






词性标注器
词性标注器(POS tagger)的作用是给文本的每个单词赋予一个词性(POS, Part Of Speech).词性可以提供关于所在词和上下文的信息.比如动词后一般跟名词.词性信息可以帮助语法分析或者命名实体识别等.
序列标注
在这里,文本被看作词的序列,而每个词被赋予词性则是获得标注.所以词性标注器也是序列标注的一个例子.
建模
所谓建模就是用数学的语言来描述一个系统,用来解释系统运行机制,分析各种因素的影响以及做预测.
词性标注建模
给定一个文本,也就是一个词序列
我们求
也就是该组词下,出现概率最大的一组POS tags.
根据贝叶斯法则,
这样的话,词性标注问题就变成了一个概率问题.而分母
为了简化问题,我们扔掉分母,最大化
HMM(Hidden Markov Model)隐马模型
HMM对上述问题进行了两个方面的简化,
1. tags序列的一阶markov性,也就是第i个tag的概率只依赖于第i-1个tag.那么
2. 观测独立性,也就是每个
-
叫做emission(溢出概率),表示给定一种POS tag生成一个词的概率;
-
叫做transition(转移概率),表示给定前一个词的词性,后一个词词性的概率分布
动态优化
动态规划是用来解决具有最优子结构(大规模问题的最优解由形式完全一样的小规模问题的最优解组成)的问题.相比于简单的归纳法,动态规划储存了小规模问题的最优解,避免了解决大规模问题时反复计算同一小规模问题.
在词性标注中,第1个词到第t个词的词性标注就是规模为t的问题,该问题最优解就是
Viterbi算法--求隐马模型的动态规划方法
隐马模型赋予每个词性标注序列一个"概率"(加双引号是因为我们去掉了归一化函数,并不是真正意义的概率).基于这个概率,我们需要求出概率最大的词性标注序列.
用运筹学的语言来表述,每个词性标注序列都是一种可能的解,每个解都对应一个数值(这里是"概率").我们需要求出最大化该数值的解.
Viterbi算法由Andrew Viterbi在1967年提出,用动态规划的方法来解决这个优化问题.我们可以借助小规模问题的最优解来获得大规模问题的最优解(我们最关心的规模为l的问题的最优解).
我们用一个表(也就是dynamic programming中programming的最初意义)来记录从第1个词开始,每种词性标注序列的概率.如
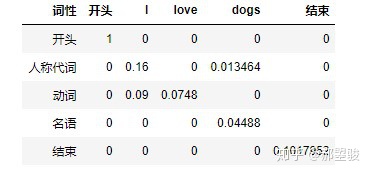
第i行j列的节点记录了第j个词为i词性时的最优词性标注路径(包含了j词前面词的词性序列)上上一个词的词性,黑体字表示了句子的最优词性标注序列
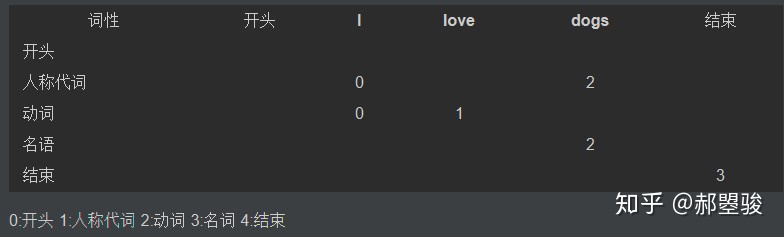
所以end节点就储存了所有词(所有词都在end词前)的最优词性标注路径.这里最优指的是隐马模型下词性标注序列的概率.
我的代码实现中用两个矩阵,命名为Viterbi和path,来分别记录概率(隐马模型下词性标注序列的概率)和最优解(词性标注序列)
Viterbi(i, t)记录了限定第t个词为i词性,规模为j的词性标注问题的最优解对应的概率.代表第t个词为i词性时,前t个词的词性标注序列的最优解的值.通过迭代来实现:
用path(i,t)来记录第t个词为i词性时,前t个词的词性标注序列的最优解中第t-1个词的词性.一步步回溯,我们就可以获得这个最优解.
为了从后向前获得整个句子的最优词性标注序列,
- t=l,
,也就是从第1个词到最后1个词,概率最大时最后一个词的POS tag.
就是最后一个词的POS tag,
-
.从最后一个词的POS tag来追溯使得它概率最大的倒数第二个词的POS tag.
就是倒数第二个词的POS tag
- t = t-1,
- 重复2,3步,直到得到所有词的POS tag
代码实现
"""
Created on the 13th June 2018
@author : woshihaozhaojun@sina.com
"""
import numpy as np
def viterbi_algo(text, transition, emission, ind2tag, word2ind ):
"""
pos tagger的viterbi算法
Args:
text(iterables) :- 要估计的句子的序列,长度为l
transition(np.array) :- 词性转换矩阵,
[i,j]元素表示从i词性到j词性的概率,
