







Title: Encoder-Decoder Based Convolutional Neural Networks with Multi-Scale-Aware Modules for Crowd Counting
Abstract: In this paper, we propose two modified neural networks based on dual path multi-scale fusion networks (SFANet) and SegNet for accurate and efficient crowd counting. Inspired by SFANet, the first model, which is named M-SFANet, is attached with atrous spatial pyramid pooling (ASPP) and context-aware module (CAN). The encoder of M-SFANet is enhanced with ASPP containing parallel atrous convolutional layers with different sampling rates and hence able to extract multi-scale features of the target object and incorporate larger context. To further deal with scale variation throughout an input image, we leverage the CAN module which adaptively encodes the
scales of the contextual information. The combination yields an effective model for counting in both dense and sparse crowd scenes. Based on the SFANet decoder structure, M-SFANet’s decoder has dual paths, for density map and attention map generation. The second model is called M-SegNet, which is produced by replacing the bilinear upsampling in SFANet with max unpooling that is used in SegNet. This change provides a faster model while providing competitive counting performance. Designed for high-speed surveillance applications, M-SegNet has no additional multi-scale-aware module in order to not increase the complexity. Both models are encoder-decoder based architectures and are end-to-end trainable. We conduct extensive experiments on five crowd counting datasets and one vehicle counting dataset to show that these modifications yield algorithms that could improve state-of-the-art crowd counting methods. Codes are available at https://github.com/Pongpisit-Thanasutives/Variations-of-SFANet-for-Crowd-Counting.
Keywords: NONE.
题目:基于编码器-解码器的具有多尺度感知模块的群计数卷积神经网络
摘要:在本文中,我们提出了两种基于双路径多尺度融合网络(SFANet)和SegNet的改进神经网络,以实现准确高效的人群计数。受SFANet的启发,第一个模型被命名为M-SFANet,它附加了空洞空间金字塔池化(atrous spatial pyramid pooling,ASPP)和上下文模块(context-aware module,CAN)。M-SFANet的编码器使用ASPP进行了增强,ASPP包含具有不同采样率的并行空洞卷积层,因此能够提取目标对象的多尺度特征并包含更大的上下文。为了进一步处理整个输入图像的尺度变化,我们利用CAN模块对上下文信息的尺度进行自适应编码。该组合产生了一个在密集和稀疏人群场景中进行计数的有效模型。基于SFANet解码器结构,M-SFANet的解码器具有双路径,用于密度图和注意力图的生成。第二个模型称为M-SegNet,它是通过将SFANet中的双线性上采样替换为SegNet中使用的最大去极化而产生的。这一变化提供了一个更快的模型,同时提供了有竞争力的计数性能。M-SegNet专为高速监控应用而设计,为了不增加复杂性,它没有额外的多尺度感知模块。这两个模型都是基于编码器-解码器的架构,并且是端到端可训练的。我们在五个人群计数数据集和一个车辆计数数据集上进行了广泛的实验,以表明这些修改产生的算法可以改进最先进的人群计数方法。开源代码网址:https://github.com/Pongpisit-Thanasutives/Variations-of-SFANet-for-Crowd-Counting。
1.引言
人群计数是一项重要任务,因为它在公共安全、监控、交通控制和智能交通等领域有着广泛的应用。然而,由于真实世界图像中的严重遮挡、视角失真、尺度变化和不同的人群分布,高效地解决乍一看的问题是一项具有挑战性的计算机视觉任务,并非易事。特别是当目标物体处于拥挤的空间中时,这些问题是明显的。早期的一些方法[1]将人群计数视为一个检测问题。[2]中还研究了来自多个来源的手工特征。当目标对象彼此重叠并且手工制作的特征不能正确处理输入图像中人群分布的多样性时,这些方法是不合适的。为了考虑人群分布的特征,不应该考虑开发只预测目标图像中的人数的模型,因为这些特征被忽略了。因此,最近的方法更多地依赖于从头注释地面实况自动生成的密度图。另一方面,[3]的作者将密度图视为描述“空间像素将如何”的可能性,并提出了新的贝叶斯损失。然而,在我们的实验中,我们将密度图地面实况作为学习目标(除了我们在UCF-QNRF[4]上的实验),以便研究与大多数现有技术的方法相比,所提出的架构修改所带来的精度提高。
