







前面我们讲了在随机化分组过程中,各处理组的分组概率可以相等的情况,但也可以在设计上两组样本例数不等的情况,如有时候临床上出于某些原因,如安全性、医学伦理、试验组可能入组困难等可以按1:2或1:3乃至于1:4等情况进行分组。
当主要评价指标为定量资料,且两样本含量不相等时(两样本含量之比为:n1:n2=1:k),则两样本均数差异性比较的样本含量估计主要计算公式:
单侧:
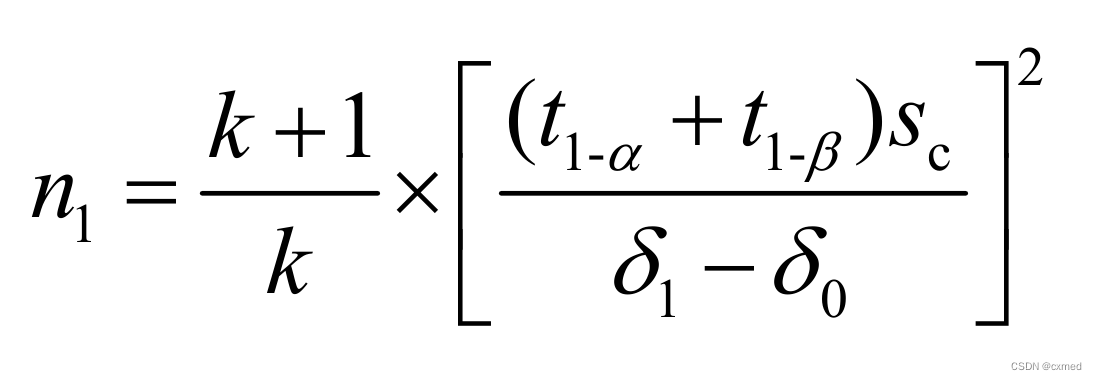
双侧:
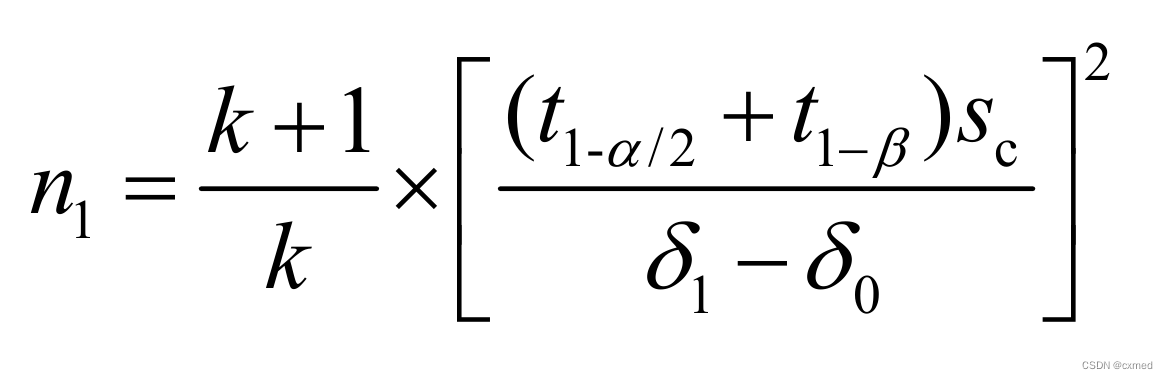
公式中δ0为零假设时两总体均数之差,δ1为备择假设时两总体均数之差,Sc为公共标准差;t1-α、t1-β、t1-α/2都是自由度(n1+n2-2)下的分位数,在n1和n2求出之前,t1-α、t1-β、t1-α/2都无法确定,需要用迭代法解方程。
本节主要讲解采用PASS15软件实现完全随机设计两样本含量不相等时两均数比较的样本含量估计。
例:某研究者欲分析多毛症患者与正常人的血清睾丸酮含量(ng%)是否有差别。指定无效假设H0:μ1-μ2=δ0=0;备择假设H1:μ1-μ2=δ1=10。根据其他研究者资料得知血清睾丸酮含量的标准差为13.33。由于多毛症患者较少,预计以1:4的比例调查患者与健康人,当取α=0.05,检验效能1-β=0.9时,问需要调查患者与健康人各多少?
