








Project Page: https://prompt-to-prompt.github.io
Paper: https://arxiv.org/abs/2208.01626
Code: https://github.com/google/prompt-to-prompt
文章目录
1. Introduction
基于文本的图像生成方案特别吸引人类,因为人类习惯于口头表达他们的意图。因此,将基于文本的图像生成扩展到基于文本的图像编辑是顺理成章的。
然而,编辑对于生成模型来说是一个挑战。因为编辑技术的固有需求是保留原始图像的大部分内容,而文本提示的微调改动往往就会导致基于文本的生成模型产生完全不同的结果。
目前的SOTA方案通过要求用户额外提供一个Mask用于定位编辑区域来避免该问题,然而,该方案忽略了在Mask区域的原始结构和内容。
本文期望使用一种直观的Prompt-to-Prompt的方式来完成编辑任务,即仅通过文本来控制编辑。为此,本文深入分析了基于文本的图像生成模型,并观察到Cross-Attention是控制图像空间布局与文本提示中各个单词之间关系的关键。
基于以上观察,本文提出在扩散过程中注入交叉注意力图的方式来编辑图像,从而控制哪些像素在哪些扩散步骤中关注提示文本的哪些标记。
具体而言,本文提出了几种仅通过编辑文本提示来控制图像生成的方案:
- 替换单词进行局部编辑:替换一个单一的token的值(例如将“dog”替换为“cat”),同时固定Cross-Attention Maps,从而保持场景的整体结构。
- 添加限定进行全局编辑:在Prompt中加入新的限定描述,冻结其他tokens的Attention Maps,运行新的tokens的Attention计算。
- 精细控制单词在图像中反映程度:放大或者减弱生成图像中单词的语义效果。
部分示例图如下所示:

2. Method

从上图不难看出,简单固定随机种子,使用新的Prompt进行生成,难以维持相关结构的不变,而如果加上对于Attention Maps的固定的话,则可以在一定程度上维持相关结构的不变性。
2.1 Cross-attention in text-conditioned Diffusion Models
本文使用Imagen作为backbone。Imagen本是是一个多阶段模型,其首先在64x64分辨率上训练一个base text-to-image diffusion model,然后再结合超分模型,将分辨率逐步进行提升:64x64 -> 256x256 -> 1024x1024。
由于图像的组成和几何结构主要是在64x64分辨率下确定,因此,这里只需要调整base text-to-image diffusion model即可,超分模型可以直接复用Imagen原超分模型。
下图上半部展示了Text to Image Cross-Attention的过程:
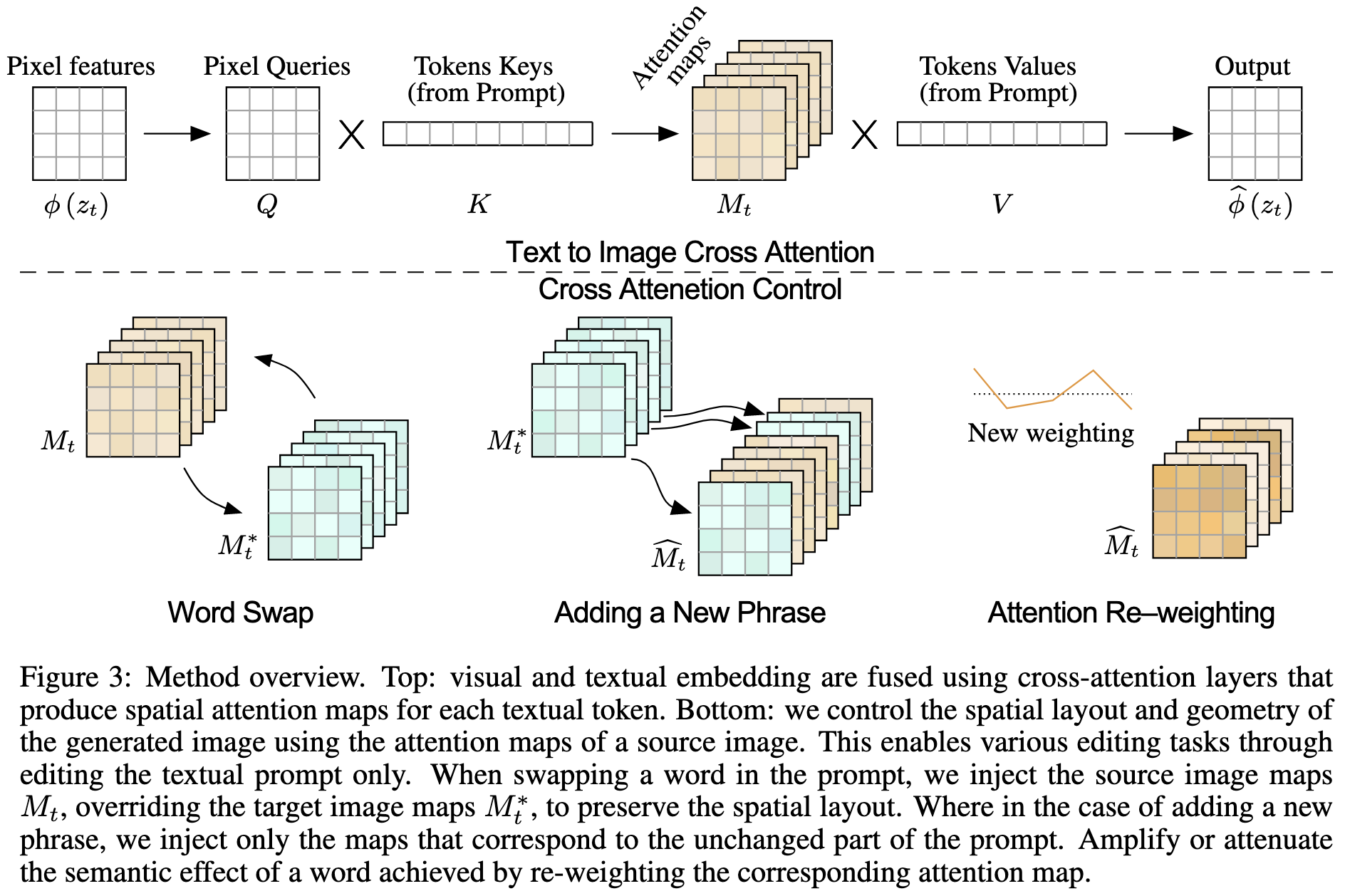
2.2 Controlling the Cross-attention
下图展示了像素和文本之间的交互过程:
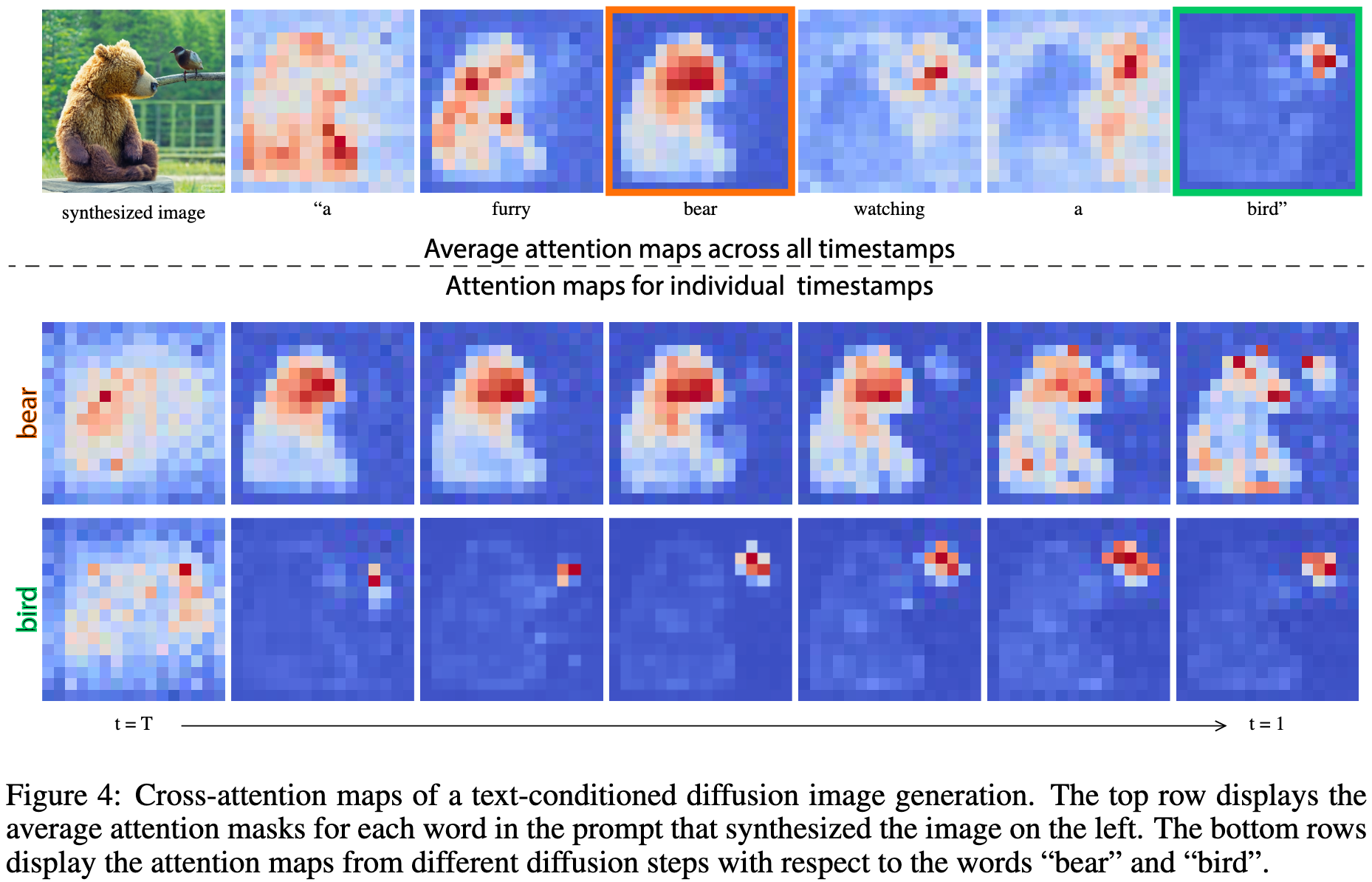
从上图可以看出,像素对描述它们的词语更具有“吸引力”,例如bear的像素和词语bear相关联。
由于注意力图反映了整体组成,因此,可以将从原始提示 P P P生成的注意力图 M M M注入到使用修改后提示 P ∗ P^* P∗的第二次生成中。这不仅可以让合成的新图像 I ∗ I^* I∗可以根据编辑的提示进行修改,还能保持输入图像 I I I的结构。
下图展示了Prompt-to-Prompt图像编辑算法流程:

其中, D M ( z t ∗ , P ∗ , t , s t ) { M ← M ^ t } D M\left(z_t^*, \mathcal{P}^*, t, s_t\right)\left\{M \leftarrow \widehat{M}_t\right\} DM(zt∗,P∗,t,st){M←M t}表示一个Diffusion Step,其中,使用 M ^ t \widehat{M}_t M t改写 M M M的同时,保持来自提供Prompt的 V V V不变。
接下来,具体解释一下不同编辑操作下 E d i t ( M t , M t ∗ , t ) Edit \left(M_t, M_t^*, t\right) Edit(Mt,Mt∗,t)的含义。
- Word Swap
在该编辑任务中,用户将原来的Prompt中的tokens替换为其他的tokens,例如 P = "a big red bicyle" P=\text{"a big red bicyle"} P="a big red bicyle"到 P ∗ = "a big red car" P^*=\text{"a big red car"} P∗="a big red car"。
该任务的主要难点在于如何在保持原始结构的同时还需要处理新提示的内容,本文解决该问题的方案是,将原图像的注意力图注入到修改后的提示的图像生成过程中。
然而,注入的注意力图可能会对生成图像的结构约束过高,特别是当需要进行一个大的结构改动时,例如“car”改为”bicycle”。
为了缓解该问题,本文使用了一个softer attention constrain:
Edit
(
M
t
,
M
t
∗
,
t
)
:
=
{
M
t
∗
if
t
<
τ
M
t
otherwise
\begin{equation} \operatorname{Edit}\left(M_t, M_t^*, t\right):= \begin{cases}M_t^* & \text { if } t<\tau \\ M_t & \text { otherwise }\end{cases} \end{equation}
Edit(Mt,Mt∗,t):={Mt∗Mt if t<τ otherwise
其中,
τ
\tau
τ是一个timestep参数,其决定注入操作的截止时间。
需要注意的是,生成图像的结构主要是在扩散过程的早期时间步中确定。因此,通过限制注入操作时间步的数量,本文可以引导新生成的图像的结构,同时允许必要的几何自由度,以适应新的提示。