维度为[K ,K], K为词性的种类数
emission(np.array) :- 产生词的概率矩阵,
[i,k]元素表示i词性生成k词的概率,
维度为[K, v], v为字典的大小
ind2tag(iterables) :- 第i个元素为i词性
word2ind(dict) :- k词为key,序号为value
Returns:
paths(np.array) :- [i,w]元素表示第w词为i词性时上一个词的词性,
维度为[n, l]
viterbi(np.array) :- [i,w]元素表示第w词为i词性的概率,
维度为[K,l]
"""
try:
assert transition.shape[0] == transition.shape[1]
except AssertionError:
print("转移矩阵不是方阵")
try:
assert transition.shape[0] == emission.shape[0]
except AssertionError:
print("emission矩阵的行数和词性数不一致")
try:
assert len(ind2tag)==transition.shape[0]
except AssertionError:
print("ind2tag长度和词性数不一致")
cols = len(text)
rows = transition.shape[0]
paths = np.zeros(( rows, cols))
viterbi = np.zeros((rows, cols))
viterbi[0,0] = 1
for j in range(1,cols):
for i in range(rows):
prob = viterbi[:,j-1] * transition[:,i]* emission[i, word2ind[ text[j]] ] # [cols, 1]
sort = np.argsort(prob)
paths[i,j] = sort[-1]
viterbi[i,j] = max(prob)
last = int(np.argsort(viterbi[:, j] )[-1]) # 最后一个词的概率最大的行序
print(f"词为{text[-1]}, 词性为{ind2tag[last]}, 概率为{viterbi[last, j]*100}%")
for j in range(cols-1):
last = int(paths[last, cols-1-j]) # 上一个词的行序
print(f"词为{text[-2-j]},词性为{ind2tag[last]},概率为{viterbi[last,cols-2-j]*100}%")
return paths, viterbi
def demo():
text = ['b', 'I', 'love', 'dogs', 'e']
ind2tag = ['b', 'rr', 'v','n', 'e'] # 开头,人称代词,动词,名词
transition = np.array(
[
[0, 0.4, 0.2, 0.4, 0], # 从b到 rr, verb, noun, e
[0, 0, 0.85, 0.1, 0.05],
[0, 0.3, 0, 0.6, 0.1],
[0, 0, 0.6, 0, 0.4],
[0, 0, 0, 0, 0]
]
)
emission = np.array(
[
[1, 0 , 0, 0, 0],
[0, 0.4, 0, 0.6, 0],
[0, 0.45 , 0.55 , 0, 0],
[0, 0 , 0 , 1, 0],
[0, 0 , 0 , 0 , 1]
]
)
word2ind = {
'b' : 0,
'I' : 1,
'love' :2,
'dogs' : 3,
'e' :4
}
paths, viterbi = viterbi_algo(text, transition, emission, ind2tag,word2ind)
print(viterbi)
print(paths)
if __name__ =="__main__":
demo()效果















 410
410











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









