






上一篇文章讨论了μ±3σ统计分析的限制前提:正态分布。本篇将继续讨论限制μ±3σ统计分析方法的另一个因素:样本量。
1 案例
某原料药中间体含量(%,限度96.5-103.5)统计数据如下:

首先进行正态判定,结果显示:不能拒绝正态。
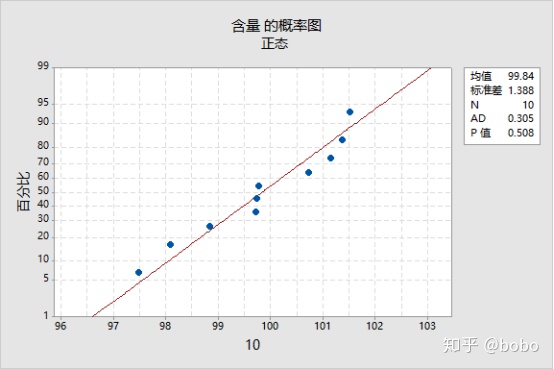
然后进行μ±3σ分析,结果显示:所有数据均在μ±3σ计算的控制限度内,但控制下限低于规格限度,NO PASS!
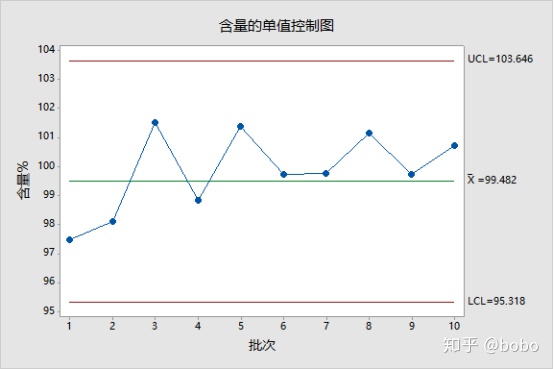
随着时间的推移,生产批次不断增加,继续统计数据并进行μ±3σ分析,结果显示:所有数据均在μ±3σ计算的控制限度内,且控制限度低于规格限度,PASS!

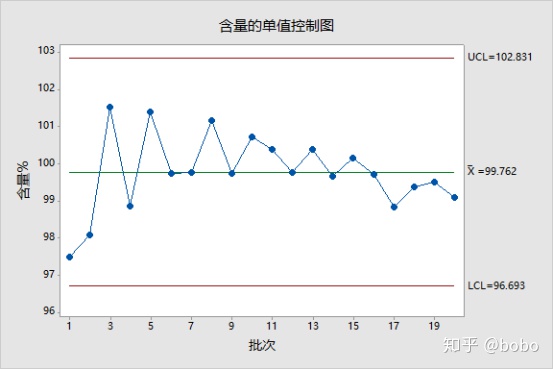
增加样本数量至30,再次进行分析,结果显示:数据均在μ±3σ计算的控制限度内,且控制限度低于规格限度, PASS!

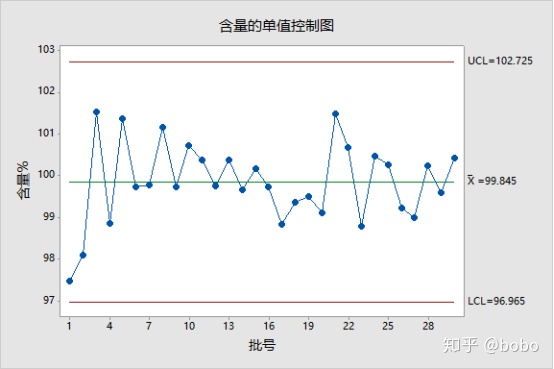
2 WHY
数据均为正态,怎么又出现了不同的结论!
现在,回到问题的本质。
2.1 定性-点估计
上述案例实际采用的是控制限
对于正态总体,用
用s估计σ的标准差
可见,n越大,σ越小,对控制限度估计精度越大,越可信。
2.2 定量-边际误差
公式1~2中,包含参数σ未知,而σ从样本数据中是得不到的。如果以s代替σ计算,该如何解释呢,幸运的是,边际误差[1]解决了这一问题。
总体均值u估计的边际误差
总体标准差σ估计的边际误差
可见:n越大,s越小,边际误差越小,控制限估计精度越大,越可信。
2.3 样本量n=30
传统的大样本“n=30”就足够了吗?
对于正态总体,置信水平均为0.95,根据公式3~4计算的总体均值和标准差的双侧置信区间的边际误差数据如下:
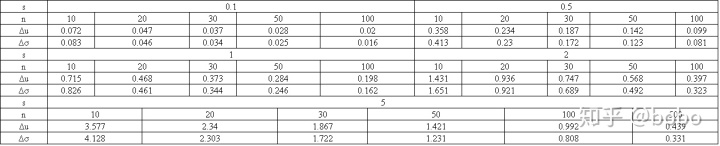
表中数据显示:如果s=5.0,n=30,对应的均值和标准差的边际误差分别为1.867和1.722,显然在中间体含量的控制限度估计上,将出现较大的误判率。
3 HOW
n越大,越可信,那么取多大样本量估计是合适的?
对于“老”产品,可以采用稳定生产的同一生产线历史均值和标准差作为μ和σ的估计,进行μ±3σ分析。
对于“新”产品,可以通过初步的推测或之前的试验研究,得到标准差的推测值,根据能够接受的产品质量属性和工艺属性的误差接受程度[2]选择合适的样本量。
在考虑提高精度的时候,应兼顾样本量和成本之间的平衡关系。
4 小结
μ±3σ分析进行正态判定后,还应选择合适的样本量。
样本量n=30仅为经验数值,如果标准差很大,统计分析将出现较大的误判率。
同一总体,n越大,控制限估计精度越大,越可信,但成本控制必须在视野之内。
参考
- ^对于双侧置信区间,边际误差为估计统计量与每个端点之间的距离
- ^一般来说,杂质、含量、收率等接受程度依次变大















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









