







Enhanced Pix2pix Dehazing Network阅读及代码笔记
来源
CVPR2019
摘要
- 提出一个经过改进的pix2pix去雾网络(EPDN)。
- EPDN由一个生成对抗网络组成,后面跟着一个增强器。
- 受视觉感知全局优先理论的启发,鉴别器引导生成器在粗尺度上创建伪真实图像,而跟随生成器的增强器需要在精细尺度上生成真实的去模糊图像。
- 增强器包含两个基于感受野模型的增强块,这增强了在颜色和细节上的脱雾效应。
- 从知觉的角度,引入了**知觉指数(PI)**来进行定量评价。
提出的方法
本文将单一图像去雾问题转化为图像到图像的翻译任务。模糊图像和无雾图像被认为是两种不同的图像风格。EPDN网络结构如图2所示。它由一个多分辨率的生成器模块、一个增强器模块和一个多尺度的鉴别器模块组成。
类似于pix2pixHD的GAN架构被嵌入到EPDN中,然后是增强器。增强器包含两个设计好的增强块,每个增强块都是根据接受域模型构建的,并采用镜头切割法来保持原始图像的颜色信息。

多分辨率的生成器
GAN模块的多分辨率生成器,由全局生成器G1和局部生成器G2组成,如图2所示。G1和G2都包括前端的卷积块、三个残差块和后端的逆卷积块。G1的输入是从原始的模糊图像中降采样2×。G1嵌入到G2中,将G1的输出和G2的前端卷积得到的特征图的和输入到残差块中。全局生成器以粗比例创建图像,而局部生成器以精细比例创建图像。
多尺度的判别器
该模块包含两个尺度的鉴别器D1和D2,D1和D2具有相同的架构,D2的输入是从D1的输入降采样2×。多尺度鉴别器可以引导生成器从粗到细。一方面,D2引导生成器在粗尺度上生成全局伪真实图像。另一方面,D1以良好的比例引导生成器。
增强器
尽管pix2pixHD利用了从粗到细的特性,仅从pix2pixHD获得的结果仍然缺乏细节,并且过色。一个可能的原因是,现有的鉴别器在指导生成器创建现实的细节方面是有限的。换句话说,鉴别器应该仅仅指示生成器恢复结构模拟,而不是细节。
为了有效地解决这一问题,我们实现了一个金字塔池化模块,以确保在最终结果中嵌入了来自不同尺度的特征的细节。我们将它命名为增强块。金字塔池化模块如图3所示。
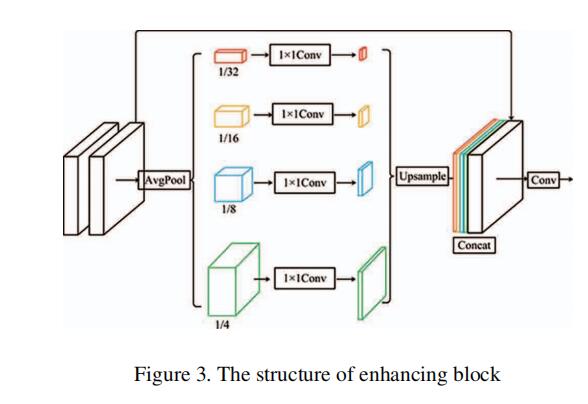
在增强块中有两个3×3的卷积层。将卷积层的输出进行4×、8×、16×、32×的降采样,建立一个四尺度金字塔。不同尺度上的特征图提供了不同的感受域,有助于重建不同尺度上的图像。然后1×1卷积进行降维。实际上,1×1卷积意味着自适应加权通道的注意力机制。之后,我们将特征映射上采样到原始大小,并将它们与前端卷积层的输出连接在一起。最后,在特征映射的连接上实现了3×3卷积。
在EPDN中,增强器包括两个增强块。此外,第一增强块由原始图像和生成器的特征映射连接提供,这些特征映射也输入第二增强块。
损失函数
为了优化EPDN,利用了四个损失函数:**对抗性损失LA、特征匹配损失LFM、感知损失LVGG,以及保真度损失LF。**利用对抗性损失和特征匹配损失,使GAN模块学习全局信息,恢复原始图像结构。
LA是GAN的损失函数;为了制作真实的图像,采用基于鉴别器的特征匹配损失LFM来提高对抗性损失;为了保持感知和语义的保真度,我们使用感知损失函数LVGG来测量模糊图像与其对应的去模糊图像之间的高级差异;将模糊图像X与最终输出Yˆ之间的欧氏距离视为保真度损失LF。
代码
残差块
使用残差块是为了减弱网络的梯度消失,可以使网络更深,更平滑,使训练更深的神经网络成为了可能。残差的思想简单来说就是一个公式:out = layer(input) + input。它使得网络在层数加深之后至少能退化到输入,不会显得太糟糕。
class ResnetBlock(nn.Module):
def __init__(self, dim, padding_type, norm_layer, activation=nn.ReLU(True), use_dropout=False):
super(ResnetBlock, self).__init__()
self.conv_block = self.build_conv_block(dim, padding_type, norm_layer, activation, use_dropout)
def build_conv_block(self, dim, padding_type, norm_layer, activation, use_dropout):
conv_block = []
p = 0
if padding_type == 'reflect':
conv_block += [nn.ReflectionPad2d(1)]
elif padding_type == 'replicate':
conv_block += [nn.ReplicationPad2d(1)]
elif padding_type == 'zero':
p = 1
else:
raise NotImplementedError('padding [%s] is not implemented' % padding_type)
conv_block += [nn.Conv2d(dim, dim, kernel_size=3, padding=p),
norm_layer(dim),
activation]
if use_dropout:
conv_block += [nn.Dropout(0.5)]
p = 0
if padding_type == 'reflect':
conv_block += [nn.ReflectionPad2d(1)]
elif padding_type == 'replicate':
conv_block += [nn.ReplicationPad2d(1)]
elif padding_type == 'zero':
p = 1
else:
raise NotImplementedError('padding [%s] is not implemented' % padding_type)
conv_block += [nn.Conv2d(dim, dim, kernel_size=3, padding=p),
norm_layer(dim)]
return nn.Sequential(*conv_block)
def forward(self, x):
out = x + self.conv_block(x) # 残差学习