卷积神经网络(CNNs)已被用于估计精确的密度图。通过将卷积滤波器视为滑动窗口,CNN能够在输入图像的各个区域进行特征提取。因此,图像中人群分布的多样性得到了更恰当的处理。为了解决相机不同视角引起的头部尺度变化问题,以前的工作大多使用基于多列/多分辨率的架构[5]、[6]、[7]、[8]。然而,[9]中的研究表明,在MCNN[5]的每个列结构中学习的特征几乎相同,并且当网络深入时,训练这种架构是无效的。与多列网络架构相反,[9]中提出了一种基于截断VGG16[10]特征提取器和具有扩展卷积层的解码器的深度单列网络,并在ShanghaiTech[5]数据集上实现了突破性的计数性能。所提出的架构展示了VGG16编码器的优势,该编码器在ImageNet[11]上进行了预训练,用于更高语义的信息提取和跨视觉任务传递知识的能力。此外,该研究还演示了如何将萎缩卷积层连接到网络上,而不是添加更多可能导致空间信息丢失的池化层。不过,[12] 提出了在整个图像中使用相同滤波器和池化操作的问题。[12]的作者指出,由于透视失真,整个图像的感受野大小应该改变。为了解决这个问题,[12]中提出了一种称为CAN的尺度感知上下文模块,该模块能够在多个感受野大小上进行特征提取。通过模块设计,每个这样提取的特征在每个图像位置的重要性是可学习的。然而,CAN不包含减少背景噪声的机制,这可能会导致错误预测,尤其是在面对稀疏和复杂的场景时。除了人群计数,对象重叠也是图像分割的一个关键问题。因此,设计了诸如空间金字塔池(SPP)[13]和萎缩空间棱锥池(ASPP)[14]之类的尺度感知模块来捕获多个尺度上的上下文信息。通过采用从小到大的膨胀因子(atrous rate),模型的视野得到了放大,因此能够在多个尺度上进行对象编码[14]。基于编码器-解码器的CNN[15]、[16]、[17]在图像分割方面取得了先前的成功,这归因于重建精确对象边界的能力。基于编码器-解码器的网络也被提出用于群组计数,例如[7]、[8]、[9]、[18]、[19]、[20]。为了弥补图像分割和人群计数之间的差距,[21]引入了双路径多尺度融合网络(SFANet),该网络将类似UNet[15]的解码器与双路径结构相结合,以预测复杂背景中的头部区域,然后对头部计数进行回归。不幸的是,与CAN[12]不同,SFANet没有明确的模块来处理规模变化问题。
为了弥补现有方法的不足,我们提出了两种改进的人群计数网络。第一个提出的模型被称为“M-SFANet”(Modified-SFANet),其中多尺度感知模块CAN和ASPP在不同的编码阶段额外连接到SFANet的VGG160 bn[10]编码器,以解决上述SFANet问题,并通过在多个尺度上捕获目标对象周围的上下文来处理遮挡。由于SFANet的双路解码器用于抑制噪声背景,CAN的问题也得到了无缝的解决。M-SFANet自适应地(遵循视角)静态地学习上下文尺度;因此,该模型对于密集场景和稀疏场景都是有效的。其次,我们将双路径结构集成到类似ModSegNet[22]的编码器-解码器网络中,而不是Unet,并将该模型称为“M-SegNet”(Modified-SegNet)。ModSegNet是为医学图像分割而设计的,它类似于UNet,但利用了最大去极化[16],而不是无参数的转置卷积。据我们所知,关于人群计数的文献中还没有使用最大不饱和度。M-SegNet被设计为在计算上比SFANet更快(见表IX),同时提供类似的性能。此外,我们还通过平均预测测试了M-SegNet和M-SFANet之间的集成模型的性能。对于一些速度不受限制的监控应用,应该考虑集成模型,因为它的方差预测较低。
2. 相关工作
A 传统方法