解析:本例是个完全随机设计的研究,研究对象有两类人群:多毛症患者和正常人;主要结局指标是血清睾丸酮含量,是连续型变量;由于多毛症患者较少,故按1:4的比例调查患者与健康人,目的是检验两样本人群中血清睾丸酮含量的比较时(即两均值差异性检验)所需的样本含量估计。根据题目我们知道了四个参数:①δ=μ1-μ2=10;②标准差S=13.3;③α=0.05(双侧检验);④检验效能1-β=0.9。
PASS软件样本含量估算的具体步骤:
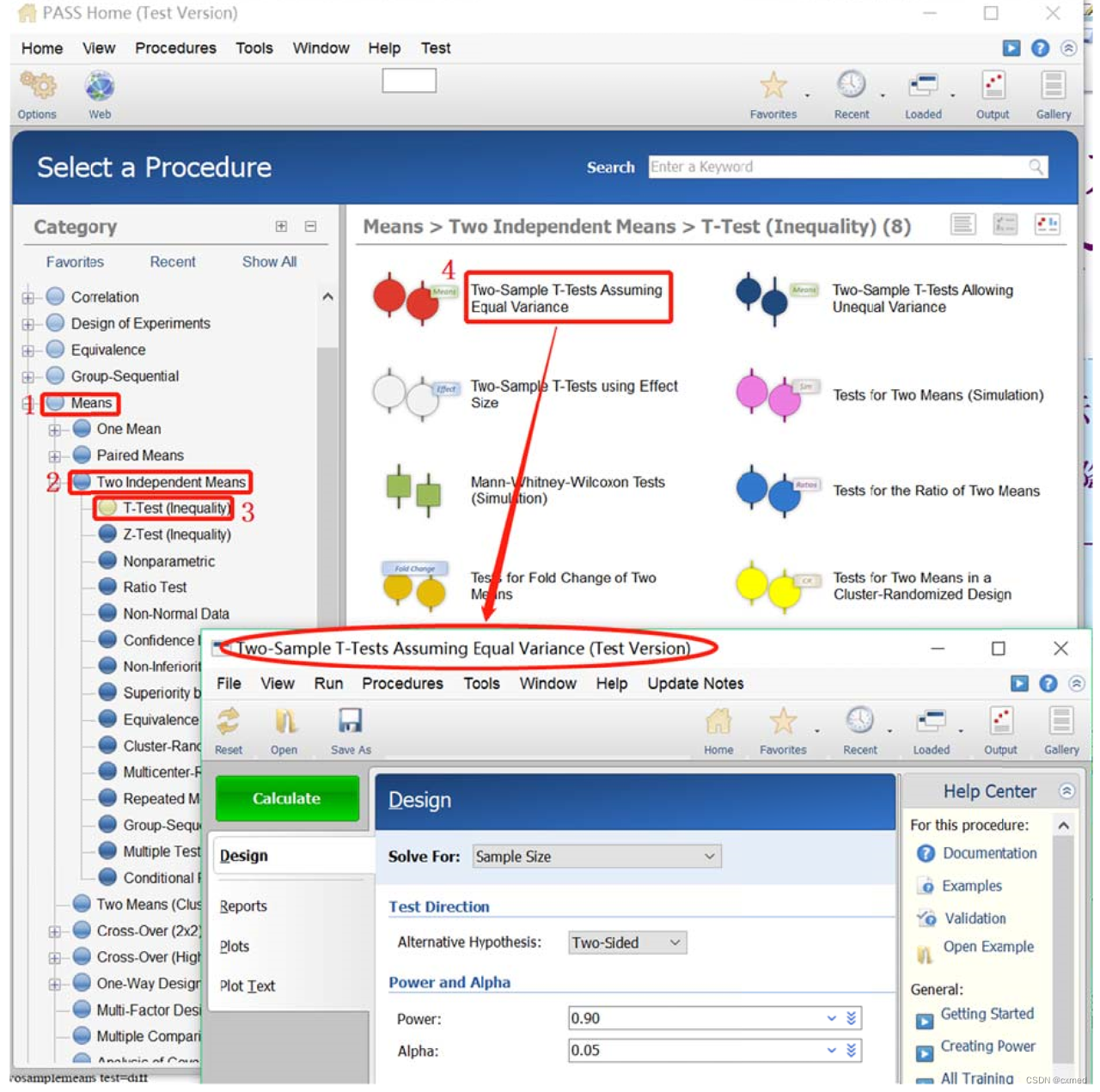
01 PASS主菜单进入样本含量估算设置界面:
打开PASS15软件,①点击Means菜单并双击或其前面的“+”展开子菜单栏;→②点击Two Independent Means菜单并双击或其前面的“+”展开子菜单栏;→③点击T –Test(Inequality)→④点击Two Sample T-Tests Assuming Equal Variance→弹出 Two Sample T-Tests Assuming Equal Variance 对话框进入完全随机设计两均数比较的样本含量估计界面,详见操作示意图(图1)。
