







 本文提出一种视频抠像框架,通过跨注意力机制传播trimap并利用时空特征聚合模块提高前后景分割效果。
本文提出一种视频抠像框架,通过跨注意力机制传播trimap并利用时空特征聚合模块提高前后景分割效果。
Deep Video Matting via Spatio-Temporal Alignment and Aggregation
目录
Deep Video Matting via Spatio-Temporal Alignment and Aggregation
Real-World High-Resolution Videos
(4)Spatial-Temporal Feature Aggregation Module(ST-FAM)
Temporal Feature Alignment module (TFA)
Temporal Feature Fusion module (TFF)
1. Title
Deep Video Matting via Spatio-Temporal Alignment and Aggregation
2. Summary
本文提出了一个用于解决Video Matting问题的Framework。
Trimap Propagation Network可以从参考帧的Trimap标注传播至其他目标帧中,初步获取粗糙的Trimap,从而大大降低了对密集标注Trimap的要求,传播的机制主要是基于Cross-Attention而完成。
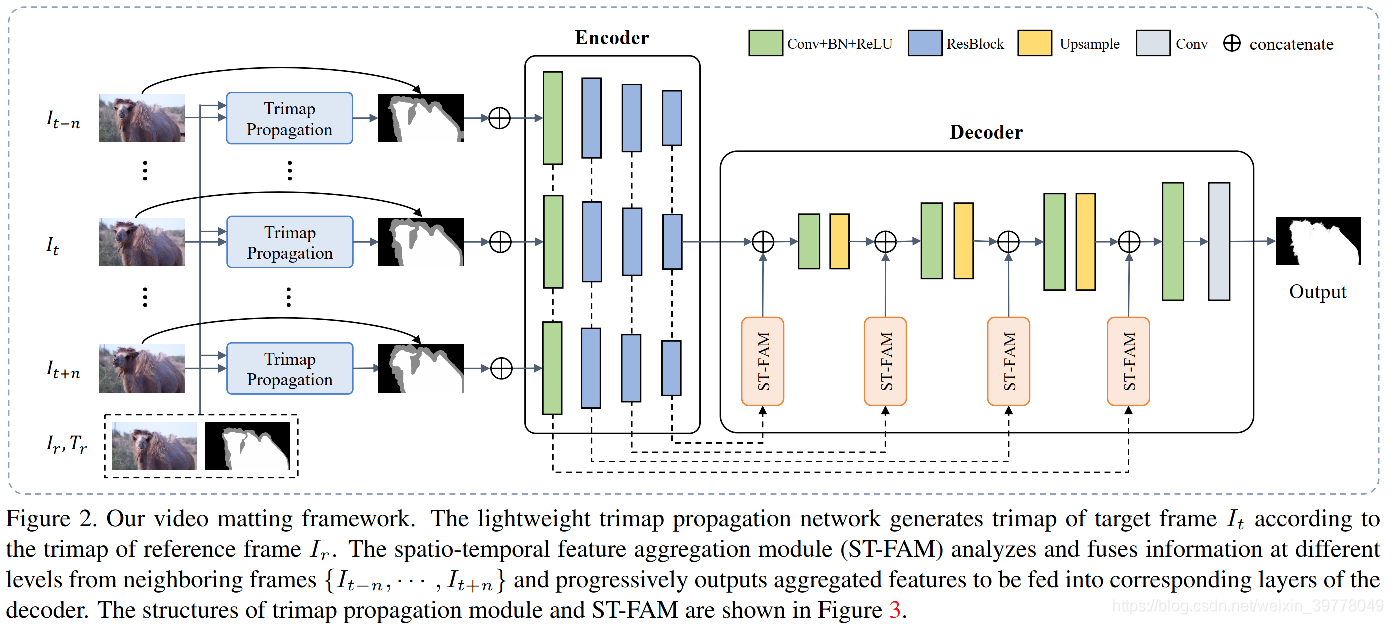
网络整体架构是UNet架构,但输入是来自于多个帧的特征及其有Trimap Propagation Network生成的粗糙的Trimap,同时在Skip-Connection部分采用了Spatial-Temporal Feature Aggregation Module(ST-FAM)对其进行增强。
Spatial-Temporal Feature Aggregation Module(ST-FAM)核心思想是利用目标帧和相邻帧的特征产生一个offset,并送入Deformable Conv中进行对齐,从而获取时域信息。
3. Problem Statement
本文要解决的问题领域是Video Matting。
(1)Matting问题定义
图像分割就是将图片中的像素分成多个类别,如果是前背景分割,那么就是分成两个类别,一个类别代表前景,一个类别代表背景,这类问题我们也称之为硬分割(Hard Segmentation)。