return out
全局生成器G1
在全局生成器,通过卷积做了四次下采样,后面接着三个残差块,然后又通过反卷积进行了四次上采样。
class GlobalGenerator(nn.Module):
def __init__(self, input_nc, output_nc, ngf=64, n_downsampling=3, n_blocks=9, norm_layer=nn.BatchNorm2d,
padding_type='reflect'): # n_blocks 残差块的数量 n_downsampling 下采样数量,以上仅为默认值,值的输入在base—options
assert(n_blocks >= 0)
super(GlobalGenerator, self).__init__()
activation = nn.ReLU(True)
model = [nn.ReflectionPad2d(3), nn.Conv2d(input_nc, ngf, kernel_size=7, padding=0), norm_layer(ngf), activation]
### downsample 下采样
for i in range(n_downsampling):
mult = 2**i
model += [nn.Conv2d(ngf * mult, ngf * mult * 2, kernel_size=3, stride=2, padding=1),
norm_layer(ngf * mult * 2), activation]
### resnet blocks
mult = 2**n_downsampling
for i in range(n_blocks):
model += [ResnetBlock(ngf * mult, padding_type=padding_type, activation=activation, norm_layer=norm_layer)]
### upsample 上采样
for i in range(n_downsampling):
mult = 2**(n_downsampling - i)
model += [nn.ConvTranspose2d(ngf * mult, int(ngf * mult / 2), kernel_size=3, stride=2, padding=1, output_padding=1),
norm_layer(int(ngf * mult / 2)), activation]
model += [nn.ReflectionPad2d(3), nn.Conv2d(ngf, output_nc, kernel_size=7, padding=0), nn.Tanh()]
self.model = nn.Sequential(*model)
def forward(self, input):
return self.model(input)
增强器—金字塔池化模块(PPM)
金字塔池化模块(Pyramid Pooling Module,PPM)出自论文《Pyramid Scene Parsing Network》,也就是PSPNet。它可以聚合不同区域的上下文信息,提高网络获取全局信息的能力。在现有深度网络方法中,一个操作的感受野直接决定了这个操作可以获得多少上下文信息,所以提升感受野可以为网络引入更多的上下文信息。金字塔池化模块结构图如前文上图所示,步骤总结如下:
- 走过卷积层
- 采用四种尺寸的池化操作得到不同的特征图
- 对四个特征图进行1 * 1的卷积,并进行下采样
- 最后进行特征图的拼接
具体代码如下:
class Dehaze(nn.Module):
def __init__(self):
super(Dehaze, self).__init__()
self.relu=nn.LeakyReLU(0.2, inplace=True)
self.tanh=nn.Tanh()
self.refine1= nn.Conv2d(6, 20, kernel_size=3,stride=1,padding=1)
self.refine2= nn.Conv2d(20, 20, kernel_size=3,stride=1,padding=1)
self.conv1010 = nn.Conv2d(20, 1, kernel_size=1,stride=1,padding=0) # 1mm
self.conv1020 = nn.Conv2d(20, 1, kernel_size=1,stride=1,padding=0) # 1mm
self.conv1030 = nn.Conv2d(20, 1, kernel_size=1,stride=1,padding=0) # 1mm
self.conv1040 = nn.Conv2d(20, 1, kernel_size=1,stride=1,padding=0) # 1mm
self.refine3= nn.Conv2d(20+4, 3, kernel_size=3,stride=1,padding=1)
self.upsample = F.upsample_nearest
self.batch1 = nn.InstanceNorm2d(100, affine=True)
def forward(self, x):
dehaze = self.relu((self.refine1(x)))
dehaze = self.relu((self.refine2(dehaze)))
shape_out = dehaze.data.size()
# print(shape_out)
shape_out = shape_out[2:4]
x101 = F.avg_pool2d(dehaze, 32)
x102 = F.avg_pool2d(dehaze, 16)
x103 = F.avg_pool2d(dehaze, 8)
x104 = F.avg_pool2d(dehaze, 4)
x1010 = self.upsample(self.relu(self.conv1010(x101)),size=shape_out)
x1020 = self.upsample(self.relu(self.conv1020(x102)),size=shape_out)