还有一些其他的策略来缓解该问题,例如对于不同的tokens设置不同的注入timestep。
当更改前后两个单词对应的tokens数不一致时,对应的maps需要进行复制/平均操作。
- Adding a New Phrase
在该编辑任务中,用户会在原来Prompt的基础上增加新的tokens,例如 P = "a castle next to a river" P=\text{"a castle next to a river"} P="a castle next to a river"到 P ∗ = "children drawing of a castle next to a river" P^*=\text{"children drawing of a castle next to a river"} P∗="children drawing of a castle next to a river"。
为了保持基本的细节不变,本文仅在两个prompts的基本tokens中进行Attention的注入。
具体来说,本文会引入一个Alignment Function A A A,其输入为目标Prompt P ∗ P^* P∗的token index,如果其与Prompt P P P 中某个token匹配的话,则输出该匹配的token的index,否则就输出None。
基于Alignment Function
A
A
A,该任务的Edit Function定义如下:
(
E
d
i
t
(
M
t
,
M
t
∗
,
t
)
)
i
,
j
:
=
{
(
M
t
∗
)
i
,
j
if
A
(
j
)
=
None
(
M
t
)
i
,
A
(
j
)
otherwise.
\begin{equation} \left(Edit\left(M_t, M_t^*, t\right)\right)_{i, j}:= \begin{cases}\left(M_t^*\right)_{i, j} & \text { if } A(j)=\text { None } \\ \left(M_t\right)_{i, A(j)} & \text { otherwise. }\end{cases} \end{equation}
(Edit(Mt,Mt∗,t))i,j:={(Mt∗)i,j(Mt)i,A(j) if A(j)= None otherwise.
这里的index
i
i
i表示pixel value的索引,而
j
j
j是Text token的索引。
和Word Swap任务类似,这里也可以设置一个timestep参数 τ \tau τ来控制注入的timestep。
该编辑任务可以实现风格化、修改物体的属性或者是一个全局的改动。

- Attention Re-weighting
用户可能期望增强或削弱某些tokens对于最终图像的影响程度,例如, P = "a fluffy red ball" P=\text{"a fluffy red ball"} P="a fluffy red ball",假设我们期望使得这个ball更加或者更少fluffy。
为了实现这种编辑,本文对对应token
j
∗
j^*
j∗的Attention Map进行放缩,放缩参数为
c
∈
[
−
2
,
2
]
c \in[-2,2]
c∈[−2,2],从而得到更强或者更弱的效果,剩余的Attention Maps保持不变:
(
E
d
i
t
(
M
t
,
M
t
∗
,
t
)
)
i
,
j
:
=
{
c
⋅
(
M
t
)
i
,
j
if
j
=
j
∗
(
M
t
)
i
,
j
otherwise
.
\begin{equation} \left(Edit\left(M_t, M_t^*, t\right)\right)_{i, j}:= \begin{cases}c \cdot\left(M_t\right)_{i, j} & \text { if } j=j^* \\ \left(M_t\right)_{i, j} & \text { otherwise } .\end{cases} \end{equation}
(Edit(Mt,Mt∗,t))i,j:={c⋅(Mt)i,j(Mt)i,j if j=j∗ otherwise .