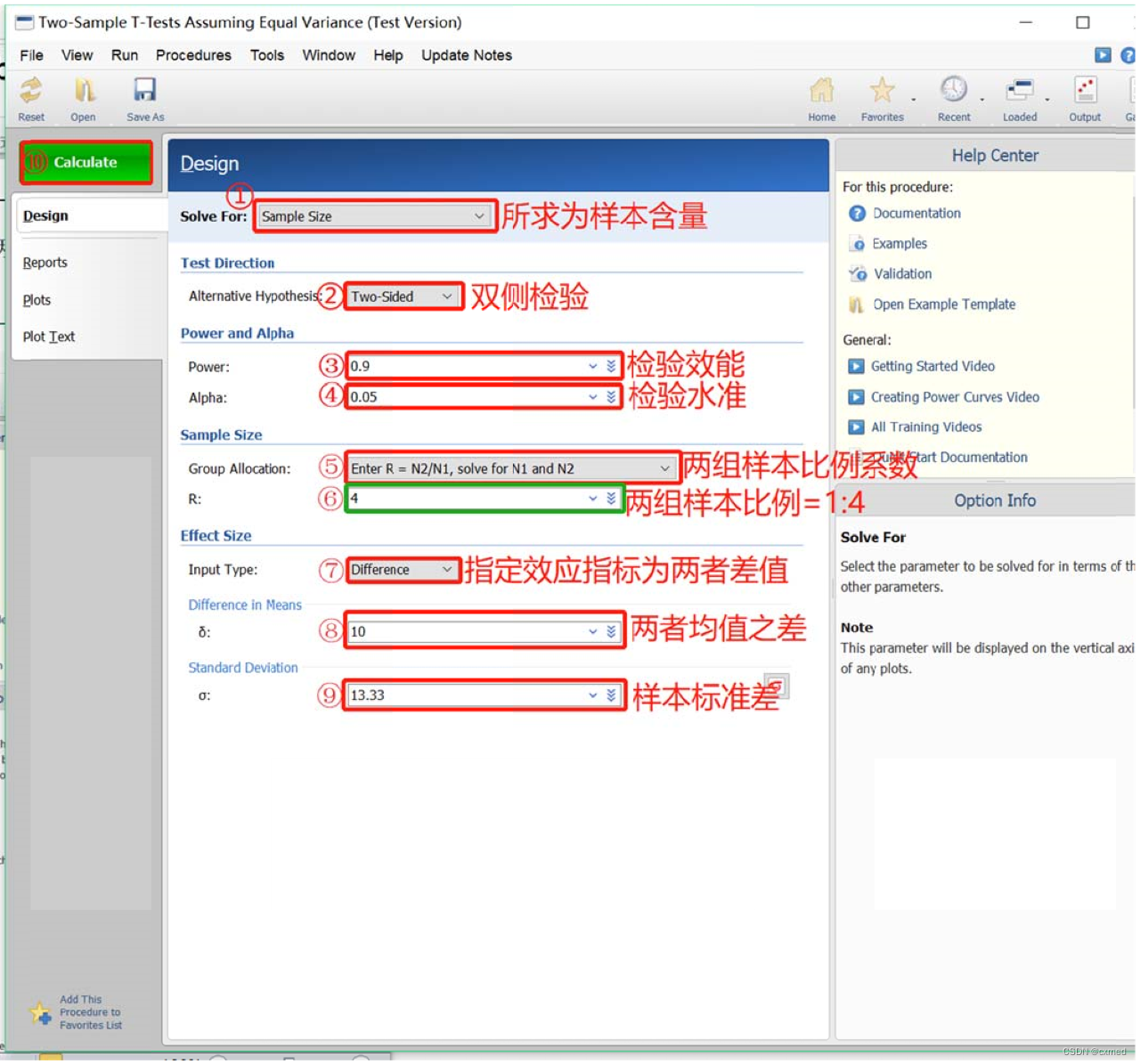
02 PASS样本含量估算参数设置:
①Solve For: Sample Size,首先说明我们本次所求的结果为样本含量;→②Alternative Hypothesis:Two-sided,表明进行床测检验;→③Power:0.9,表明检验效能为90%;→④Alpha:0.05,表示检验水准为0.05;→⑤Group Allocation:Enter R=N1/N2,solve for N1 and N2,表明通过设定两组样本比例系数来控制两组各自样本;→⑥R:4,表示两组样本含量比例为1:4;→⑦Input Type:Difference,指定效应指标的类型,选择“Differcnce”选项,只要输入两均数之差值即可;→⑧δ:10,指定两均数之差δ,本例δ=H1-H0=10;⑨σ:13.33