









最近看了篇使用transformer进行底层图像处理任务的工作Pre-trained image processing transformer,这里分享一下。
这篇文章使用ImageNet数据集和transformer结构训练出一个专门用于底层图像分处理任务的预训练模型image processing transformer (IPT),在执行具体任务时只需要微调head和tail就可以处理自己的任务,同时还引入了对比学习用于模型适应不同任务。文中对去噪、超分辨和去雨都进行了实验对比,均获得SOTA效果。下图的对比显示在超分辨任务上对于原图2倍、3倍、4倍下采样的数据上较HAN均提升了0.4dB,在去噪上在原图分别添加30和50的高斯噪声等级上较RDN分别提升2.0dB和1.8dB,去雨上较RCDNet提升了1.6dB。

本文主要工作在于:1.使用ImageNet数据集作为benchmark,通过各种手段对原始的高分辨率图像进行有损处理,获得相应任务的数据集(例如超分辨任务进行下采样,去噪任务认为加入噪声),最终整个用于预训练的数据集高达一千万张图片;2.使用multi-head和multi-tail,包含去噪、超分辨和去雨,在迁移至自己任务时只需对这些head和tail进行微调;3.训练输入将原始图片切为多个patch进行训练,编码器和解码器分别加入position embedding和task embedding,其中task embedding用于会进行学习适配各种任务;4.引入对比损失来评估不同图的patch之间关系,以适应各类图像处理任务。
模型结构
模型结构如下图。

整个模型主要有三部分:1.multi-head:用于提取输入图像特征;2.transformer用于恢复图像损失信息;3.multi-tail:将transformer输出的特征恢复为图像。
Heads:使用不同head处理不同任务,每个头包含3个卷积层,得到通道数为C的feature map(作者这里C设置为64),分辨率保持不变,这个过程可以用![]() 来表示,其中
来表示,其中![]() 表示第i个任务的head(每个head包含3个卷积层,3×3的卷积核,以及2个残差块,每个残差块包含2个卷积层,5×5的卷积核,输入输出通道数相同),i的总数量是
表示第i个任务的head(每个head包含3个卷积层,3×3的卷积核,以及2个残差块,每个残差块包含2个卷积层,5×5的卷积核,输入输出通道数相同),i的总数量是![]() ,也就是
,也就是![]() 个任务。
个任务。
Transformer encoder:这一步将feature map送入输入之前首先要将原图切分为长度为P的patch,即![]() ,每个patch可以看做是word,这样就会将每张图C个通道的feature map切为一序列的patch。此外还添加了可学习的位置编码
,每个patch可以看做是word,这样就会将每张图C个通道的feature map切为一序列的patch。此外还添加了可学习的位置编码![]() ,尺寸和patch保持一致都是宽×高×通道数,位置编码的添加直接通过相加的方式得到,即
,尺寸和patch保持一致都是宽×高×通道数,位置编码的添加直接通过相加的方式得到,即![]() ,得到的值直接送入编码器。编码器的结构没有做改变,和经典的transformer结果保持一致,它的输出尺寸和输入保持一致。整个编码器部分的计算表示如下:
,得到的值直接送入编码器。编码器的结构没有做改变,和经典的transformer结果保持一致,它的输出尺寸和输入保持一致。整个编码器部分的计算表示如下:

其中l表示编码器的层数,MSA即多头注意力,FFN采用2层全连接层。LN就是Linear Flatten。最终使用了12层编码器。
Transformer decoder:解码器结构和经典transformer基本保持一致,不同之处是除了编码器输出作为输入之外,额外的输出使用的是task-specific embedding,尺寸也是![]() ,i表示的就是第i种任务,t表示该变量是task embedding。task-specific embedding也是可以学习的(但是并不知道使用什么方式初始化,论文中好像也没说,可以看源代码,下面有链接),用于对不同任务的feature进行解码,直接和Linear Flatten之后的值相加。解码器整个过程使用下面的方式进行:
,i表示的就是第i种任务,t表示该变量是task embedding。task-specific embedding也是可以学习的(但是并不知道使用什么方式初始化,论文中好像也没说,可以看源代码,下面有链接),用于对不同任务的feature进行解码,直接和Linear Flatten之后的值相加。解码器整个过程使用下面的方式进行:

这里的![]() 是解码器的直接输出,N个patch重新组合成与编码器输入尺寸相同的feature map。最终使用了12层解码器。
是解码器的直接输出,N个patch重新组合成与编码器输入尺寸相同的feature map。最终使用了12层解码器。
Tails:和heads的作用类似,使用多个tail处理多种任务,过程可以用![]() 来表示。最终的
来表示。最终的![]() 的通道数重新被调整为3,也就是RGB通道,但是分辨率不一定,去噪和去雨和原始图像尺寸相同,但是超分辨任务中显然和最开始的输入图像尺寸不同。去噪和去雨模块的tail使用的是3个卷积层,3×3的卷积核。超分辨任务中的tail包含带有上采样的pixelshuffle层,2倍和3倍降采样任务中使用2倍和3倍上采样,4倍降采样任务中使用2个2倍上采样的pixelshuffle层。
的通道数重新被调整为3,也就是RGB通道,但是分辨率不一定,去噪和去雨和原始图像尺寸相同,但是超分辨任务中显然和最开始的输入图像尺寸不同。去噪和去雨模块的tail使用的是3个卷积层,3×3的卷积核。超分辨任务中的tail包含带有上采样的pixelshuffle层,2倍和3倍降采样任务中使用2倍和3倍上采样,4倍降采样任务中使用2个2倍上采样的pixelshuffle层。
预训练
预训练使用ImageNet作为benchmark,在这个数据集的基础上使用多种方式生成各类任务中训练集对应的有损图像。ImageNet包含了1000个类别的一百万张图片,处理过程中首先去除语义标签,再用各种方式生成每个任务的图像数据集,这些过程可以用![]() 表示,例如超分辨任务使用bicubic降采样生成低分辨率的图片数据集,去噪任务给原始图像添加不同等级的高斯噪声,去雨任务添加人工设计的雨线,即
表示,例如超分辨任务使用bicubic降采样生成低分辨率的图片数据集,去噪任务给原始图像添加不同等级的高斯噪声,去雨任务添加人工设计的雨线,即![]() ,
,![]() 表示高斯噪声或者雨线。输入图像作为groundtruth即可,所以损失值可以表示为:
表示高斯噪声或者雨线。输入图像作为groundtruth即可,所以损失值可以表示为:
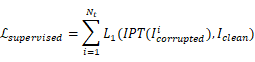
损失函数就是传统的L1损失。上式表明IPT模型可以同时训练多种任务的数据,因此作者训练时采用的策略是对于每一批batch,随机选择一种任务进行训练,并且根据相应的任务来更换head、tail、task embedding。完成整个预训练后只需要进行微调就可以进行其他任务了。微调过程中可以删除与本任务无关的head和tail以节约算力,只更新和任务相关的参数。
不过底层图像处理任务种类太多了,光是去噪就有无数中噪声等级的数据,实在没法给每种任务都生成一个数据集,需要想办法加强IPT的泛化性能。前面说过编码器输入这里要先把原图切成很多patch,把这些patch可以看做word,和NLP一样,这些patch之间的信息也是很丰富的,比如说同一个feature map得到的patch就更接近,于是引入了对比学习,用于最小化同一张输入图片之间patch之前的距离,最大化不同输入图片之间patch的距离,学习全局通用特征以适应各种各样的任务。对比学习的损失函数可以用下式表示:

其中,![]() 是每个batch第j张图片得到的解码器输出,
是每个batch第j张图片得到的解码器输出,![]() 表示余弦相似性。为了充分利用监督和半监督信息,整个IPT模型最终使用的损失函数如下:
表示余弦相似性。为了充分利用监督和半监督信息,整个IPT模型最终使用的损失函数如下:
![]()
实验部分
实验分为两个模块,第一个模块是各个子任务中,在超分辨、去噪都是SOTA结果,第二个模块是消融实验,验证了大数据集上transformer进行图像处理都比CNN要优异。
数据集以及处理方法前面都说过,在去雨这方面用的是Joint rain detection and removal from a single image with contextualized deep networks这篇文献中的方法。将原图切为48×48的patch时每个patch之间有10像素的重叠。优化函数使用adam,对训练参数细节感兴趣的可以直接看原文。因为引入对比学习,所以不同任务的训练过程可以同时进行,作者这里就让每个batch的图片包含各种任务的训练图片预训练结束后再进行微调。
超分辨这里和狠多SOTA模型在2、3、4倍降采样分别进行了对比,结果很不错,可以看下表。此外IPT在图像纹理和结构信息上也更优异,其他狠多方法都会导致模糊。


去噪在BSD68和Urban100上作为测试集进行了测试,在各个高斯噪声等级上都达到了SOTA结果,Urban100上的结果比之前的SOTA提升了2dB。小猫图中也能看出细节方便更好。


去雨在Rain100L数据集上进行了测试,结果喜人,如表和图所示。


泛化性能方面,作者采用的是ImageNet数据集中图片添加等级为10和70的高斯噪声后进行测试,结果如下表,相比如其他方法还是最好的,说明IPT可以从大数据集中捕捉更多有效信息和特征。

消融实验分别评估了数据集规模和损失函数中超参数λ![]() 的影响。数据集规模这里对比了CNN-based模型和transformer-based模型在不同数量训练样本上的影响。CNN模型选用EDSR作为CNN的baseline,训练样本数量分别取上述处理后ImageNet数据集的20%、40%、60%、80%和100%作为子数据集来分析,下图是实验结果,在小于60%时CNN效果较好,在60%后transformer的效果超过了CNN。超参数λ
的影响。数据集规模这里对比了CNN-based模型和transformer-based模型在不同数量训练样本上的影响。CNN模型选用EDSR作为CNN的baseline,训练样本数量分别取上述处理后ImageNet数据集的20%、40%、60%、80%和100%作为子数据集来分析,下图是实验结果,在小于60%时CNN效果较好,在60%后transformer的效果超过了CNN。超参数λ![]() 的实验在超分辨任务中的Set4数据集2倍降采样数据上进行实验,结果如下表。
的实验在超分辨任务中的Set4数据集2倍降采样数据上进行实验,结果如下表。


最后作者还对task embedding进行了可视化,发现每个位置和它相邻位置task embedding的相似性,2倍降采样的相似性高于3倍,3倍也高于4倍,作者认为这是由于2倍降采样每个位置之前的距离要小于3倍和4倍,patch之前的相似性更高。去雨任务中,task embedding之间的相似性表明patch在垂直方向的注意力高于水平方向,这是因为雨流方向基本是竖直方向。去噪任务中task embedding之间的相似性类似于高斯噪声的分布。整体来说模型学到了不同任务中的信息。后来也试了下不用task embedding的效果,准确率显著下降,不同任务的下降幅度从0.1dB到0.5dB不等。
此外还对位置编码进行了可视化,发现处在相同行列的位置编码具有更高的相似性,说明学到了有效的位置信息,也对比了不用位置编码或者不学习的固定位置编码方式,发现效果也下降了,不同任务中从0.2dB到0.3dB不等。
最最后做了多任务的实验,也就是上述6种任务一起,结果不受影响。不过在用于其他图像处理任务中(例如等级为10和70高斯噪声任务),多任务训练结果比单任务的高0.3dB,说明多任务学习更能学习到通用特征。
作者也给出了代码:
GitHub:https://github.com/huawei-noah/Pretrained-IPT
Gitee:https://gitee.com/mindspore/mindspore/tree/master/model_zoo/research/cv/IPT
最新的一个综述Transformer in Vision: A Survey中介绍了更多使用transformer进行底层图像处理任务的模型,感兴趣的可以去看这篇综述。















 6908
6908











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