一些早期的建议依赖于基于滑动窗口的检测算法。这需要从人头或人体中提取特征,如直方图定向梯度(HOG)[23]。不幸的是,当遇到高遮挡的图像时,这些方法无法检测到人。基于回归的方法试图从前景和纹理等特征生成的低级信息[24]中学习到目标对象数量的映射函数。[25]中也对映射函数进行了研究。
B 基于CNN方法
最近,基于CNN的方法在任务上比传统方法有了显著的改进。张等人[26]提出了一种深度训练的CNN来估计人群数量,同时预测人群密度水平。在[5]中,Zhang等人提出了一种多列CNN(MCNN),其中每列都被设计为对不同的尺度做出响应。李等人[9]提出了一种基于截断VGG16编码器和扩展卷积层作为解码器的深度单列CNN,以聚合多尺度上下文信息。Cao等人[7]提出了一种编码器-解码器规模的聚合网络(SANet)。姜等人[27]提出了一种包含多个解码路径的网格编码器网络(TEDnet)。施等人[28]利用了行人高度的透视信息,用于组合多尺度密度图。刘等人[19]通过将注意力感知网络集成到多尺度可变形网络中来检测人群区域,将注意力机制应用于人群计数。王等人[18]通过在合成数据上预训练人群计数器来提高人群计数的性能,并提出了一种通过域自适应的人群计数方法来处理标记数据的缺乏。刘等人[12]提出了一种具有尺度感知上下文结构(CAN)的基于VGG16的模型,该模型结合了从多个感受野大小中提取的特征,并学习每个这样的特征对图像位置的重要性。朱等人[21]提出了具有额外路径的双路径多尺度融合网络(SFANet)来监督学习生成的注意力图。SFANet的解码器重用来自类似于Unet[15]的编码阶段的粗略特征和高级特征。同样,Sindagi等人[29]也引入了注意力机制,但在网络设计中嵌入了空间注意力模块(SAM)。Sam等人[30]提供了一个单独的自上而下的反馈CNN来纠正初始预测。同样在[31]中,Sindagi等人设计了底部-顶部和顶部-底部特征融合方法,以利用存在于每个网络层的信息。最近,Ma等人[3]没有使用密度图作为学习目标,而是构建了一个密度贡献模型,并使用贝叶斯损失而不是香草均方误差(MSE)损失来训练基于VGG19[10]的网络。
3. 提出方法
由于存在我们修改和实验的两种基本神经网络架构SFANet[21]和SegNet[16],我们将我们的模型分别铸造为“M-SFANet”(改进的SFANet)和“M-SegNet”(改进的SegNet)。它们都是基于编码器-解码器的深度卷积神经网络。它们通常具有VGG16_bn的卷积层作为编码器,该编码器逐渐减小特征图的大小并捕获高级语义信息。在M-SFANet的情况下,特征通过CAN[12]模块和ASPP[14]来提取尺度感知上下文特征。最后,解码器恢复空间信息以生成最终的高分辨率密度图。作为组合的结果,与所提出的M-SegNet相比,M-SFANet更重量级,并且通常预测更准确的人群计数。基于SegNet,M-SegNet是轻量级的,没有额外的多尺度感知模块。然而,M-SegNet可以在一些人群计数基准上取得有竞争力的结果。
A. Modified SFANet (M-SFANet)
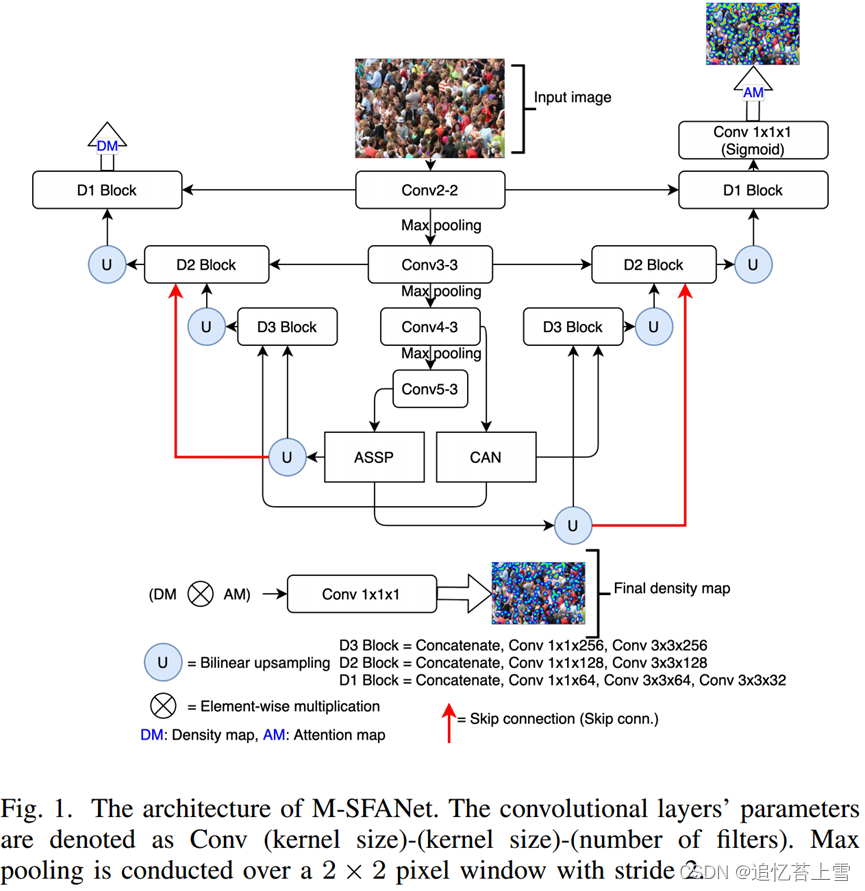
