







AI 开发者按,本文的作者是数据科学家 Maël Fabien。在过去的几个月里,他在个人博客上写了 100 多篇文章。这个内容量相当可观。他突然想到一个主意:训练一个能像他一样说话的语言生成模型。
为此,他写了一篇文章分享了生成一个像人一样说话的神经网络模型的过程和相关代码,他的文章内容如下:
我想训练一个能像我一样说话的语言生成模型,或者更具体地说,一个可以像我一样写作的模型。它可以完美的说明语言生成的主要概念、使用 keras 实现语言生成模型,以及我的模型的局限性。
本文的全部代码都可以在这个 repo 中找到:
https://github.com/maelfabien/Machine_Learning_Tutorials?source=post_page-----9552c16e2396----------------------
在我们开始之前,我想分享这个意外发现的资源—— Kaggle Kernel ,它对理解语言生成算法结构来说是非常有用资源。
语言生成
自然语言生成的目的是生成有意义的自然语言。
大多数情况下,内容是作为单个单词的序列生成的。总的来说,它的工作原理如下:
你训练一个模型来预测序列中的下一个单词
你给经过训练的模型一个输入
重复上面的步骤 n 次,生成接下来的 n 个单词
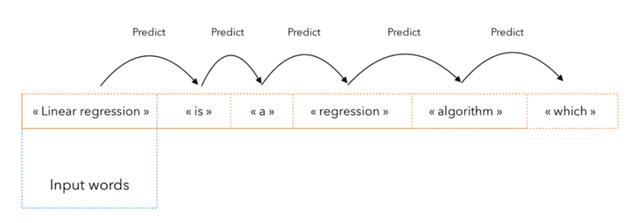
序列预测的过程
1.创建数据集
第一步是构建一个数据集,以便我们稍后将要构建的网络可以理解这个数据集。首先导入以下包:
from keras.preprocessing.sequence import pad_sequences
from keras.layers import Embedding, LSTM, Dense, Dropout
from keras.preprocessing.text import Tokenizer
from keras.callbacks import EarlyStopping
from keras.models import Sequential
import keras.utils as ku
import pandas as pd
import numpy as np
import string, os
a.加载数据
我写的每一篇文章的标题都遵循这个模板:

这是我们通常不希望在最终数据集中包含的内容类型。相反,我们将关注文本本身。
所有文章都写在一个单独的 Markdown 文件中。标题基本上包含了标题、图片标题等信息。
首先,我们需要指向包含文章的文件夹,在我的目录中,名为「maelfabien.github.io」。
B.句子标记
然后,打开每一篇文章,并将每一篇文章的内容添加到列表中。但是,由于我们的目标是生成句子,而不是生成整篇文章,因此我们将把每一篇文章拆分成一个句子列表,并将每个句子附加到「all_sentences」列表中:
all_sentences=
for file in glob.glob("*.md"):
f = open(file,'r')
txt = f.read.replace(















 1070
1070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