- Real Image Editing
编辑真实的图像需要找到一个初始的噪声向量,它在被输入到扩散过程中后可以生成给定的输入图像,该过程被称为inversion。
一个简单的inversion方式就是在原图上加入高斯噪声,然后执行预定义数目的扩散过程。该方式会导致显著的变形,因此,本文使用了一个优化后的inversion方式,其基于一个确定性的DDIM模型,而不是DDPM模型。本文反向执行扩散过程,即 x 0 ⟶ x T x_0 \longrightarrow x_T x0⟶xT,而不是 x T ⟶ x 0 x_T \longrightarrow x_0 xT⟶x0,其中 x 0 x_0 x0设置为给定的真实图像。
在大部分情况下,这种inversion方式可以取得不错的效果:

但在部分场景下,其可能也会失败:

其部分原因在于编辑可塑性和失真之间的Trade-off,本文发现降低cfg参数(即减少Prompt的作用)可以改善重构的表现,但这同时也限制了对于较大编辑改动的实现。
为了缓解上述问题,本文提出使用一个Mask来还原未编辑的区域,该Mask直接从Attention Maps中提取:

3. Summary
这篇论文介绍了一种名为 Prompt-to-Prompt Image Editing with Cross Attention Control 的新方法,它允许用户仅通过修改文本提示来编辑图像。主要内容包括:
-
问题背景:
- 大型文本驱动的合成模型(如 Imagen、DALL·E 2 和 Parti)能够根据文本提示生成多样化的图像,但这些模型在进行图像编辑时面临挑战,因为即使是文本提示的微小变化也可能导致完全不同的输出图像。
- 现有的方法通常需要用户提供空间掩码来定位编辑区域,这不仅操作繁琐,而且忽略了掩码区域内的原始结构和内容。
-
方法提出:
- 作者提出了一种直观的 Prompt-to-Prompt 编辑框架,通过控制文本提示来实现图像编辑。这种方法利用了文本条件模型中的 交叉注意力层,这些层是控制图像空间布局与文本提示中每个单词之间关系的关键。
- 通过在扩散过程中注入交叉注意力图,可以控制哪些像素在哪些扩散步骤中关注文本提示中的哪些标记,从而实现对图像的编辑。
-
编辑应用:
- 单词替换(Word Swap):在保持场景构图的同时,通过替换文本提示中的单词来实现局部编辑。
- 全局编辑(Global Editing):通过添加新单词到文本提示并冻结对先前标记的注意力,同时允许新的注意力流向新标记,来实现全局风格或属性的编辑。
- 语义效果的放大或减弱(Attention Re-weighting):通过调整特定单词在生成图像中的语义影响程度来精细控制图像。
-
实验结果:
- 通过在多样化的图像和提示上进行实验,论文证明了所提出方法的高质量合成能力和对编辑提示的忠实度。
- 实验包括了在真实图像上的应用,展示了使用现有反转过程进行编辑的可能性。
-
局限性与未来工作:
- 尽管展示了通过文本提示进行图像编辑的能力,但当前方法在反转过程中可能导致失真,且无法在图像中移动对象。
- 未来的工作将探索提高反转准确性、引入高分辨率交叉注意力层以及提供更细粒度的编辑控制等方向。
总的来说,这篇论文为文本驱动的图像编辑提供了一种新的视角,通过深入理解和利用交叉注意力层,实现了一种直观且强大的图像编辑方法。

















 184
184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