模型架构由3个新组件组成,VGG16_ bn特征图编码器、多尺度感知模块和双路径多尺度融合解码器[21]。首先,将输入图像输入到编码器中,以学习有用的高级语义含义。然后,将特征图输入到多尺度感知模块中,以突出目标对象和上下文的多尺度特征。M-SFANet架构中有两个多尺度感知模块,一个与VGG16_bn的第13层连接的模块是ASPP,另一个与VGA的第10层连接的是CAN。最后,解码器路径使用级联和双线性上采样将多尺度特征融合到密度图和注意力图中。在生成最终的密度图之前,通过生成的注意力图从背景中分割人群区域。这种机制将噪声背景隔开,并使模型更多地关注感兴趣的区域。我们利用[21]中的多任务损失函数来获得注意力图分支的优势。M-SFANet的概述如图1所示。除了用于预测最终密度图的最后一个卷积层之外,每个卷积层之后都进行批量归一化[32]和ReLU。
特征图编码器(VGG16_bn的13层):我们利用VGG16的第一个预训练的13层进行批量归一化,因为3x3卷积层的堆栈能够提取多尺度特征和多层次语义信息。与具有不同内核大小的多列架构相比,这是处理规模变化问题的更有效的方法[9]。来自第10层的高级特征图(原始输入的1/8大小)被馈送到CAN中,以自适应地对上下文信息的尺度进行编码[12]。此外,来自第13层的顶部特征图(原始输入的1/16大小)被馈送到ASPP中,以静态学习(不是专门针对每个图像位置)图像级特征(例如,在我们的实验中的人头)和多个速率的上下文信息。由于最收缩的特征,仅在顶层编码多尺度信息是无效的,这不适合生成高质量的密度图[9]。
上下文感知模块:CAN[12]模块能够使用平均池化操作的多个感受野产生规模感知上下文特征。根据[12],池化输出规模为1、2、3、6。该模块提取这些特征,并学习每个图像位置的每个此类特征的重要性,从而考虑图像内潜在的快速尺度变化[12]。提取的特征的重要性根据其与邻居的差异而变化。由于融合了不同尺度的判别信息,CAN模块在拥挤场景中遇到透视失真时表现良好。
空洞空间金字塔池:ASPP[14]模块将萎缩卷积和图像池的几个有效视场应用于传入特征,从而捕获多尺度信息。收缩率分别为1、6、12、18。由于atrous卷积,编码器中整个卷积层中与对象边界(人头和背景之间)相关的信息损失得到了缓解。在不损失图像分辨率的情况下,放大滤波器的视场以包含更大的上下文。与CAN不同,ASPP在空间位置上平等地对待提取的尺度特征的重要性;因此,该模块适用于上下文信息较少的稀疏场景。
双路径多尺度融合解码器:解码器架构由密度图路径和注意力图路径组成,如[21]所述。以下策略同时应用于密度图路径和注意力图路径。首先,使用双线性插值将ASPP的输出特征图上采样因子2,然后与CAN的输出特征映射连接。接下来,级联的特征图通过1x1x256和3x3x256卷积层。同样,融合后的特征被提升2倍,并与来自ASPP的conv3-3和提升采样(4倍)的特征图(图1中的红色连接器)连接,然后再通过1x1x128和3x3x128卷积层。这种跳跃连接有助于网络提醒自己从高级图像表示中学习到的多尺度特征。最后,在分别通过1x1x64、3x3x64和3x3x32卷积层之前,将128个融合特征上采样因子2,并与conv-2连接。由于使用了三个上采样层,该模型可以检索具有原始输入1/2大小的高分辨率特征图。将逐元素相乘应用于注意力图和密度特征图,以生成精细的最终密度图。
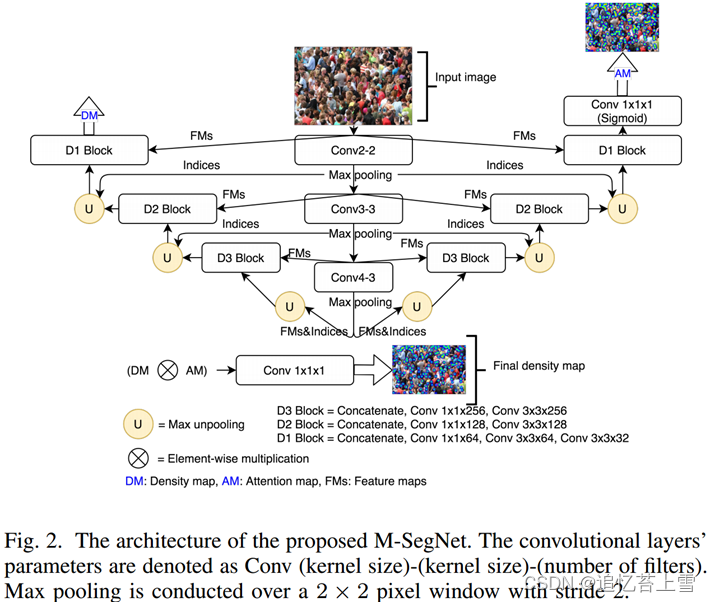
B. Modified SegNet (M-SegNet)
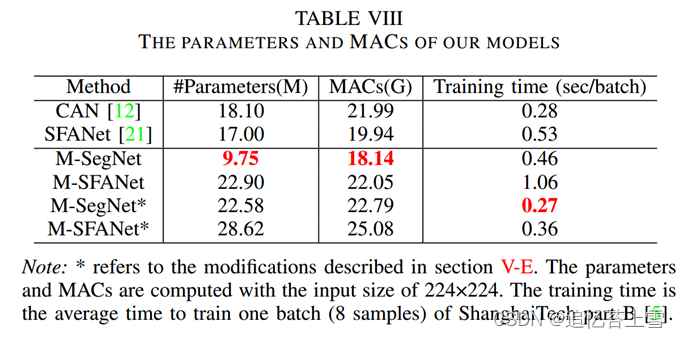
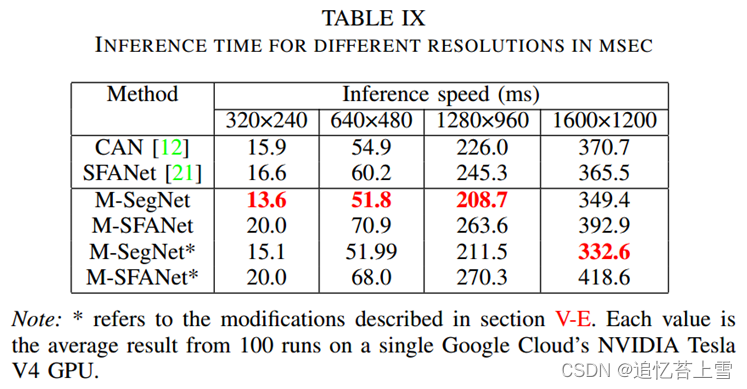
