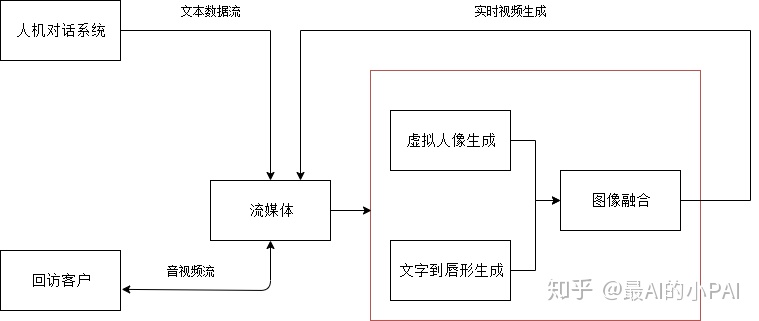
虚拟人像生成
虚拟人像生成主要基于GAN高清图像生成领域的state-of-the-art技术StyleGAN,从非常低的分辨率开始,一步步生成高分辨率的图像,并独立地修改网络中每个级别的输入来控制在该级别中所表示的视觉特征,完成低级别的粗糙的特征(姿势、面部形状)到高级别的精细的细节(头发颜色)的实现。
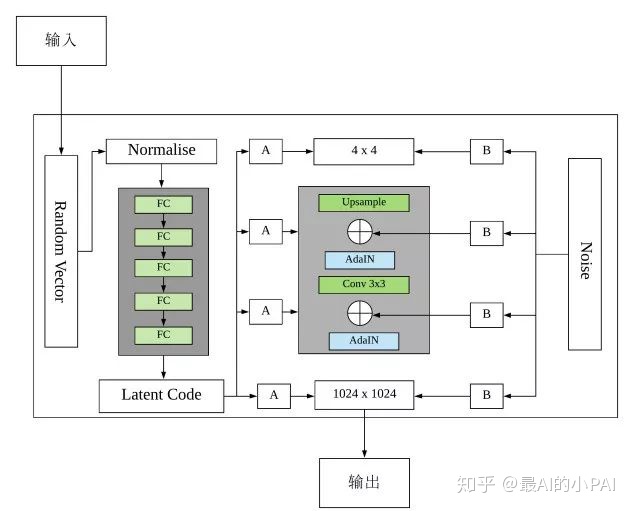
StyleGAN的网络框架如上图所示,区别于传统GAN网络,StyleGAN直接使用随机向量作为输入以生成图片。
StyleGAN通过一个8个全连接层组成的映射网络将随机向量编码为“风格“向量ⱳ,以制不同的视觉特征,因为使用输入向量来控制视觉特征的能力是非常有限的,它必须遵循训练数据的概率密度。例如,如果黑头发的人的图像在数据集中更常见,那么更多的输入值将会被映射到该特征上。因此,该模型无法将部分输入(向量中的元素)映射到特征上,这一现象被称为特征纠缠。而通过引入映射网络,模型整体可以生成一个不必遵循训练数据分布的向量,并且可以减少特征之间的相关性。
这个“风格“向量ⱳ,会经由AdaIN(自适应实例标准化)模块,转移并整合到生成网络的每一个块中。AdaIN模块会先将卷积层输出的每个通道标准化,然后加入ⱳ作为偏置项。这样可以保证w’只影响图片的全局信息,生成人脸的关键信息仍由上采样层和卷积层来决定。
与之类似的是噪声的添加机制,StyleGAN在AdaIN模块之前向每个通道添加一个缩放过的噪声,以稍微改变其操作的分辨率级别特征的视觉表达方式,达到定向控制随机变化的影响。也正因为新引入的这些特性,StyleGAN取代了传统的输入格式,并将每次生成网络的输入固定为统一常量。

我们对StyleGAN的超参数进行调整,并在更适合的训练集上训练以生成更符合中国人审美的高清人像,同时引入语义编辑的概念,对StyleGAN随机生成的人像加以固定和约束,摆脱GAN模型缺乏用户控制的通病,以便得到同一人像的更多图片供后续使用。另一方面,通过将参数缩放的操作嵌入卷积层,取代了传统的线性计算操作,使计算可并行化,进而缩短了30%的训练时间。
文字到唇形生成
归纳来看,已有从文字到唇形生成的技术可以拆分成以下三个步骤:
- 文字转语音
- 语音与唇形匹配
- 唇形重建
目前文化领域内较为成熟的框架ObamaNet,通过3个独立网络分别完成上文提到的三个步骤,如下图所示。
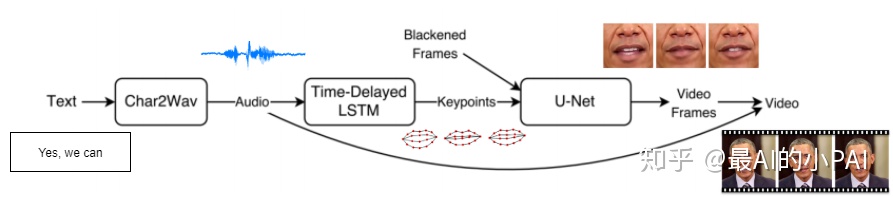
其首先利用Char2Wav模型将文本直接转换成相应的音频,再将得到的音频作为输入传入语音和唇形匹配模型。此模型首先从原始音频中提取特征参数MFCC(Mel-scaleFrequency Cepstral Coefficients),并作为输入传入一个延时LSTM的网络结构。这个网络的目的是学习从音频到唇形特征点的直接映射关系。先使用PCA降维的方法将网络的预测值去相关化,只保留最关键的18个特征点作为唇型的特征轮廓。同时为了避免图像大小、面部位置、面部旋转、面部大小等因素对预测的唇形的影响,将这些特征点归一化后再作为第二阶段的最终输出。最后,通过在图像翻译领域取得成功的Pix2Pix模型,根据特征点轮廓生成相应的唇形输出。
下图展示了Pix2Pix的工作原理,生成器G根据原始输入生成相应的唇形并试图骗过判别器D,而判别器D将判断生成的唇形与轮廓组合是否可以与真实的唇形和相应轮廓组合区分开来。

