





什么是梯度下降?
梯度下降是一种优化算法,目的是求出目标函数的最优解。
为什么需要梯度下降?
随着我们的机器学习模型越来越复杂,参数越来越多,我们很难求出一个具体的公式直接解出最佳的优化参数,其次,像多元线性回归的正规方程
假设要优化一个函数
我们需要寻找一个最佳的参数
学过初中数学的人都知道,这个函数大于等于0,最小值就是0, 最佳的
#定义函数
def f(x):
return 0.5 * (x - 0.25)**2如何优化?
如果你学习过高等数学,应该知道有个概念叫梯度,梯度的方向就代表着函数增长速度最快的方向,那么很显然,如果要使得目标函数最小,梯度的反方向就是函数减小的速度最快方向,于是就得出了梯度下降的公式。
梯度下降的优化公式
其中
这么说你可能不明白怎么回事,其实吧,梯度下降不是像最小二乘法,正规方程那样,直接运算就能得出结果,梯度下降是一个迭代的过程,它是渐进的,不是一撮而就的。
一开始,目标函数的数值很大,我们要优化目标函数,使其变小,而使目标函数减小就得改变需要优化的参数
就好比我们在一座高山之上,现在要下山,就往下山最快的路径上移动一步。
对之前函数求导:
#f(x)的导数(现在只有一元所以是导数,如果是多元函数就是偏导数)
def df(x):
return x - 0.25 #求导应该不用解释吧定义学习率
alpha = 0.1 #你可以更改学习率试试其他值为了将优化过程保存下来,还需要额外定义一些变量:
GD_X 梯度下降过程
既然在不断的优化目标函数,算法总要有个停止的时候,当优化次数大于100 的时候就停止优化(你也可以选择多迭代几次),或者当这一次优化和上一次优化的差距已经非常小,小到接近0时,我们也停止优化(这说明已经优化到最优值了,导数已经接近为0,我们知道,函数的极值出现在一阶导数为0的地方)。
while iter_num <100 and f_change > 1e-10: #迭代次数小于100次或者函数变化小于1e-10次方时停止迭代
iter_num += 1
x = x - alpha * df(x)
tmp = f(x)
f_change = abs(f_current - tmp)
f_current = tmp
GD_X.append(x)
GD_Y.append(f_current)查看变量
GD_X #可以看出x已经无限逼近0.25了
也可以打印出y的值
print("{:.10f}".format(GD_Y[-1])) #无限接近0
你可以观察到一个现象,最终优化的参数
可视化学习过程
import numpy as np
import matplotlib.pyplot as plt
X = np.arange(-4,4,0.05)
Y = f(X)
Y = np.array(Y)
plt.plot(X,Y)
plt.scatter(GD_X,GD_Y)
plt.title("$y = 0.5(x - 0.25)^2$")
plt.show()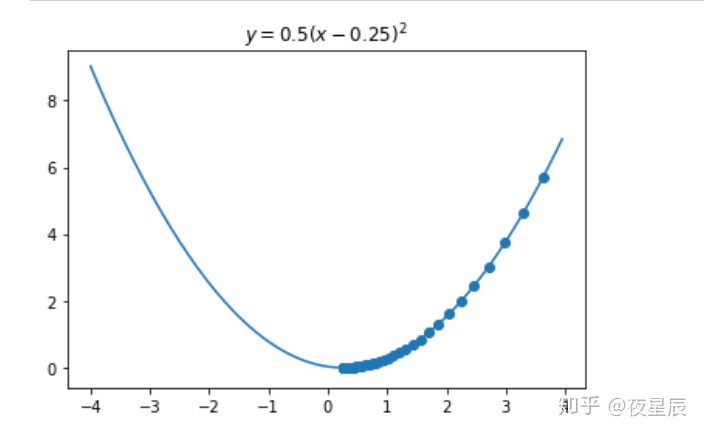
可以看出,梯度下降算法是一步一步的逼近最小值的。
将学习率改为1.8后再运行
plt.plot(X,Y)
plt.plot(GD_X,GD_Y) #注意为了显示清楚每次变化这里我做了调整
plt.title("$y = 0.5(x - 0.25)^2$")
plt.show()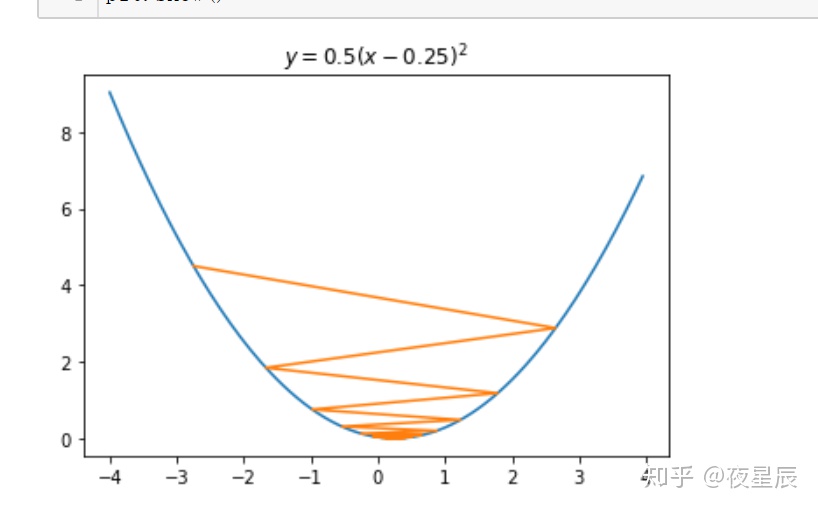
你还可以试试其他的学习率,还会发现有趣的现象,这里就不说了,建议把我的代码拿来跑一下,一定要自己亲手试试才知道。
(我的代码都能直接运行)















 852
852











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