M-SegNet与M-SFANet共享几乎相同的组件,除了没有CAN模块和ASPP来额外强调多尺度信息,并且双线性上采样被使用来自相应编码器层的存储的最大池化索引[16]的最大去极化操作所取代。VGG16bn的前10层被用作特征图编码器。因此,M-SegNet比M-SFANet需要更少的计算资源(见表VIII和表IX),更适合速度受限的应用。M-SegNet的概述如图2所示。
4. 训练方法
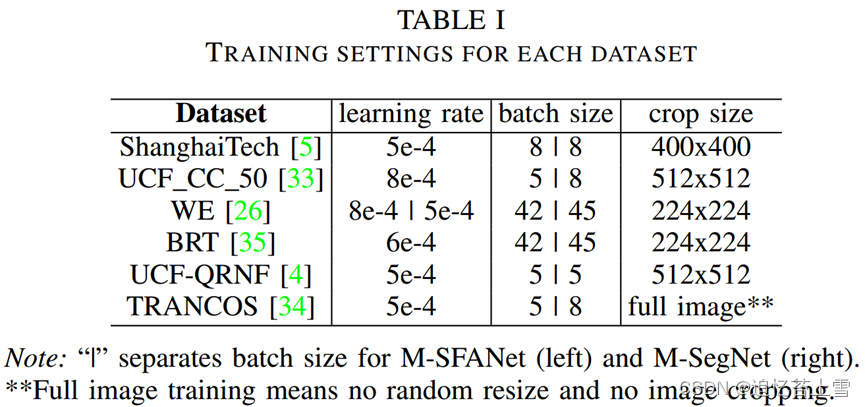
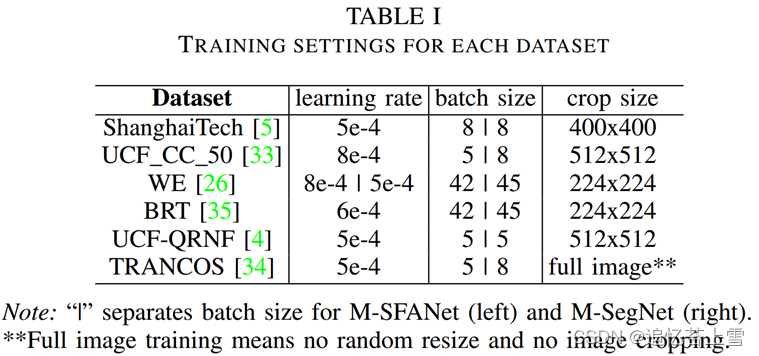
在本节中,我们将解释在我们的实验中如何自动生成密度图地面实况和注意力图地面实况。每个数据集的训练设置如表I所示。
A. 密度图标签
为了生成密度图人工标注D(x),我们遵循[5]中描述的具有固定标准差核的高斯方法。假设在像素![]() 处存在头部注释,表示为
处存在头部注释,表示为![]() ,可以通过与高斯核的卷积来构建密度图[25]。这些过程公式为:
,可以通过与高斯核的卷积来构建密度图[25]。这些过程公式为:
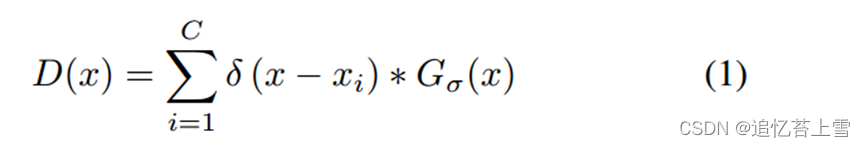
在人工标注中,我们将每个![]() 与具有参数
与具有参数![]() 的高斯核(模糊每个头部注释)进行卷积,其中C是总头数的数量。在我们的实验中,我们设定
的高斯核(模糊每个头部注释)进行卷积,其中C是总头数的数量。在我们的实验中,我们设定![]() =5,4,4,10用于ShanghaiTech[5]、UCF_CC_50[33]、WorldExpo’10 [26]和TRANCOS[34]数据集。对于Beijing BRT [35]数据集,我们使用https://github.com/XMU-smartdsp/Beijing-BRT-dataset中提供的代码来生成密度图人工标签。对于UCF_ CC_50[33]和WE[26],我们从https://github.com/gjy3035/C-3-Framework中借用代码框架[36]。
=5,4,4,10用于ShanghaiTech[5]、UCF_CC_50[33]、WorldExpo’10 [26]和TRANCOS[34]数据集。对于Beijing BRT [35]数据集,我们使用https://github.com/XMU-smartdsp/Beijing-BRT-dataset中提供的代码来生成密度图人工标签。对于UCF_ CC_50[33]和WE[26],我们从https://github.com/gjy3035/C-3-Framework中借用代码框架[36]。
B. 注意力图标签
根据[21],基于应用于相应密度图标签的阈值来生成注意力图标签。公式如下:
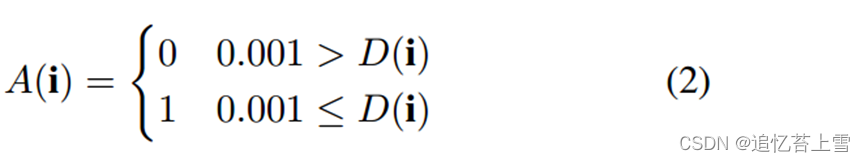
其中i 是密度图地面实况中的坐标。根据[21],阈值设置为0.001。
C. 训练细节
我们利用了[21]中描述的图像增强策略,但裁剪图像的大小因数据集而异。因此,在训练每个数据集时,我们使用不同的学习率和批量大小。主要策略可以概括为通过小部分随机调整大小、图像裁剪、水平翻转和伽玛调整。与[21]的主要区别在于,我们使用Adam[37]和前瞻性优化器[38]来训练我们的模型,因为它显示出比标准Adam优化器更快的收敛性,并且在[38]中实验证明可以提高模型的性能。
5. 实验评估
在本节中,我们展示了我们的M-SFANet和M-SegNet在5个具有挑战性的人群计数数据集和1个拥堵车辆计数数据集TRANCOS[34]上的结果。我们主要使用平均绝对误差(MAE)和均方根误差(RMSE)来评估性能。指标定义如下:

其中N 是测试图像的数量。 和
表示第i 个测试图像的预测人数和真实人数。
A. ShanghaiTech 数据集
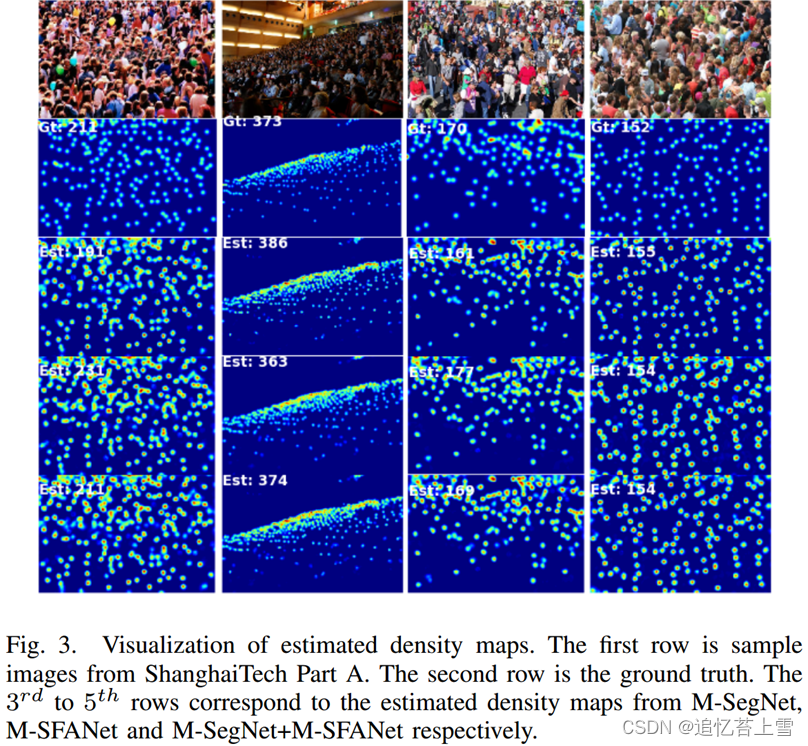
ShanghaiTech[5]数据集由1198张带标签的图像和330165名带注释的人组成。数据集分为A部分(SHA)和B部分(SHB)。SHA包含从互联网下载的482张(火车:300张,测试:182张)高度拥挤的图像。SHB包括716(火车:400,测试:316)从上海街头拍摄的相对稀疏的人群场景。表II显示了我们的模型与最先进的方法和消融研究的比较结果。与基本模型SFANet相比,M-SFANet可以将SHB的MAE降低2.03%。表明MAE/RMSE提高了1.45%/4.50%,M-SegNet在SHB方面也优于SFANet。通过M-SFANet和M-SegNet的平均预测,我们可以分别获得3.76%的MAE和8.41%的MAE对SHA和SHB的相对改进。此外,与SHA(SDCNet[20])和SHB(SANet+SPNet[39])上的最佳方法相比,M-SFANet和M-SegNet都显示出有竞争力的结果。根据表II中的消融研究,在SHA上,不含CAN的M-SFANet比不含ASPP的M-SFANet获得更高的MAE,而在SHB上则相反。实验表明,CAN和ASPP分别对拥挤场景和稀疏场景有效。随后,两个模块的集成成功地降低了SHA和SHB的MAE/RMSE。在保留从 ASPP 中提取的有用特征的同时,残差连接(skip connection)还提高了计数性能。在消融研究中,我们发现,使用贝叶斯损失[3]微调在UCF-QNRF上预训练的M-SFANet*(如第V-E节所述)是一种可行的迁移学习方法,可以实现SHB的准确计数。我们的模型在SHA上估计的密度图的可视化如图3所示。
B. UCF_CC_50 数据集
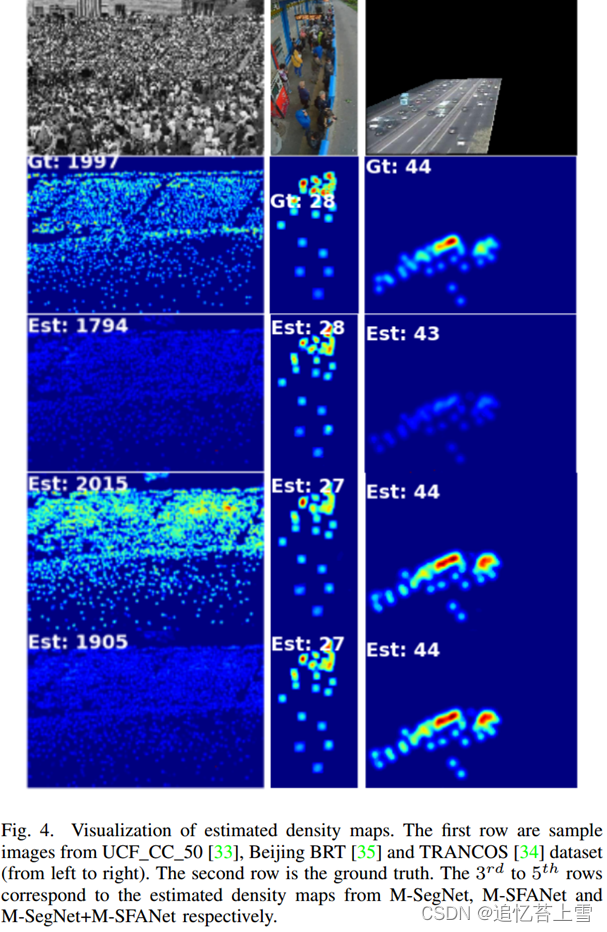
由[33]提出,数据集包含极其拥挤的场景,训练样本有限。它只包括50张高分辨率图像,头部注释数量从94到4543不等。由于训练样本数量有限,我们在ShanghaiTech Part A上对模型进行了预训练。为了评估模型性能,按照[33]中的标准设置进行5倍的交叉验证。表III列出了与最先进方法相比的结果。M-SFANet获得了具有竞争力的性能,与第二好的方法S-DCNet [20]相比。结果表明,由于所提出的两个网络在编码器和解码器结构上相似,因此集成模型并不总是产生优越的性能,训练的模型可能在多样性方面较小。该数据集的密集场景上的预测密度图的可视化如图4的左列所示。
C. WorldExpo’10数据集
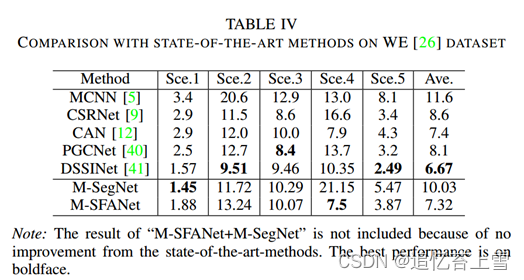
它包括从103个不同场景中收集的1132个带注释的视频序列。有3980个带注释的帧,其中3380个用于模型训练。每个场景都有一个感兴趣区域(ROI)。由于无法访问原始数据集,我们使用[36]生成的图像和密度图地面实况来训练我们的模型。在表IV中,MAE报告了每个测试场景的性能。M-SegNet和M-SFANet分别在场景1(稀疏人群)和场景4(密集人群)中获得最佳性能。
D. Beijing BRT数据集
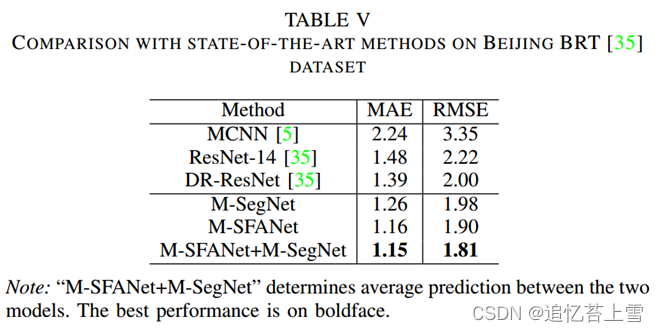
