





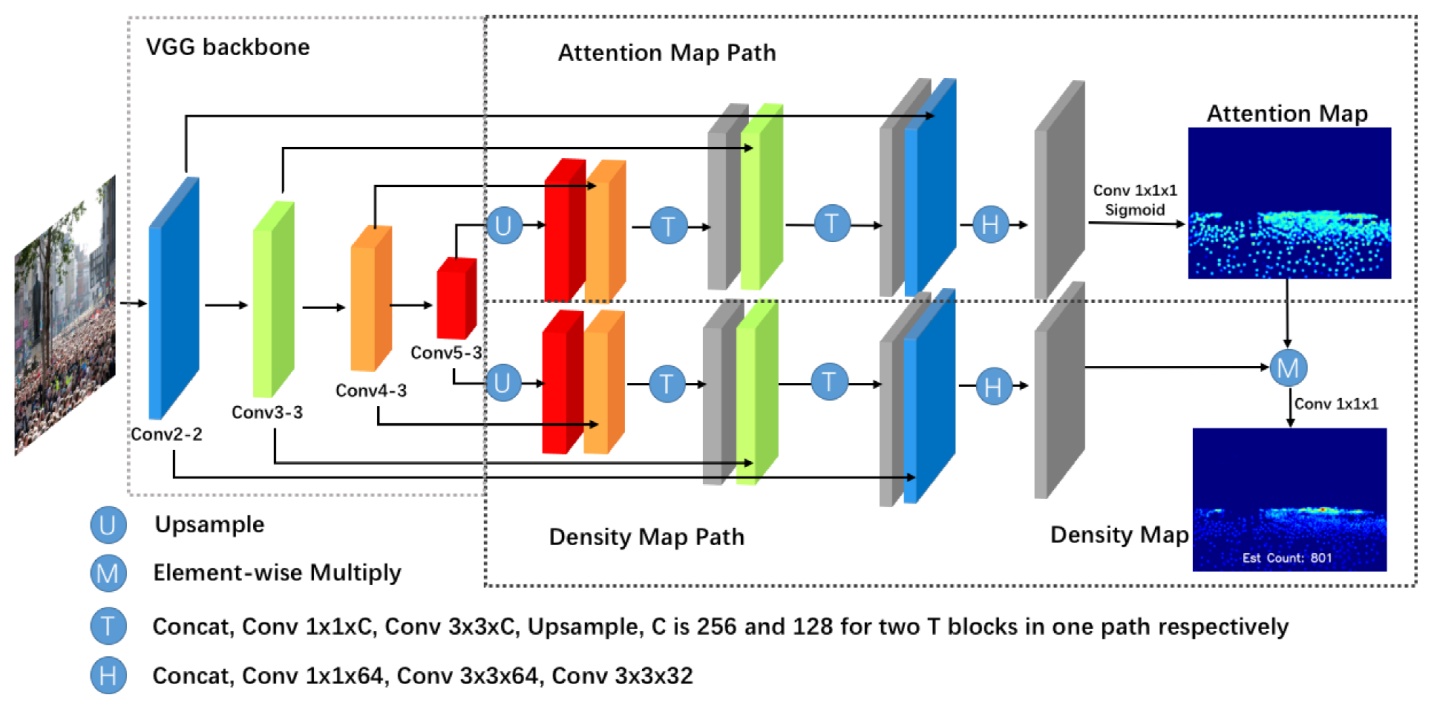

1.Network
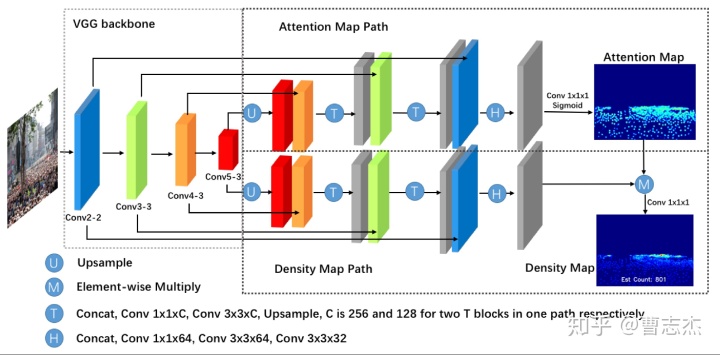
(1)backbone用了VGG16,用了BN
(2)整个结构跟UNet很像,上采样没说用的什么
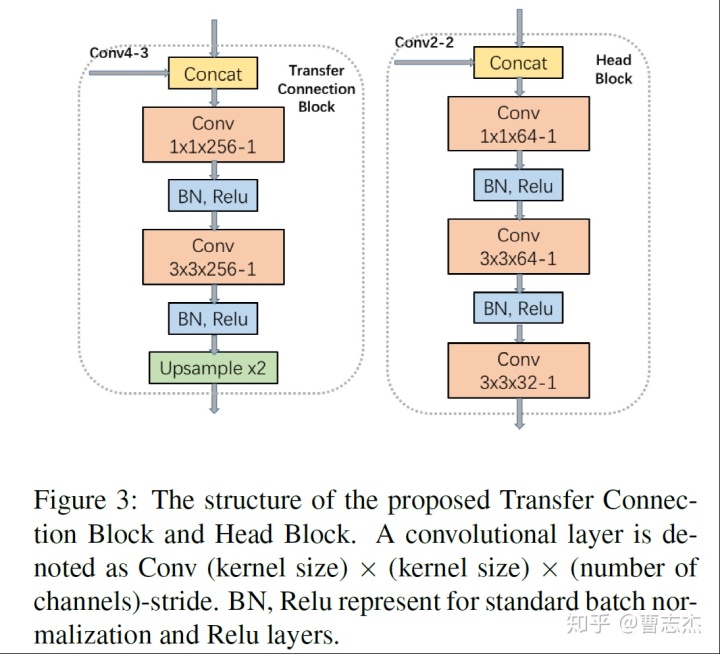
(3)T和H的结构如下:
通过1x1的卷积来减少参数量
2.Contribution
其实idea层面上,这算是对segmentation的mask的最典型的应用了,应当等多地关注训练细节
(1)counting ground truth的制作
采用μ=15,σ=4的统一大小的高斯核
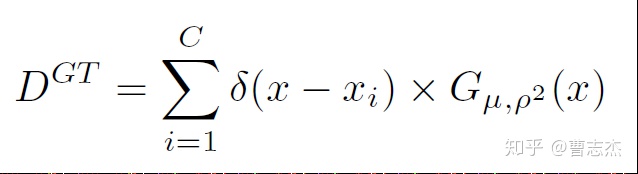
(2)segmentation的ground truth的制作
对counting ground truth再进行高斯模糊,
