






算法思路
将图的所有边按权重排序
按顺序取出每条边
按原位置拼接,如果形成环就跳过这一条边的拼接
算法实现
图的实现
此实现方法没有节点类
采用邻接矩阵和顶点索引,以及边类
邻接矩阵int[][] matrix(邻接矩阵无需设置为沿对角线对称)
matrix[i][j]表示从索引i的节点指向索引j的节点的权值
权值为0表示两点不连接或者自身与自身不连接
两个重点
每条边按权重排序
edges是图所有边的集合
需要重写compare()方法,默认是升序排序
o1 和o2 是两个对象也即两条边,return matrix[o1.A][o1.B] - matrix[o2.A][o2.B]的作用是,集合调用sort()方法进行排序时,按前一条边的权重减去后一条边的权重,小于0(前一条边的权重小)则两条边的位置不变,大于0则交换位置(大概意思是这样)
edges.sort(new Comparator() {
@Override
public int compare(Edge o1, Edge o2) {
return matrix[o1.A][o1.B] - matrix[o2.A][o2.B];
}
});
判断是否有环(回路)
基本思路:判断一条边加入的时候两个端点的 "终点" 是否相同,相同则说明有环
getEnd()
int[] ends保存所有节点的终点索引,但不是一开始就确定,而是执行最小生成树算法的过程中才动态确定每个元素的一个数组
最开始ends所有元素都是0
如果传进来的索引i,ends[i] == 0则说明这个节点是第一次被访问到,则直接返回自身i(因为不会进入循环),表示此节点的终点是自己
传进来索引i,ends[i] != 0则说明这个节点不是第一次被访问到,则把这个节点的终点索引赋值给i,如果ends[i]仍然不为0则说明最开始索引i的终点也有终点,则再把终点的终点索引赋值给i,while (ends[i] != 0)的作用就是不断往下找到真正的终点
在遍历边集合过程中,endOfA != endOfB如果边的两个端点的终点索引不同,ends[endOfA] = endOfB;则把第一个端点的终点的终点设置为第二个端点的终点(可能有点绕,这步骤的原因是两个端点终点不同,所以可以加入最终结果的边集合,也就是这条边已经确定加入图中,所以第一个端点必定能按这条边到达第二个端点的终点)
/**
* 本方法获取索引为i的顶点的终点, 用于判断两个顶点的终点是否相同
*
* @param ends 记录各个顶点的终点(遍历过程中才动态确定的数组)
* @param i 传入的顶点索引
* @return int 传入索引对应顶点的终点索引
*/
private int getEnd(int[] ends, int i) {
while (ends[i] != 0) { // 循环是为了找到最终的终点
i = ends[i];
}
return i;
}
/*****下面的代码在最小生成树算法主体方法中***********************/
// 如果这条边取出来拼接后构成环, 则取消拼接操作
int endOfA = getEnd(ends, edge.A);
int endOfB = getEnd(ends, edge.B);
// 如果边的第一个顶点的终点不等于第二个顶点的终点
if (endOfA != endOfB) {
// 设置第一个顶点的终点的终点为第二个顶点的终点
ends[endOfA] = endOfB;