此项目的构建框架也遵循这一设计理念,但区别与现有文字到唇形合成的实现,如ObamaNet、Text-based-editing,将每个步骤独立开,我们率先提出了一个端到端的模型,从而避免了整体结果对每一个独立模型结果好坏的过度依赖。同时也进一步提高框架的实时性、唇形匹配准确率和最终生成图像的分辨率。
在优化实时性方面,主要选用轻量化的网络结构,通过减少参数量和网络深度对模型进行压缩。目前主流衡量模型加速效果的指标是FLOPs(float-point operations),这个指标主要衡量的是卷积层的乘法计算量,而在不改变特征图大小的情况下,这一计算量与参数量成正相关。 通过对模型的压缩进一步实现了对速度的提升,同时在多GPU环境下节省了约60%的训练时间和33%的内存占用。另一方面,内存访问消耗时间(MAC)也是影响整体计算速度的。此项目借鉴了ShuffleNet V2 一文中提到的相关概念来设计网络结构,归纳总结为以下四点:
- 卷积层的输入和输出特征通道数相等时MAC最小,此时模型速度最快
- 过多的分组卷积操作会增大MAC,导致模型速度下降
- 网络结构的碎片化程度越低,模型速度越快
- Element-wise的操作越少,模型速度越快
在优化生成唇形分辨率方面,引入Pix2PixHD的理念,通过分阶段的方式生成高分辨率、高质量的图片。将生成器G拆分成多个子生成器,Gi-1生成结果和更高分辨率的图像将作为Gi 的输入已得到更高分辨率的生成图像。为了区分高分辨率的生成图像而不影响模型整体的实时性,我们使用多个具体有相同网络结构的判别器对不同尺寸的图像进行操作,从而避免了采用因判别高分辨率图像所需的更大的感受野所带来的网络结构加深或卷积核扩增的操作。同时,在loss设计方面减少了现有技术在计算loss时对element-wise操作的依赖。
最终,相较于原来512*512分辨率的图像输出,优化后的模型可以实时的输出2k(2049*1024)分辨率级别的图像,提供了高清的人脸及唇部细节。
图像融合
主流的人脸融合算法大致可以分为三步:特征点检测、人脸对齐和人脸融合。
特征点检测
人脸特征点检测即通过训练好的模型识别如眉毛、眼睛、鼻子、嘴巴、脸部轮廓等关键特征点,并获得相应坐标值。
如下图所示,左边的图片是检测出的68个人脸特征点,右边的是扩充了额头区域的81个人脸特征点。特征点数量的增加和精细化程度的提高,有助于更准确地获取所需要的人脸信息,如脸型大小,五官比例等。
目前人脸特征点检测的发展趋势是在保证实时检测的速度的基础上,提高可检测特征点的数量和精度对五官和脸部轮廓进行精确定位,即完成从点到线的转变。

人脸关键点检测方法大致分为三种:
- 基于模型的ASM(Active Shape Model)和AAM(Active Appearnce Model)
- 基于级联形状回归CPR(Cascaded pose regression)
- 基于深度神经网络的方法
此项目采用的是基于“One Millisecond Face Alignment with an Ensemble of Regression Trees”中提出的Ensemble of Regression Tress算法(以下简称 ERT)的人脸特征点检测的优化实现。
ERT是一种基于回归树的人脸对齐算法,这种方法通过建立一个级联的残差回归树来使人脸形状从当前形状一步一步回归到真实形状。每一个残差回归树的每一个叶子节点上都存储着一个残差回归量,当输入落到一个节点上时,就将残差加到该输入上,起到回归的目的,最终将所有残差叠加在一起,就完成了人脸特征点检测的目的。
人脸对齐
获取到人脸特征点信息后,可以通过脸部轮廓的坐标截取相应的人脸区域,也可以根据需要截取相应的五官的特征,如此项目中关注的唇部区域,并最终自然的融合到目标图像上的相应位置。在真正开始融合之前,仿射变换是很重要的先决条件,通俗的来讲,需要通过一系列的变换操作,把感兴趣的区域与目标人脸中相应的区域对齐到同样的大小和角度。
这一系列的变化包括缩放,平移,旋转,反射,错切,而经过变化的图像需要保持如下的性质才能称之为仿射变换:
- 凸性:变换前集合具有凸性,在变换后仍保持凸性
- 共线性:若几个点变换前在一条线上,则仿射变换后仍然在一条线上
- 平行性:若两条线变换前平行,则变换后仍然平行
- 共线比例不变性:变换前一条线上两条线段的比例,在变换后比例不变
为了得到更好的图像变换效果,避免扭曲和失真,此项目使用了Delaunay 三角剖分算法来完成对人脸的对齐。
三角剖分,即给定一个平面和其上的若干点,通过某种形式的连接点,把平面切分成若干三角形。Delaunay 三角剖分定义了一种特别的三角剖分方式,对于两个共边的三角形,任意一个三角形的外接圆中都不能包含有另一个三角形的顶点(空园特性),同时这种形式的剖分可以产生最大的最小角(最大化最小角特性)而避免“瘦小“三角形的出现。
一旦得到根据特征点建立的Delaunay 三角网格,对每个三角形进行上文提到的仿射变换操作,以此得到最终对齐后的人脸图片。