μ=3,σ=2,然后进行阈值过滤,即二值化
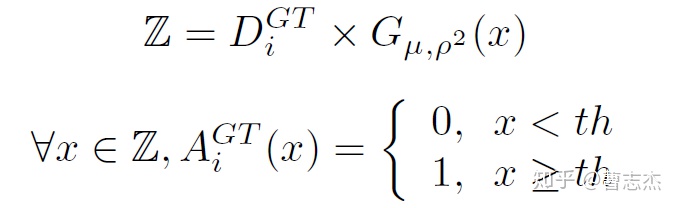
阈值th=0.001
(3)训练数据的处理
先将图片进行resize,如果短边<512,就使短边scale到512,如果>512,就不resize,
再进行[0.8,1.2]的随机的scale处理
再随机crop出400x400的patch
然后以0.5的随机概率进行水平翻转
然后进行gamma contrast transfermation,参数范围[0.5,1.5],概率为0.3
以0.1的概率随机将彩图变黑白
(4)模型参数初始化
除了pre-train的部分,其余部分用N(0,0.01)的高斯分布初始化
(5)loss
Counting loss:
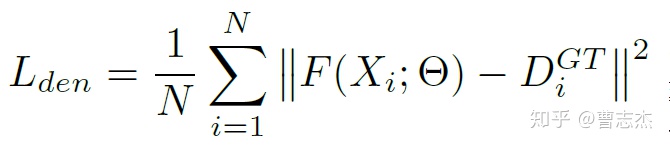
Segmentation loss:
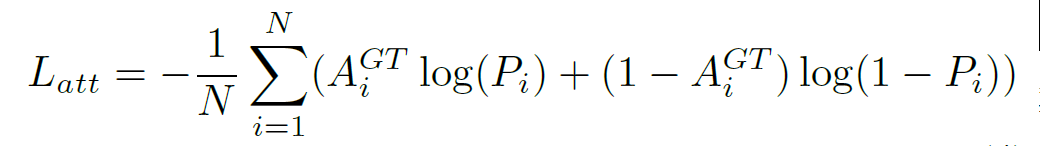
最后加起来:α=0.1
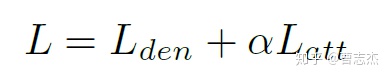
3.Experiment
(1)在ShanghaiTech上的结果
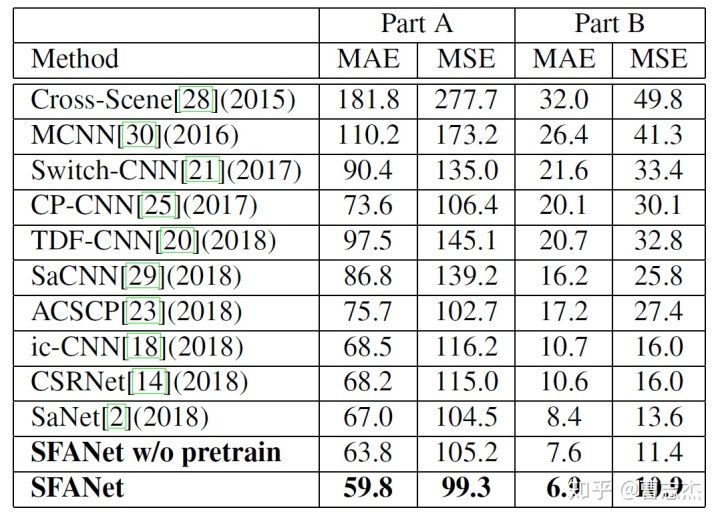
(2)UCF_CC_50
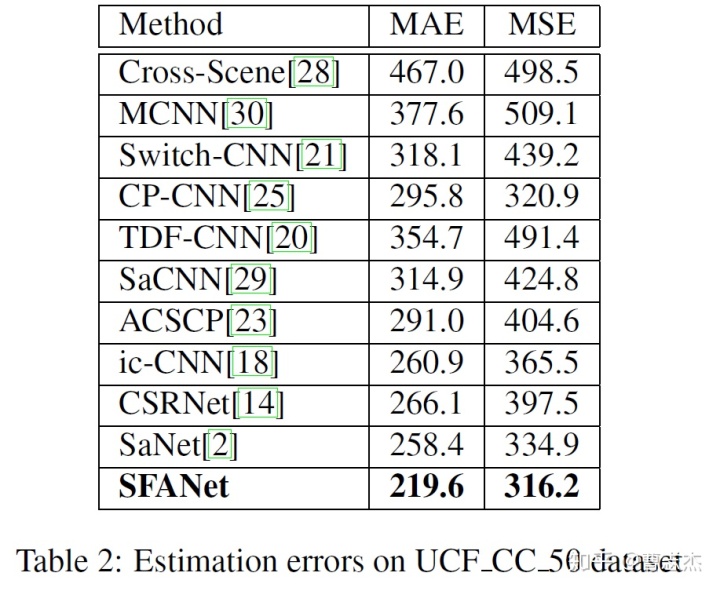
(3)UCSD

4.评价
我挺想复现一下这个paper,可是目前没有可用服务器QAQ,不过这篇paper采用的方法跟我之前自己实验的方法很像,只是我没有用那么多数据增强的方法,导致我自己实验效果差很可能使trainingdb本身d的问题。















 620
620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