Beijing BRT数据集[35]是一个用于智能交通的人群统计数据集。磁头的数量从1到64不等。图片均为 640×360 像素,取自北京的快速公交 (BRT)。这些图像是从早到晚拍摄的,因此它们包含阴影、眩光和阳光干扰。表V报告了我们的模型在此数据集上的性能。M-SFANet+M-SegNet以17.27%/9.50%MAE/RMSE的相对改善获得了新的最佳性能。该数据集样本的估计密度图的可视化显示在图4的中间一列中。
E. UCF-QNRF数据集
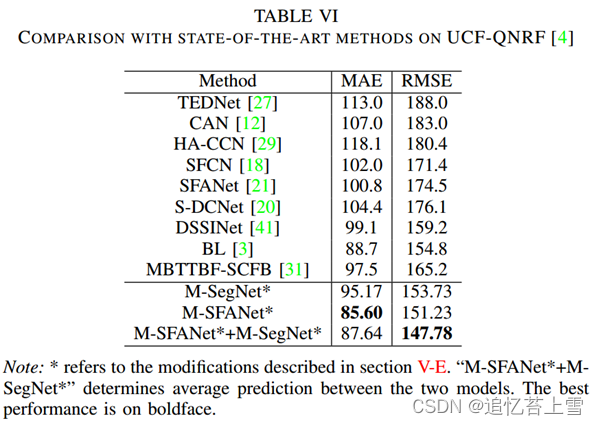
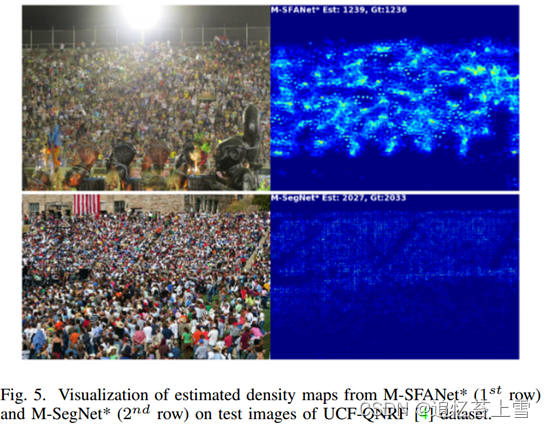
由于场景极其拥挤,UCF-QNRF[4]是一个新的具有挑战性的数据集。该数据集包含1535张高分辨率(平均2013×2902)图像(训练:1201,测试:334),带有1.25M的头部注释。除了群组计数器架构和优化器之外,我们利用了BL[3]中描述的训练方案。继VGG19[10]主干在BL中成功使用后,我们用16层VGG19替换了M-SFANet和M-SegNet的编码器,将BL解码器的输出特征图(128个通道)输入到D3块,并删除注意力图分支以降低复杂性。结果如表VI所示。从BL升级而来的M-SFANet*能够推动当前的先进性能。图5。描述了密度图的可视化。
F. TRANCOS数据集
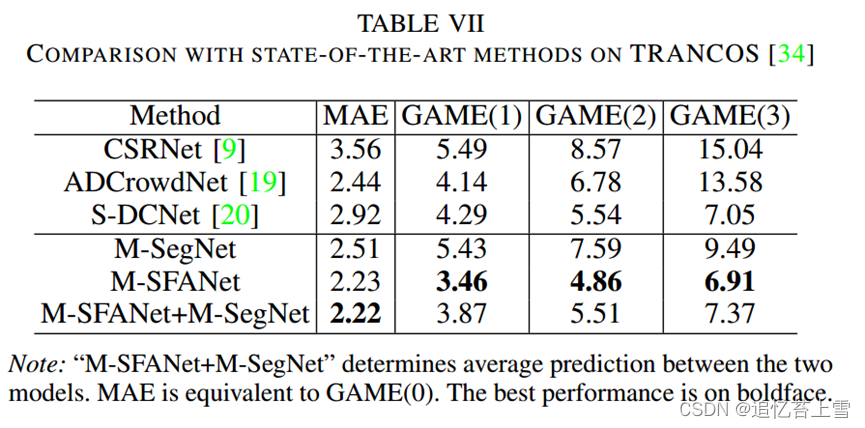
除了人群计数,我们还在车辆计数数据集TRANCOS[34]上评估我们的模型,以证明我们方法的稳健性和通用性。该数据集包含监控摄像头拍摄的1244张不同拥堵交通场景的图像。每个图像都有一个用于评估的感兴趣区域(ROI)。根据 [34] 的研究,我们使用网格平均绝对误差 (GAME) 进行模型性能评估。度量在等式5中定义。如表VII所示,我们的方法,特别是M-SFANet,超过了以前最好的方法。结果表明,平均密度图估计提高了计数精度(降低了MAE),但不能提供更好的目标对象定位。我们的模型生成的密度图如图4的右栏所示。
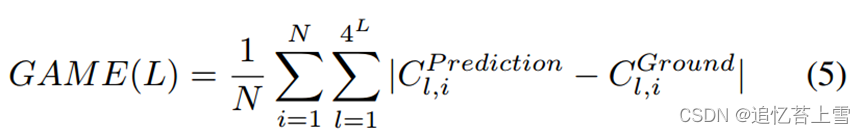
 其中N 是测试图像的数量。
其中N 是测试图像的数量。 和
是第i 个测试图像的第l 个子区域的预测计数和地面实况计数。
6. 结论
在本文中,我们结合新的架构,提出了两种改进的端到端可训练神经网络,分别命名为M-SFANet和M-SegNet,用于人群计数和图像分割。对于M-SFANet,我们将多尺度感知模块添加到SFANet架构中,以更好地处理目标对象的剧烈尺度变化。该模型缓解了现有技术方法中存在的缺点,因此在人群和车辆计数方面都表现出优异的性能。此外,M-SFANet的解码器结构被调整为具有更多的残差连接,以确保所学习的高级语义信息的多尺度特征将影响模型如何回归最终密度图。然而,尺度感知模块的采样率是不可学习的,并且这些采样率的数量在训练之前是固定的。这可能会导致在某些看不见的场景中表现有限。因此,采样率或扩展率可调的模块的自适应实现被认为是未来可能的工作。对于MSegNet,我们使用SegNet中使用的存储索引,将上采样算法从双线性改为最大非极化。这产生了更便宜的计算模型,同时提供了适用于现实世界应用程序的有竞争力的计数性能。
















 862
862











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