人脸融合
在对图像进行合成的过程中,为了使合成后的图像更自然,合成边界应当保持无缝。但如果原图像和目标图像有着明显不同的纹理特征,则直接合成后的图像会存在明显的边界。
为了减少边界差异,此项目采用了“Poisson Image Editing”一文中提出的泊松图像编辑(又称泊松融合)的实现,即一种利用构造泊松方程求解像素最优值的方法。该方法根据用户指定的边界条件求解一个泊松方程,实现了梯度域上的连续,从而达到边界处的无缝融合。
总结来讲,泊松融合的主要思想是,根据源图像的梯度信息以及目标图像的边界信息,利用插值的方法重新构建出合成区域内的图像像素,从而达到在保留了源图像梯度信息的同时,可以很好的融合源图像与目标图像的背景。换句话说,泊松融合通过找到是边界处梯度变化最小的值,然后利用泊松方程反向计算出相应点的像素值,以达到无缝融合两个图像的目的。

如上图所示,蓝线代表图像S的梯度,红线代表图像g的梯度,直接用g的梯度覆盖原有的梯度会导致梯度不连续,而通过泊松融合处理后的梯度可以确保整体的连续性。
以泊松图像编辑的处理方式,此项目将生成的唇形无缝的融合到生成的虚拟形象上并得到最终的形象。
总结
基于AI视频机器人项目的实践经验,未来我们期望继续朝以下目标进行探索迈进:
- 尝试更自然且细节更加真实的图像生成技术,并对生成的图像进行可控制的修饰
- 尝试端到端且实时的文字到唇形生成的模型
- 尝试更轻量化且更精准的人脸融合算法
总的来看,AI视频机器人项目的积累为我们日后生成更自然逼真的虚拟形象打下基础。随着技术的不断优化与迭代,相信视频机器人将可以应用在寿险业务的更多场景中。
Reference:
[1] Kazemi, Vahid, and Josephine Sullivan. "One millisecond face alignment with an ensemble of regression trees." Proceedings of the IEEE conference on computer vision and pattern recognition. 2014.
[2] Pérez, Patrick, Michel Gangnet, and Andrew Blake. "Poisson image editing." ACM Transactions on graphics (TOG) 22.3 (2003): 313-318.
[3] Radford, Alec, Luke Metz, and Soumith Chintala. "Unsupervised representation learning with deep convolutional generative adversarial networks." arXiv preprint arXiv:1511.06434 (2015).
[4] Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., ... & Bengio, Y. (2014). Generative adversarial nets. In Advances in neural information processing systems (pp. 2672-2680).
[5] Karras, Tero, Samuli Laine, and Timo Aila. "A style-based generator architecture for generative adversarial networks." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
[6] Suwajanakorn, Supasorn, Steven M. Seitz, and Ira Kemelmacher-Shlizerman. "Synthesizing obama: learning lip sync from audio." ACM Transactions on Graphics (TOG) 36.4 (2017): 95.
[7] Kumar, R., Sotelo, J., Kumar, K., de Brébisson, A., & Bengio, Y. (2017). Obamanet: Photo-realistic lip-sync from text. arXiv preprint arXiv:1801.01442.
[8] Isola, P., Zhu, J. Y., Zhou, T., & Efros, A. A. (2017). Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1125-1134).
[9] Wang, T. C., Liu, M. Y., Zhu, J. Y., Tao, A., Kautz, J., & Catanzaro, B. (2018). High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 8798-8807).
[10] Shen, Y., Gu, J., Tang, X., & Zhou, B. (2019). Interpreting the latent space of gans for semantic face editing. arXiv preprint arXiv:1907.10786.
[11] Fried, O., Tewari, A., Zollhöfer, M., Finkelstein, A., Shechtman, E., Goldman, D. B., ... & Agrawala, M. (2019). Text-based Editing of Talking-head Video. arXiv preprint arXiv:1906.01524.















 4227
4227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