Matting也是一类前背景分割问题,但是matting不是硬分割,而是软分割(Soft Segmentation),像玻璃、头发这类前景,对应像素点的颜色不只是由前景本身的颜色决定,而是前背景颜色融合的结果,matting问题的目标就是,找出前背景颜色F和,以及它们之间的融合程度α。(参考链接)
![]()
(2)Video Matting难点
尽管深度学习在Natural Image Matting任务中取得了巨大的进展,但是目前在Video Matting领域缺乏一些代表性的工作,原因在于:
-
Video Matting需要保持Spatial和Temporal的一致性,简单在帧间独立使用Image Matting会在移动的细节部分带来跳动,光流估计可以一定程度上缓解跳动问题,但是对于复杂的matting场景,目前的光流估计算法无法对半透明区域获得一个可信的估计结果。
-
由于Video Matting需要大量密集标注的Tripmap,因此目前缺乏大规模的Video Matting数据集。
4. Method(s)
为了解决上述问题,本文提出了一个创新的并且同时高效的Spatial-Temporal Feature Aggregation Module(ST-FAM),考虑到时耗以及准确性,该模块并没有使用光流估计模块,而是在Decoder部分通过对齐和聚合来自不同Spatial Scale和Temporal Frames来高效获取时序信息。
本文还提出了一个轻量级的Interactive Trimap Propagation Network以避免对逐帧标注的Trimap的需求。
最后本文还开源了一个大型Video Matting数据集,该数据集包含groundtruth alpha mattes用于定量评估,以及包含trimap的高分辨率真实世界video,用于定性评估。
(1)Datasets
Composited Dataset
由真实的前景视频以及对应的groundtruth alpha mattes和包含自然和真实生活场景的背景视频组成。
- 前景目标来自于图片和视频两个部分。
视频前景目标主要是来自于互联网中的绿屏视频,由于其背景较为干净、简单,因此使用软件即可获得较好的前景和alpha mattes。
图片前景目标主要来自于Adobe Deep Matting Dataset。
同一目标的相似图片被丢弃,最终得到了325个images作为训练Sample,50个images作为测试Sample。
- 背景则包含了大量真实世界视频。