result.add(edge); // 最小生成树结果的边集合
}
算法主体方法
int[] ends保存取出各个边后依次拼接时, 各个顶点的终点索引
把边的权重排序
Listresult保存最终结果的所有边的集合
依次取出,不形成回路则拼接
将结果集合的所有边以邻接矩阵int[][] treeMatrix的形式表现
/**
* 克鲁斯卡尔算法-最小生成树
*
* @return void
*/
public void KruskalTree() {
// ends保存取出各个边后依次拼接时, 各个顶点的终点索引
int[] ends = new int[N];
// 把边的权重排序
edges.sort(new Comparator() {
@Override
public int compare(Edge o1, Edge o2) {
return matrix[o1.A][o1.B] - matrix[o2.A][o2.B];
}
});
// 保存最终结果的所有边的集合
List result = new ArrayList<>();
// 依次取出并拼接
for (Edge edge : edges) {
// 如果这条边取出来拼接后构成环, 则取消拼接操作
int endOfA = getEnd(ends, edge.A);
int endOfB = getEnd(ends, edge.B);
// 如果边的第一个顶点的终点不等于第二个顶点的终点
if (endOfA != endOfB) {
// 设置第一个顶点的终点的终点为第二个顶点的终点
ends[endOfA] = endOfB;
result.add(edge);
}
}
// 查看一下结果
System.out.println(result);
// 返回最小生成树的邻接矩阵
int[][] treeMatrix = new int[N][N];
// 将结果集合的所有边以邻接矩阵的形式表现
for (Edge edge : result) {
treeMatrix[edge.A][edge.B] = matrix[edge.A][edge.B];
}
System.out.println("最小生成树的邻接矩阵: ");
for (int[] nums : treeMatrix) {
System.out.println(Arrays.toString(nums));
}
}
测试
6个节点,对应保存数据为字母ABCDEF
int[][] set是为了初始化邻接矩阵graph.setMatrix(set[i][0], set[i][1], set[i][2])
设置边集合graph.setEdges()
执行算法graph.KruskalTree()
public static void main(String[] args) {
Graph graph = new Graph<>(6);
graph.setDatas(new String[]{"A", "B", "C", "D", "E", "F"});
// {端点索引, 端点索引, 权值}
int[][] set = {{0, 1, 1},
{0, 2, 3},
{1, 3, 2},
{1, 5, 2},
{2, 3, 4},
{2, 5, 7},
{3, 4, 1},
{4, 5, 8}};
for (int i = 0; i < set.length; i++) {
// graph.setMatrix(端点索引, 端点索引, 权值)