x1030 = self.upsample(self.relu(self.conv1030(x103)),size=shape_out)
x1040 = self.upsample(self.relu(self.conv1040(x104)),size=shape_out)
dehaze = torch.cat((x1010, x1020, x1030, x1040, dehaze), 1)
dehaze= self.tanh(self.refine3(dehaze))
return dehaze
局部生成器G2
在局部生成器中G1被嵌入到其中,将G1的输出和G2的卷积得到的特征图的元素和,输入G2的残差块。最后局部生成器的结果被输入到增强器中,进行了两次增强。
在EPDN中,增强器(金字塔池化)包括两个增强块。此外,第一增强块由原始图像和生成器的特征映射连接提供,这些特征映射也输入第二增强块。
如下:
tmp=torch.cat((output_prev,input), 1)
dehaze=self.dehaze(tmp)
tmp=torch.cat((output_prev,dehaze),1)
dehaze=self.dehaze2(tmp)
return output_prev,dehaze
整个局部生成器的代码G2:
class LocalEnhancer(nn.Module):
def __init__(self, input_nc, output_nc, ngf=32, n_downsample_global=3, n_blocks_global=9,
n_local_enhancers=1, n_blocks_local=3, norm_layer=nn.InstanceNorm2d, padding_type='reflect'):
super(LocalEnhancer, self).__init__()
self.n_local_enhancers = n_local_enhancers
###### global generator model #####
ngf_global = ngf * (2**n_local_enhancers)
model_global = GlobalGenerator(input_nc, output_nc, ngf_global, n_downsample_global, n_blocks_global, norm_layer).model
model_global = [model_global[i] for i in range(len(model_global)-3)] # get rid of final convolution layers
self.model = nn.Sequential(*model_global)
###### local enhancer layers #####
for n in range(1, n_local_enhancers+1):
### downsample
ngf_global = ngf * (2**(n_local_enhancers-n))
model_downsample = [nn.ReflectionPad2d(3), nn.Conv2d(input_nc, ngf_global, kernel_size=7, padding=0),
norm_layer(ngf_global), nn.ReLU(True),
nn.Conv2d(ngf_global, ngf_global * 2, kernel_size=3, stride=2, padding=1),
norm_layer(ngf_global * 2), nn.ReLU(True)]
### residual blocks
model_upsample = []
for i in range(n_blocks_local):
model_upsample += [ResnetBlock(ngf_global * 2, padding_type=padding_type, norm_layer=norm_layer)]
### upsample
model_upsample += [nn.ConvTranspose2d(ngf_global * 2, ngf_global, kernel_size=3, stride=2, padding=1, output_padding=1),
norm_layer(ngf_global), nn.ReLU(True)]
### final convolution
if n == n_local_enhancers:
model_upsample += [nn.ReflectionPad2d(3), nn.Conv2d(ngf, output_nc, kernel_size=7, padding=0), nn.Tanh()]
setattr(self, 'model'+str(n)+'_1', nn.Sequential(*model_downsample))
setattr(self, 'model'+str(n)+'_2', nn.Sequential(*model_upsample))
self.downsample = nn.AvgPool2d(3, stride=2, padding=[1, 1], count_include_pad=False)
self.dehaze=Dehaze()
self.dehaze2=Dehaze()
def forward(self, input):
### create input pyramid
input_downsampled = [input]
for i in range(self.n_local_enhancers):
input_downsampled.append(self.downsample(input_downsampled[-1]))
### output at coarest level
output_prev = self.model(input_downsampled[-1])
### build up one layer at a time
for n_local_enhancers in range(1, self.n_local_enhancers+1):
model_downsample = getattr(self, 'model'+str(n_local_enhancers)+'_1')
