






最近自动驾驶落地成了大家关心的话题,而场景变成落地的前提,自动泊车或者自主泊车就是近期看到的落地场景最多的,下面就聊聊这个场景都用了什么技术。
推荐一篇综述文章:“The Future of Parking: A Survey on Automated Valet Parking with an Outlook on High Density Parking“。
这里引用它的一个框图:
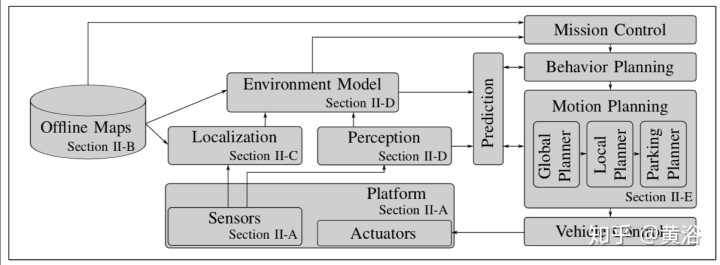
是不是有一种“麻雀虽小,五脏俱全”的感觉?所以在泊车这个场景可以是L2-L3-L4都能落地的:)。
传感器方面,基本的是超声波雷达,但这种雷达只能在停车位边上经过才能检测出是否可以停车,而且它也无法确定停车位的倾斜度。摄像头通过图像可以检测识别停车位,甚至可以建视觉泊车场地图,应该是升级的配置。
激光雷达当然可以做超声波雷达和摄像头的工作,成本贵就是了。另外,V2X也会使停车场管理容易,但这需要铺设基础设施,不是车厂的工作。
摄像头做泊车的一般是环视摄像头,鱼眼镜头,放在车的侧身和前后Bumper。其原理是基于摄像头标定得到的镜头内外参数,通过Homography变换,将图像投射到路面,形成360度环视拼接。
注意,这个拼接和我们看到的VR360度环视拼接不一样,那个是拼接在一个中心的柱面(上下俯仰角度小于60度)或者球面。当然这种路面拼接质量差,在拼接处容易出现畸变,特别是运动物体,有“鬼影”效应。
不久前,某某XXX公司发布新车在顶上放了一个环视摄像头,有些记者胡写说是用来做泊车的,怎么可能?周围地面死角那么多。
就看它那个机械旋转的装置,标定都不好做,停车位定位比较困难。据说就是给驾驶员提供一个360度视角的,有多大用途就看以后开发出什么应用吧。
这是一个环视鱼眼镜头的拼接例子:

环视系统标定和一般摄像头类似,也是做标定平面板,比如:

停车位检测识别基本就是一个典型的图像识别问题,见如下的框图为例:

在室内/地下停车场,有时候柱子的信息也可以用。
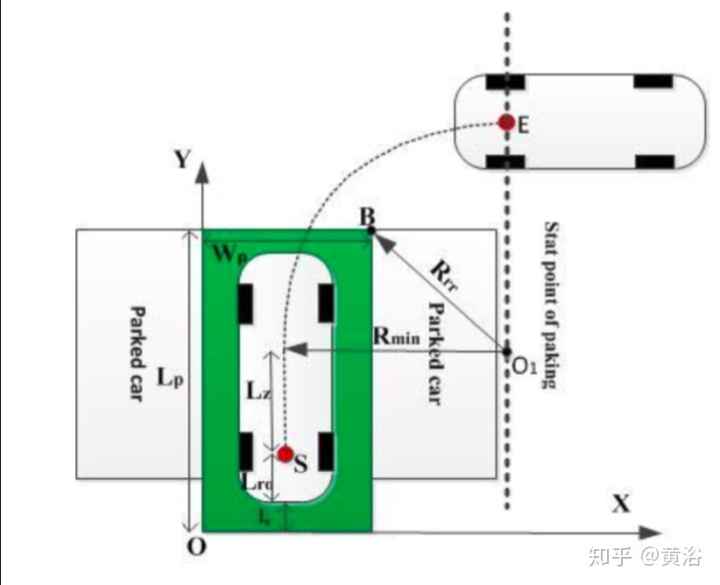
一旦停车位确定,车辆通过定位到了它附近,就可以用运动规划完成泊车动作,比如下面就是一个平行和垂直泊车的轨迹规划的例子:

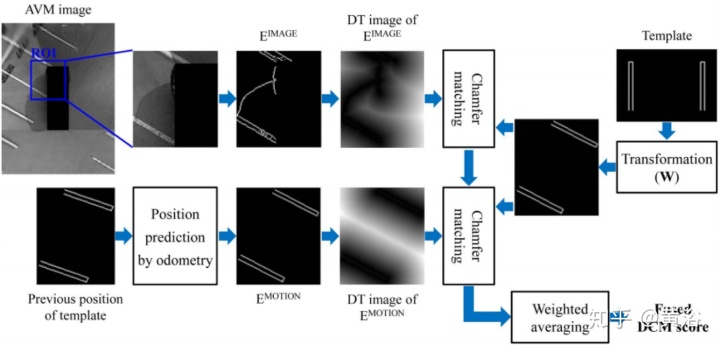
没有摄像头的图像信息的话,只能通过motion sensor-based odometry来控制轨迹误差。有摄像头的话,两个信息可以融合。如下图给出一个跟踪停车线的传感器融合方案:
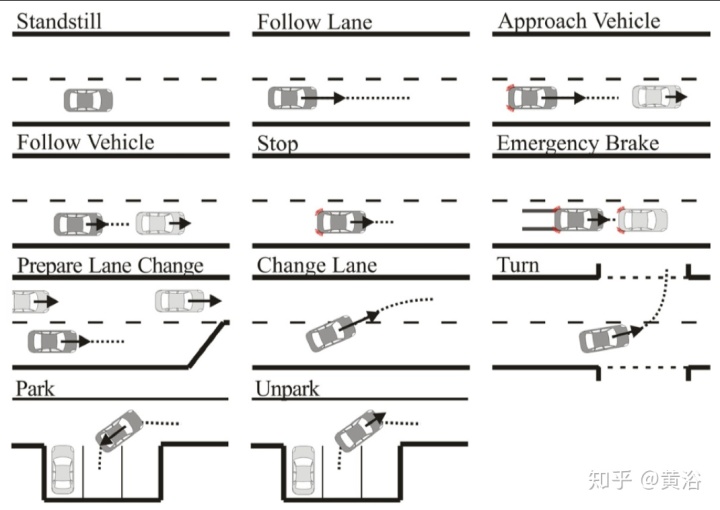
自主泊车(valet parking)是要有地图的,可以实现所谓的“一键停车”。同时,行为规划模型也会多样,比如下图的例子:
谈到自主泊车,就不得不提到欧盟项目V-Charge,这是它的传感器配置:

这个项目基本就是停车场的自动驾驶系统开发,这是建立的一个视觉地图例子(颜色随高度而变):

前向的双目视觉可以检测障碍物(特别是行人):

上面的介绍主要是一些论文讨论过的泊车方法,现有的一些高档车都有这类功能。目前一些自动驾驶公司也推出了跟车企合作的泊车解决方案,看演示和传感器配置,基本方法就这些,区别在于L2,L3还是L4级别。















 2750
2750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