graph.setMatrix(set[i][0], set[i][1], set[i][2]);
}
graph.setEdges();
graph.KruskalTree();
}
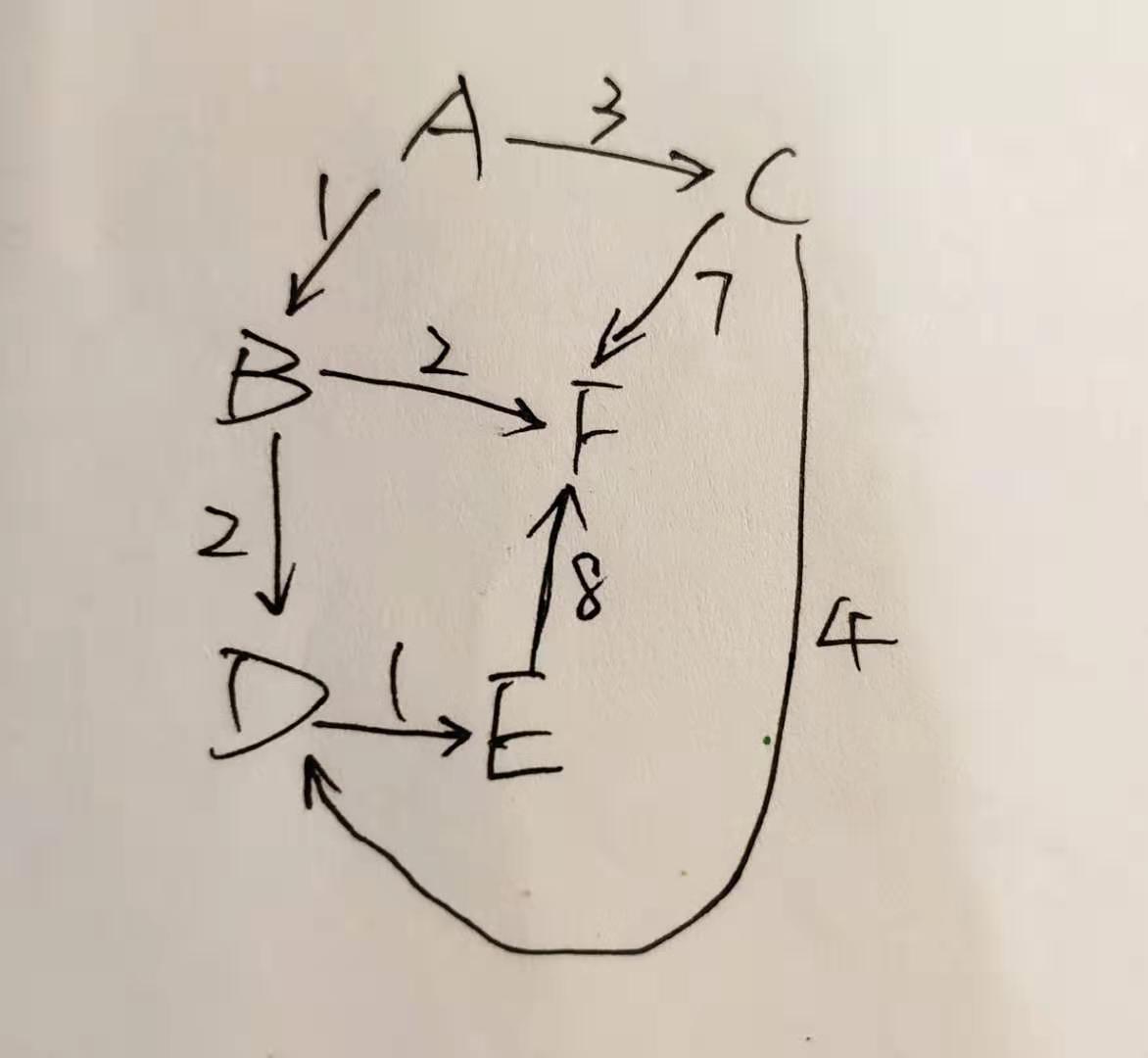
图
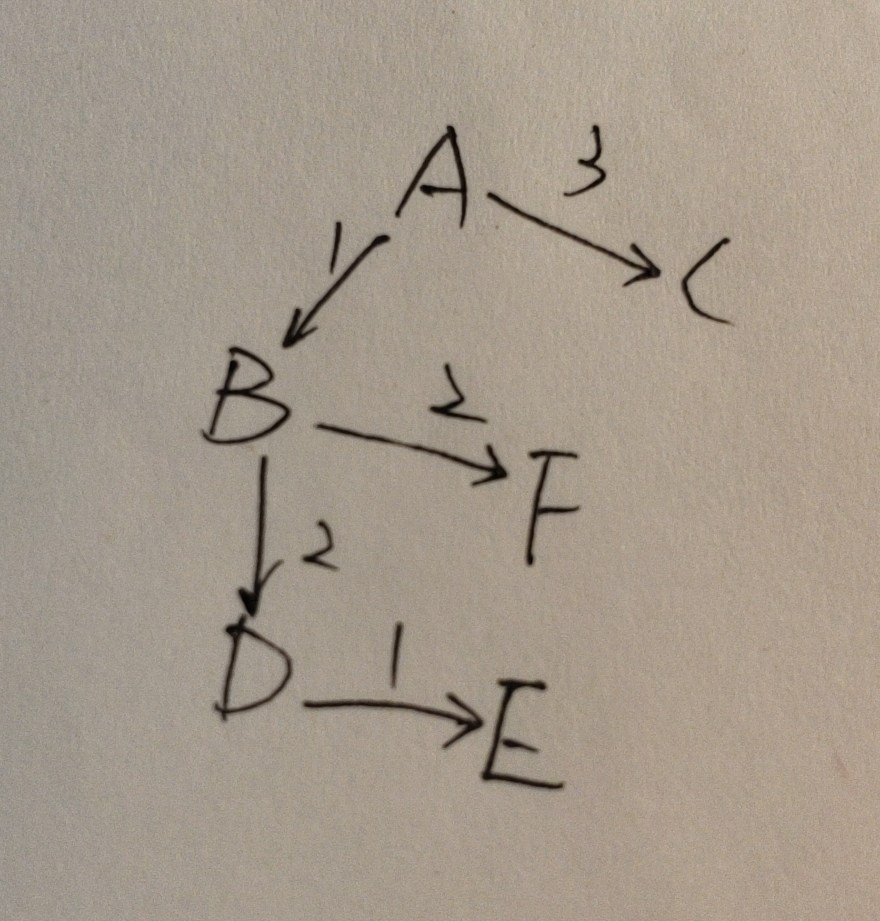
最小生成树
输出结果如下
[, , , , ]
最小生成树的邻接矩阵:
[0, 1, 3, 0, 0, 0]
[0, 0, 0, 2, 0, 2]
[0, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 1, 0]
[0, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 0]
完整代码实现
public class Graph {
private int N; // 节点个数
public int[][] matrix; // 邻接矩阵
private T[] datas; // 保存每个节点的数据
public List edges = new ArrayList<>(); // 边集合
class Edge {
int A; // 顶点索引
int B; // 顶点索引
public Edge(int a, int b) {
A = a;
B = b;
}
// 重写toString()方法方便查看结果
@Override
public String toString() {
return "
datas[A] +
"-" + matrix[A][B] + "-" + datas[B] +
'>';
}
}
public Graph(int N) {
this.N = N;
matrix = new int[N][N];
statuses = new Status[N];
datas = (T[]) new Object[N]; // 泛型数组实例化
}
/**
* 邻接矩阵保存的信息是从一个节点指向另一个节点的信息
*
* @param from 从这个节点
* @param to 指向这个节点
* @param weight 路径权重
* @return void
*/
public void setMatrix(int from, int to, int weight) {
matrix[from][to] = weight;
}
/**
* 设置图的边(matrix初始化之后才调用)
*
* @return void
*/
public void setEdges() {
for (int i = 0; i < matrix.length; i++) {
for (int j = 0; j < matrix[i].length; j++) {
if (matrix[i][j] > 0) {
edges.add(new Edge(i, j));
}
}
}
}
/**
* 最小生成树中判断是否有回路的重要方法
* 获取索引为i的顶点的终点, 用于判断两个顶点的终点是否相同
*
* @param ends 记录各个顶点的终点(遍历过程中才动态确定的数组)
* @param i 传入的顶点索引
* @return int 原顶点的终点索引
*/
private int getEnd(int[] ends, int i) {