从互联网上收集了6500个视频,其包含了自然风景、城市风光以及室内场景等。
- 前背景融合
根据Matting问题的定义公式,将前景和背景视频进行融合,并且使用随机平移、连续性平移、旋转、放缩等增强方法对前景目标进行增强。
最终基于325 images和75个视频以及随机挑选的16个背景视频,得到了6400((325+75)* 16 = 6400)个视频作为训练集,测试集则由50 images和12个视频以及随机挑选的4个背景视频,得到248个测试样例。
Real-World High-Resolution Videos
额外提供了10个4K分辨率的真实世界的视频,并相应提供了其精细和粗糙的密集Trimap标注。
(2)Trimap Propagation
Trimap Propagation方法主要是基于参考帧和目标帧之间的Region Similarity Measures。
- 使用两个具有相同结构的Encoder去分别去提取参考帧的Image-Trimap Pair {Ir, Tr}和目标帧image的语义特征Fr、Ft。
- 为了扩大感受野并且克服不同的移动变化、尺度变化等问题,使用了一个基于Cross-Attention的Correlation Layer对参考帧和目标帧进行匹配,具体可参考下图:
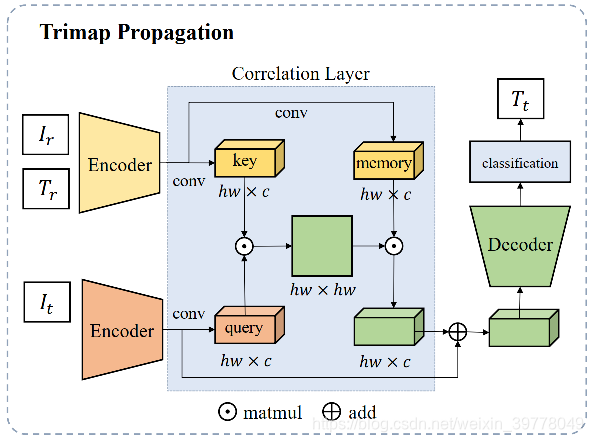
最终分类头会将增强后的特征图进行分类,分为前景、背景以及未知区域三个类别。

(3)Encoder-Decoder Network
为目标帧生成粗糙的Trimap后,然后使用一个自编码器结构去提取多个Image-Trimap Pairs的特征。
Encoder用于提取其low-level structural features和high-level semantic features,这些特征将送入Decoder中用于生成Alpha Mattes。
Decoder部分的上采样模块采用的是Sub-pixel Convolution Layer,以提升精度和效率。
整体结构为UNet结构,但与标准UNet结构不同的是,在skip-connection部分采用Spatial-Temporal Feature Aggregation Module(ST-FAM)进行了增强。
(4)Spatial-Temporal Feature Aggregation Module(ST-FAM)