,指定标准差S=13.33;→⑩点击Calculate按钮,完成两样本含量不等时的两样本均数比较的样本含量估算,详见操作示意图(图2)。
03 PASS样本含量估算结果:
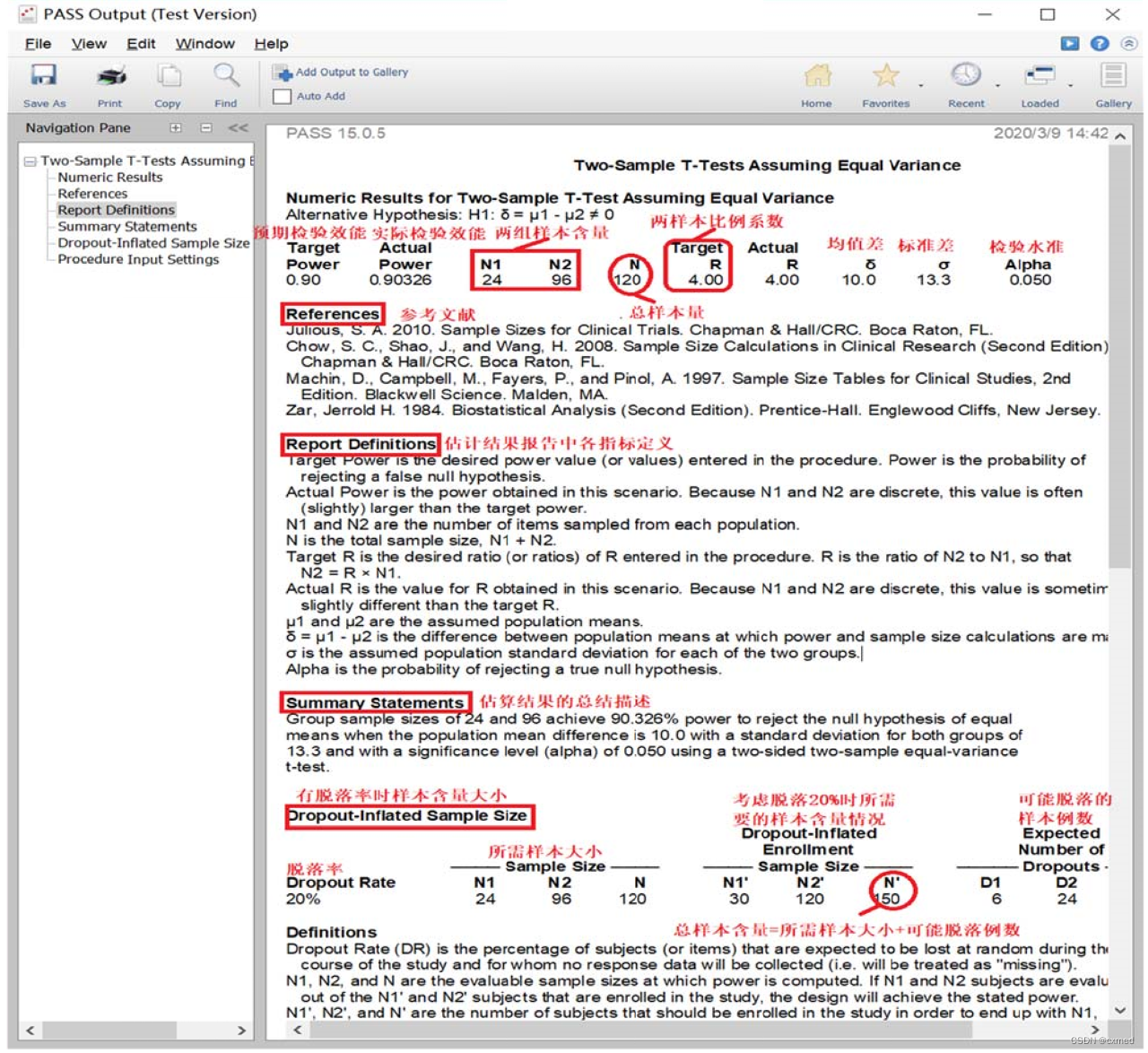
由图3可知,PASS软件给出的结果主要有:样本含量估算的结果、相关参考文献、样本量估算报告中出现各名词的定义、对计算结果的总结描述以及假定脱落率为20%时所需的样本含量估计结果和其各名词的相关定义。由于脱落率不同研究结果各不相同,故本次不看脱落率为20%的相关结果。从结果可知,若患者和正常人群按1:4的样本含量作调查,应调查患者24人,正常人96人,总共需要120人。
想要了解更多统计教程相关知识,请登录常笑医学网(www.cxmed.cn)中医学统计栏目进行查询和学习。

















 6145
6145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