model_upsample = getattr(self, 'model'+str(n_local_enhancers)+'_2')
input_i = input_downsampled[self.n_local_enhancers-n_local_enhancers]
output_prev = model_upsample(model_downsample(input_i) + output_prev)
tmp=torch.cat((output_prev,input), 1)
dehaze=self.dehaze(tmp)
tmp=torch.cat((output_prev,dehaze),1)
dehaze=self.dehaze2(tmp)
return output_prev,dehaze
多尺度的判别器
该模块包含两个尺度的鉴别器D1和D2,D1和D2具有相同的架构,D2的输入是从D1的输入降采样2×。多尺度鉴别器可以引导生成器从粗到细。一方面,D2引导生成器在粗尺度上生成全局伪真实图像。另一方面,D1以良好的比例引导生成器。
class MultiscaleDiscriminator(nn.Module):
def __init__(self, input_nc, ndf=64, n_layers=3, norm_layer=nn.BatchNorm2d,
use_sigmoid=False, num_D=3, getIntermFeat=False):
super(MultiscaleDiscriminator, self).__init__()
self.num_D = num_D
self.n_layers = n_layers
self.getIntermFeat = getIntermFeat
for i in range(num_D):
netD = NLayerDiscriminator(input_nc, ndf, n_layers, norm_layer, use_sigmoid, getIntermFeat)
if getIntermFeat:
for j in range(n_layers+2):
setattr(self, 'scale'+str(i)+'_layer'+str(j), getattr(netD, 'model'+str(j)))
else:
setattr(self, 'layer'+str(i), netD.model)
self.downsample = nn.AvgPool2d(3, stride=2, padding=[1, 1], count_include_pad=False)
def singleD_forward(self, model, input):
if self.getIntermFeat:
result = [input]
for i in range(len(model)):
result.append(model[i](result[-1]))
return result[1:]
else:
return [model(input)]
下面这个是PatchGAN,组成了多尺度的判别器。
class NLayerDiscriminator(nn.Module):
def __init__(self, input_nc, ndf=64, n_layers=3, norm_layer=nn.BatchNorm2d, use_sigmoid=False, getIntermFeat=False):
super(NLayerDiscriminator, self).__init__()
self.getIntermFeat = getIntermFeat
self.n_layers = n_layers
kw = 4
padw = int(np.ceil((kw-1.0)/2))
sequence = [[nn.Conv2d(input_nc, ndf, kernel_size=kw, stride=2, padding=padw), nn.LeakyReLU(0.2, True)]]
nf = ndf
for n in range(1, n_layers):
nf_prev = nf
nf = min(nf * 2, 512)
sequence += [[
nn.Conv2d(nf_prev, nf, kernel_size=kw, stride=2, padding=padw),
norm_layer(nf), nn.LeakyReLU(0.2, True)
]]
nf_prev = nf
nf = min(nf * 2, 512)
sequence += [[
nn.Conv2d(nf_prev, nf, kernel_size=kw, stride=1, padding=padw),
norm_layer(nf),
nn.LeakyReLU(0.2, True)
]]
sequence += [[nn.Conv2d(nf, 1, kernel_size=kw, stride=1, padding=padw)]]
if use_sigmoid:
sequence += [[nn.Sigmoid()]]
if getIntermFeat:
for n in range(len(sequence)):
setattr(self, 'model'+str(n), nn.Sequential(*sequence[n]))
else:
sequence_stream = []
for n in range(len(sequence)):
sequence_stream += sequence[n]
self.model = nn.Sequential(*sequence_stream)
def forward(self, input):
if self.getIntermFeat:
res = [input]
for n in range(self.n_layers+2):
model = getattr(self, 'model'+str(n))
res.append(model(res[-1]))
return res[1:]
else:
return self.model(input)

















 1751
1751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