ST-FAM则是为了提升alpha mattes在时序上的一致性。ST-FAM包括两个模块:Temporal Feature Alignment module (TFA)以及Temporal Feature Fusion module (TFF),整体结构见下图:
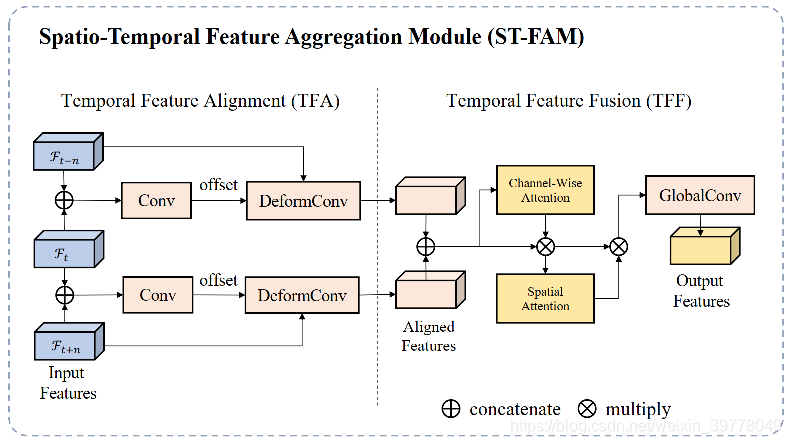
Temporal Feature Alignment module (TFA)
通过将相邻帧特征与目标帧之间进行对齐,来获取Motion信息。具体而言,通过结合相邻帧与目标帧特征,学习得到一个offset,并将offset应用至DeformConv中,以完成相邻帧和目标帧特征之间的对齐。
Temporal Feature Fusion module (TFF)
对齐后的特征,再通过级联的Channel-Wise Attention和Spatial Attention进行进一步增强,最终通过一个Global Conv输出时域增强后的特征。
(5)Loss Functions
多种损失用于提供丰富的监督信号。
- Alpha Loss
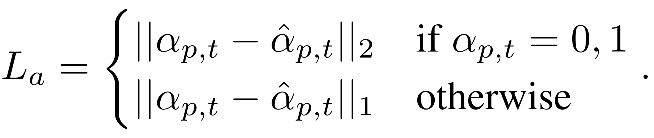
- Composition Loss
![]()
- Gradient Loss
![]()
- KL-Divergence Loss
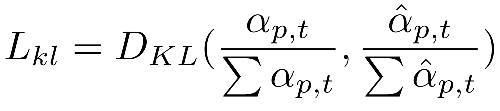
- Temporal Coherence Loss
![]()
- Total loss
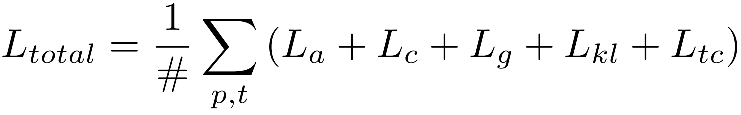
5. Evaluation
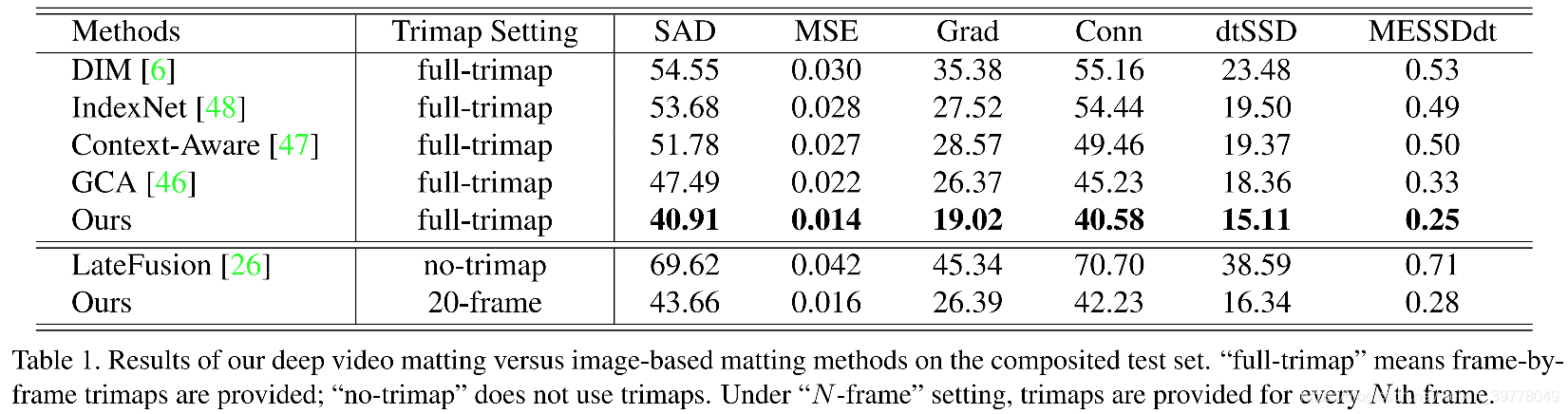
本文采用了四种常用评估指标:the sum of absolute differences (SAD), mean square error (MSE), the gradient error (Grad) and the connectivity error (Conn)。
dtSSD and MESSDdt 两个指标用于评估时序一致性:
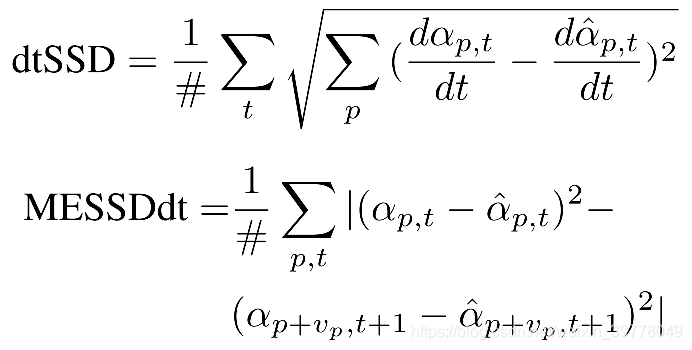
(1)数据集实验指标

(2)消融实验

6. Conclusion
本文提出了一种可以挖掘相邻帧之间时域信息的Video Matting Framework。

















 1387
1387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