System.out.print(datas[i] + "->");
while (ends[i] != 0) { // 艹我懂了: 循环是为了找到最终的终点
i = ends[i];
}
System.out.println(datas[i]);
return i;
}
/**
* 克鲁斯卡尔算法-最小生成树
*
* @return void
*/
public void KruskalTree() {
// ends保存取出各个边后依次拼接时, 各个顶点的终点索引
int[] ends = new int[N];
// 把边的权重排序
edges.sort(new Comparator() {
@Override
public int compare(Edge o1, Edge o2) {
return matrix[o1.A][o1.B] - matrix[o2.A][o2.B];
}
});
// 保存最小生成树中包含的边集合
List result = new ArrayList<>();
// 依次取出并拼接
for (Edge edge : edges) {
// 如果这条边取出来拼接后构成环, 则取消拼接操作
int endOfA = getEnd(ends, edge.A);
int endOfB = getEnd(ends, edge.B);
// 如果边的第一个顶点的终点不等于第二个顶点的终点
if (endOfA != endOfB) {
// 设置第一个顶点的终点的终点为第二个顶点的终点
ends[endOfA] = endOfB;
result.add(edge);
}
}
System.out.println(result);
// 返回最小生成树的邻接矩阵
int[][] treeMatrix = new int[N][N];
for (Edge edge : result) {
treeMatrix[edge.A][edge.B] = matrix[edge.A][edge.B];
}
System.out.println("最小生成树的邻接矩阵: ");
for (int[] nums : treeMatrix) {
System.out.println(Arrays.toString(nums));
}
}
public static void main(String[] args) {
Graph graph = new Graph<>(6);
graph.setDatas(new String[]{"A", "B", "C", "D", "E", "F"});
// {端点索引, 端点索引, 权值}
int[][] set = {{0, 1, 1},
{0, 2, 3},
{1, 3, 2},
{1, 5, 2},
{2, 3, 4},
{2, 5, 7},
{3, 4, 1},
{4, 5, 8}};
for (int i = 0; i < set.length; i++) {
// graph.setMatrix(端点索引, 端点索引, 权值)
graph.setMatrix(set[i][0], set[i][1], set[i][2]);
}
graph.setEdges();
graph.KruskalTree();
}
}
谢谢,第一次写文,不喜轻喷,狗头保命















 230
230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









